
上一篇我們介紹了 asm.js 架構的說明,這裡我們直接來看以實際的程式所測試出來的標竿分析(benchmarking)。
標竿分析(Benchmarking)
標竿分析(benchmarking)是一個棘手的問題,在實際的問題中有很多應用程式可以用來做標竿分析,但是因為我們的瀏覽器環境有許多限制,像是有限制的網路環境、儲存空間、顯示卡語音效裝置等等,所以我們這裡只選擇一些比較單純的程式來測試。
首先,我們測試 Whetstone、Dhrystone 與 LINPACK 這三個程式。
Whetstone 是一個浮點運算的標竿分析,它早在 1972 年就已經出現的,這個標竿分析當時是英國國家物理實驗室(National Physical Laboratory)用來測量科學計算程式用的,裡面包含一些簡單的運算:數值陣列的加法與減法、三角函數、指數函數與平方根。
Dhrystone 是在 1984 年發展出來的標竿分析(這個名字是參考 Whetstone 來的),其測試的範圍包含現今一般程式會使用的整數運算、函數呼叫、字串處理與陣列存取等。
Dhrystone 常用的版本有兩個,一個是舊的 1.x 系列,另外一個是 1988 年之後發展的 2.x 系列版本。Dhrystone 2.x 是設計用來跟 1.x 版比較用的,在 2.x 版本中其程式碼特別經過設計,可以避免讓編譯器做一些最佳化的動作,在函數呼叫上,Dhrystone 2.x 特別將原始程式碼分成不同的檔案,以避免 C 編譯器在做最佳化時,自動把耗時的函數呼叫改為內崁的方式。
但是這樣的作法在 1988 年那個時候也不是很有效,甚至到現在這樣的方式已經完全沒有作用了,現在的編譯器很聰明,縱使你的程式碼分成好幾個檔案,它還是有辦法做最佳化。在這樣的狀況下,我們有兩種選擇,一種是在程式碼中加入適當的 pessimizations 讓編譯器不要做最佳化,另外一種則是明確告知大家編譯器會做的最佳化有哪些,在這裡我們選擇使用 Dhrystone 1.x 的程式並且也讓大家知道編譯器會做很多最佳化的動作,這樣的測試方式在比較不同的機器時可能會有問題,但若只是單純要看不同編譯器之間的差異時,是沒有影響的。
Dhrystone 與 Whetstone 這兩個程式都是比較老舊的標竿分析程式,所以在某些方面會有些限制,像在比較新的電腦硬體上,它會將所有的資料都放進快取(cache)中計算,這樣一來就無法測試處理器與記憶體之間資料傳輸的效能,但縱使如此,這些標竿分析程式還是有一定的用處。例如他的程式很小就是一個優點,這樣可以讓它在很多低階的處理器上面執行,尤其是一些嵌入式的系統。
原始的 LINPACK 標竿分析程式是另一個浮點數運算測試程式(可以追溯到 1979 年),但與 Dhrystone 與 Whetstone 不同的是,LINPACK 的計算是比較有意義的,它是用於解線性方程式以及計算一些跟數值矩陣相關的問題。另外 LINPACK 也被擴充至現今的系統上,其矩陣的大小可以比以前更大,在 Top500 上的超級電腦也常常使用 LINPACK 作為評比的標準,而在超級電腦中常用的 HPL 也是根據 LINPACK 發展而來的。
這三種標竿分析程式在網路上都有寫好的 C 語言版本,我們使用 Roy Longbottom 的版本,然後稍微修改一下,讓它們可以在我們的電腦中編譯,並且拿掉一些不必要的 I/O 與牽涉到低階硬體的部份。
這三種測試基本上都試圖表達「每秒的執行效能」,LINPACK 的輸出是 FLOPS(floating point operations per second),而 Dhrystone 是輸出 VAX MIPS,這是用於 DEC VAX 11/780 這種舊電腦的效能衡量標準,VAX 11/780 表示機器可以達到一個 MIPS(million of instructions per second),這樣的速度可以每秒執行 Dhrystone 這個程式 1757 次,而在 Dhrystone 測試上得到兩個 VAX MIPS 指的就是這個系統在執行 Dhrystone 這個程式的效能比 VAX 11/780 快上兩倍。Whetstone 所使用的衡量標準為 WIPS(Whetstone Instructions Per Second),它的概念也是類似這樣。
接著我們使用 STREAM 這個記憶體頻寬標竿分析(memory bandwidth benchmark),雖然這種測試不應該直接用於 JavaScript 引擎,但是它應該可以讓我們了解使用大記憶體陣列與直接使用一般記憶體之間的差異。其測試的內容包含四個:記憶體陣列的複製、讀取與搬移,以及經過一些計算之後寫入輸出的結果,而他的輸出則會有四個分數分別對應四種不同的測試,單位為 MB/s(megabytes per second)。
在這四種標竿分析測試中,較高的分數代表較好的效能。
近代的標竿分析
其餘的標竿分析是來自於 Computer Language Benchmarks Game,這些標竿分析會針對同一個問題提供各種語言版本的測試程序,有些是來自於真正的問題,例如使用常規表示法(regular expression)來比對 DNA 序列,而外一些則只是單純測試用的程式,沒有實際的用途。每個人都可以傳送各式各樣的程式碼上去,有些測試程式還同時包含一般的版本與依照平台最佳化之後的版本。
基本上在測試每個問題時,會以最受歡迎的純 C++ 語言的實作為主,而版本的話會排除 SSE 函數,因為這些函數會使用 explicit multithreading,而使用 OpenMP 的 implicit multithreading 部份則還是可以使用,因為我們在執行時可以直接關閉 OpenMP 的功能,讓它變成單一執行序的程式。
我們並沒有使用 Benchmarks Game 上面所有的測試程式,其中 chamenos-redux 與 threadring 這兩個是 explicit multithreading 的方式,而 k-nucleotide 則是只有 multithread 版本,像這些都無法在瀏覽器中使用。
排除那些無法使用的,我們選用的測試程式有:fasta、reverse-complement 與 regex-dna 這三個,然後用這三個測試程式組合成一個完整的效能測試,fasta 測試程式是用於產生 FASTA 檔案格式的 隨機 DNA 序列(pseudo-random DNA sequences),reverse-complement 測試程式是用於讀取 DNA 序列並輸出它的反向對偶(reverse complement),而 regex-dna 測試程式則是用於搜尋 DNA 序列的特定的特徵(pattern)。
原本的 Benchmark Game 測試中是使用 fasta 產生一個輸出檔案,再使用 reverse-complement 與 regex-dna 以重新導向(redirecting)的方式讀取這個檔案,但是這樣的測試方式無法在瀏覽器中使用,所以這裡我們稍微修改一下,首先我們將三個測試程式合併為一個大的程式,並將這個大程式命名為 fasta-combo,接著將重新導向的方式改為讀取單一檔案。
除了這三個測試之外,我們也選用了 binary-trees(建立與移除二元樹資料結構)、fannkuch-redux(產生一連串的數值並根據某些規則排序)、mandelbrot(產生一個曼德博集合的碎形點陣圖)、meteor-contest(計算拼圖可組裝的方式)、n-body(模擬類木行星的運行軌道)與 spectral-norm(計算無限矩陣的最大特徵值的平方根),這些測試的測量都是以它們的執行時間為準,也就是說量測出來較低的數值代表較高的執行效能。
為了方便測試這些程式的效能,我們將每個程式加入記錄與顯示執行時間的功能,這部分的修改純粹只是為了方便性的考量,無關測試的精準度。雖然 UNIX 系統中有一些很方便的工具可以測量執行時間,但是在 Windows 中就沒有這樣的工具,使用這樣「入侵性」的時間測量會導致測量結果低估真正的執行時間,就原生程式而言,這樣的方式會沒辦法測量到初始化的部分,而 asm.js 則是會無法測量到 asm.js 的編譯時間,但我們感覺以這樣的微小誤差換來在各種平台上的測量方便性是很值得的。
最後要強調的是,這些標竿分析測試並不能代表所有程式的執行狀況,使用這些測試程式也不見得是最好的測試方式,你甚至可以改寫這些程式,改善它們的效能,讓整個測試結果翻盤。基本上這些測試結果只是告訴你這些程式執行的結果如何,不代表你拿你自己的程式放上來跑之後也會有同樣的結果,因為每個程式都不同,要想知道自己的程式的執行效能,只能自己測試,這是一般人看這種標竿分析常有的盲點。
從 GitHub 下載
這裡的測試程式(可以從 GitHub 網站上面下載)是使用 Clang 3.2 與 Emscripten incoming@1ed2d7f 來產生一般的 JavaScript 與 asm.js JavaScript,而原生程式則是使用 Visual Studio 2012 來編譯,加上基本的最佳化(包含自動向量化),為了保持某些程式碼的相容性,我們使用 November CTP preview 版本的編譯器,這不會影響到最佳化的功能,但它可以讓一些測試程式中的 C++ 功能正常運作。對於 Emscripten 而言,它只能使用 Clang 的編譯器,而原生程式選用 Visual Studio 的原因是因為它是 Windows 標準的編譯器一支,而且也很普遍,通常編譯出來的程式也比較不會有問題,而在 Windows 中的 Clang 編譯器目前也還在發展當中,所以無法使用。
在本篇測試報告撰寫的時候,asm.js 編譯器只有在 Firefox Nightly builds 版本中可以使用,最後我們在 64 位元的 Window 8 上使用 Nightly 2013-05-07 這個版本來測試,另外也測試了 32 位元的 Internet Explorer 10.0.4。
Emscripten 可以輸出單獨的 JavaScript 檔案,這種 JavaScript 檔案適用於 node.js(Chrome 的 V8 引擎)或 jsshell(Firefox 的 JavaScript 引擎)這類的環境,或者也可以輸出內崁 JavaScript 的 HTML 檔案,這樣的 HTML 輸出檔案還可以提供額外的一些功能,例如 Canvas 與 WebGL 等,在大部分的狀況中我們會使用 HTML 檔案的方式來測試,因為我們還要與 Internet Explorer 比較。
我們也測試過各種版本的 Chrome 瀏覽器(stable、dev 與 canary branches),但是都無法測完所有的程式,大部分的原因是因為記憶體的因素,若要讓所有的測試程式都可以執行,必須指定 512MB 的大型陣列(asm.js 中陣列的長度必須是 2 的整數次方),在 Internet Explorer 中它會使用 aplomb 來處理,但是在 Chrome 中則會無法執行,而 Firefox 在大部分的狀況下是正常的,但偶爾會出現 out-of-memory 的錯誤,需要重新啓動。
至於測試時所使用的的硬體規格,CPU 是 3.4GHz 的 Intel Sandy Bridge Xeon E3-1275(3.8GHz turbo),記憶體為 1333MHz 的 16GB 記憶體。
基本測試結果
講了那麼多,接下來就來看實際的測試結果,首先是基本的測試。
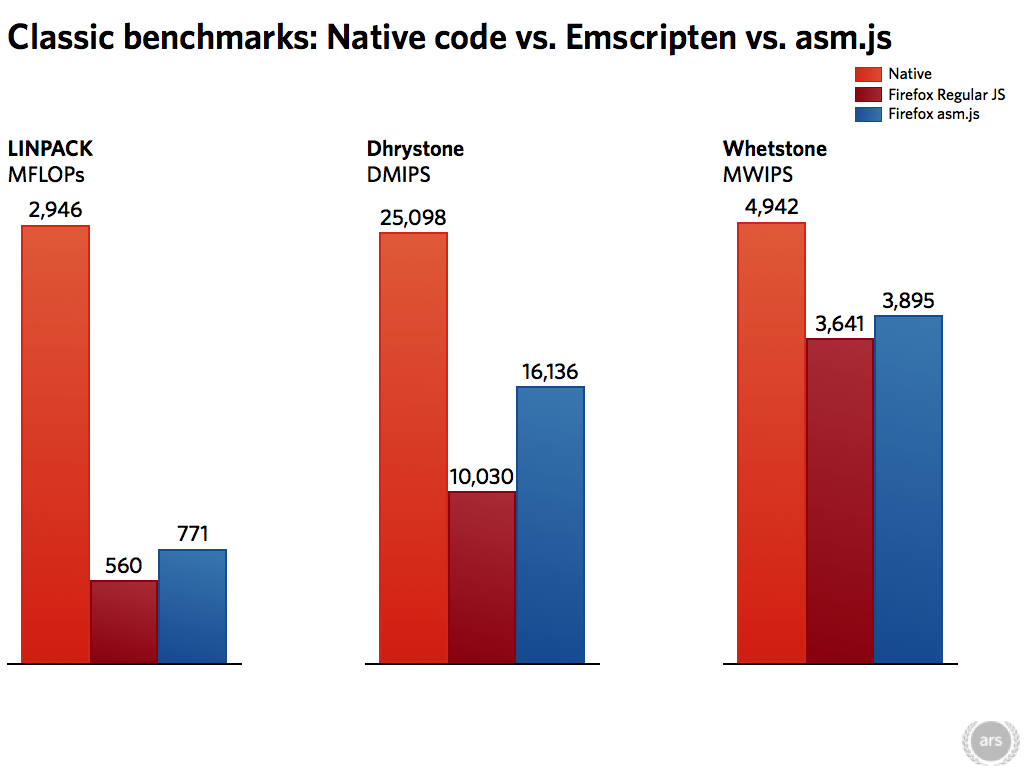
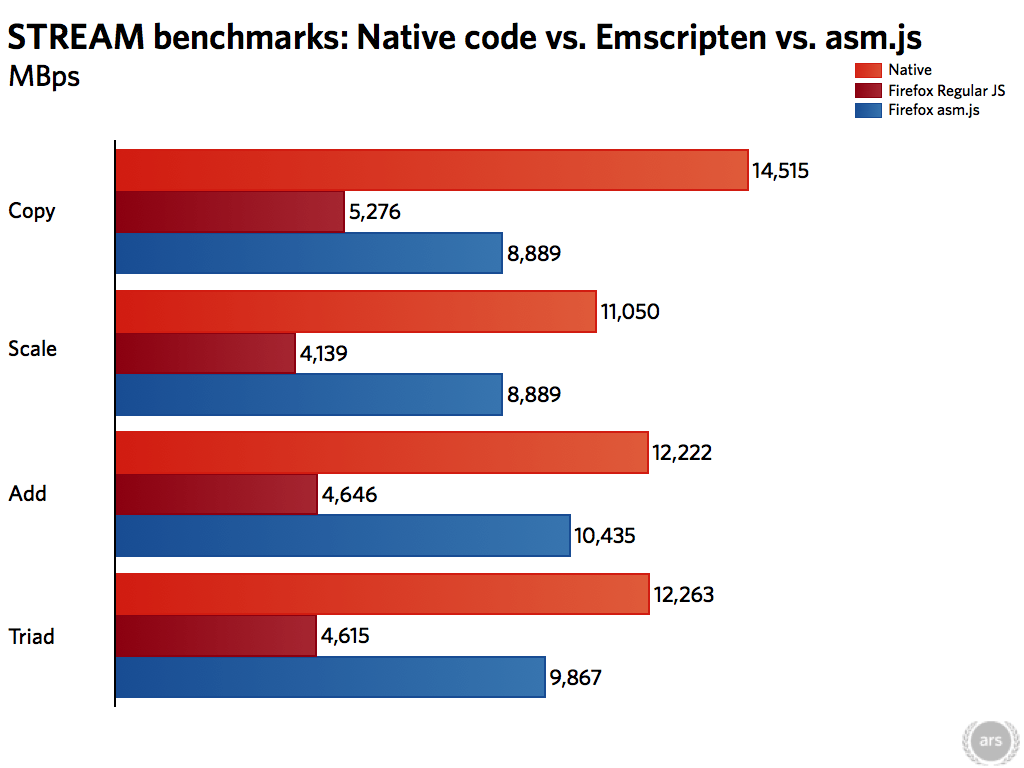
基本的測試中,一般的 JavaScript 平均可以到達原生程式 40% 的效能,而 asm.js 則有 68%,這樣的結果對於比較在意效能的人,縱使以比較好的 asm.js 效能來說,可能只是可以接受的標準而已,稱不上很好。
STREAM 的測試結果比較理想,asm.js 在這裡明顯比一般的 JavaScript 要好,尤其是在 Scale、Add 與 Triad 這幾個測試中,這也可以看出 asm.js 在讀取陣列中的資料時,拿掉檢查與轉換的動作對於其效能的影響很大。
LINPACK 與 Whetstone 這兩個浮點運算比較多的測試,其結果就比較差,Whetstone 使用 asm.js 僅僅只增加了 7% 的效能,LINPACK 則好一些,增加了 38%,但是比起其他幾個測試還是不太好。
以 Whetstone 的結果來說,有人可能會認為這是 Firefox 的 JavaScript 引擎本來在浮點數的運算效能上就已經不錯了,所以要再加速很困難,但是由 LINPACK 測試的結果可以看出來,事實不是這樣,這是所有測試裡面最糟糕的一個,執行速度只有原生程式的 26%。
接著來看 Benchmark Game 的測試結果。

在傳統 JavaScript 的表現上實在不怎麼理想,其平均執行時間是原生程式的 4.2 倍,而 asm.js 的效能在這裡卻顯得格外突出,其平均執行時間只比原生程式多出 64%,不到傳統 JavaScript 執行時間的 40%,其中大部分的情況已經可以達到實際應用所需要的執行效能了。
在 asm.js 的測試中,mandelbrot 是很明顯的拖油瓶,它花費的時間是原生程式的 3.9 倍,基本上從表面上很難看出為什麼它會那麼慢,其所用的到運算包含檔案 I/O、浮點運算與位元運算,而這些運算在其餘的測試中也都有做,但是也沒這麼慢。屏除 mandelbrot 不看的話,asm.js 平均只比原生程式慢 26%。
整體而言,在單一執行序的這些基本程式上,asm.js 架構的效能算是可圈可點。
繼續閱讀:asm.js 架構與 Emscripten 編譯器 – Mozilla 在網頁上發展出接近原生(Native)程式效能的 JavaScript 程式(三)