
這裡介紹如何使用 Google 雲端硬碟的文字辨識功能,自動辨識照片裡的直書與橫書中文字,不用打字就可以複製出圖片中的文字。
最近我在整理大量的老舊中文書籍,打算把這些古書全部轉成電子檔,讓資料可以永久保存,甚至建立資料庫,方便搜尋關鍵字。
古書數位化的第一步當然就是以掃描器掃描成 PDF 檔保存,而有了大量的照片之後,接下來就要想辦法把裡面的文字辨識出來,建立資料庫。下面這一張是典型的範例圖片,由於這樣的圖片有非常多,所以一定要找一個可以自動化處理的方式才行。

Google 雲端硬碟文字辨識功能
市面上的圖片文字辨識(OCR)軟體其實不少,以往最有名的應該就是丹青文件辨識系統,而後來也出現很多免費的軟體,我在網路上研究了一陣子,覺得 Google 雲端硬碟的文字辨識功能好像做得比較好,辨識準確率高,操作也方便,以下是使用 Google 雲端硬碟辨識中文圖片文字的步驟。
Step 1
首先把圖片的方向調整好,如果照片的方向是側的或是反的,就用 Windows 10 內建的相片瀏覽程式來調整。

將圖片轉正之後,才能開始進行文字的辨識。

Step 2
將要進行文字辨識的照片上傳至 Google 雲端硬碟,直接選取要上傳的照片,滑鼠拖曳進 Google 雲端硬碟的目錄即可自動上傳。
Step 3
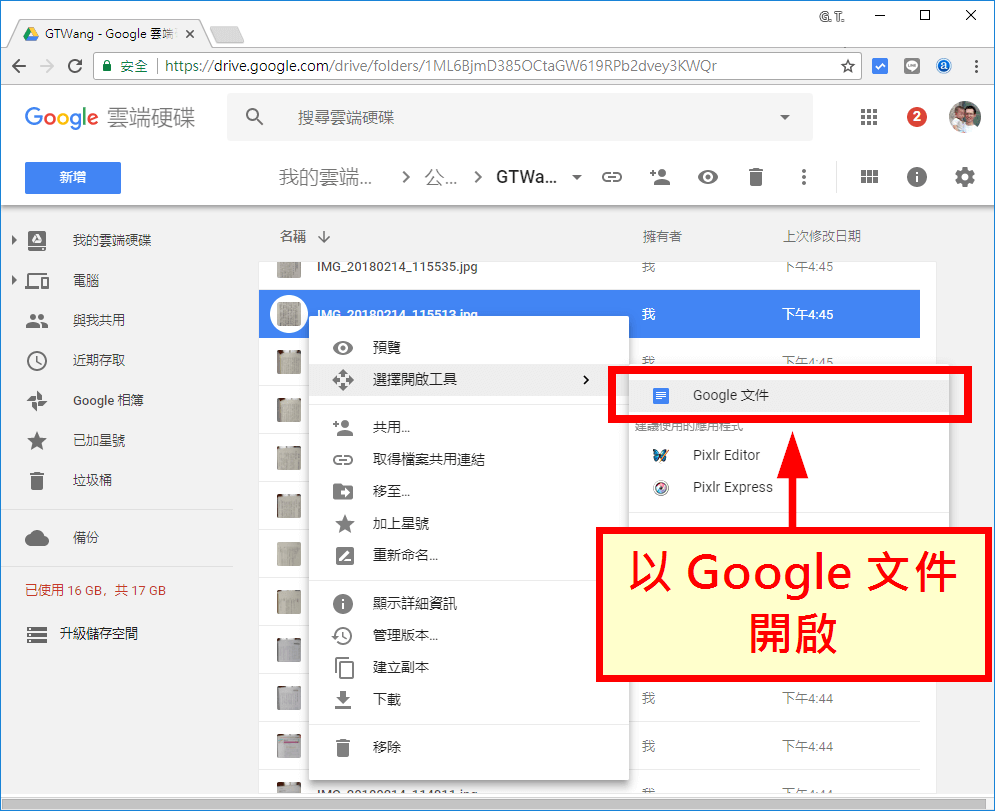
等照片上傳至 Google 雲端硬碟之後,使用 Google 文件開啟圖片。
Step 4
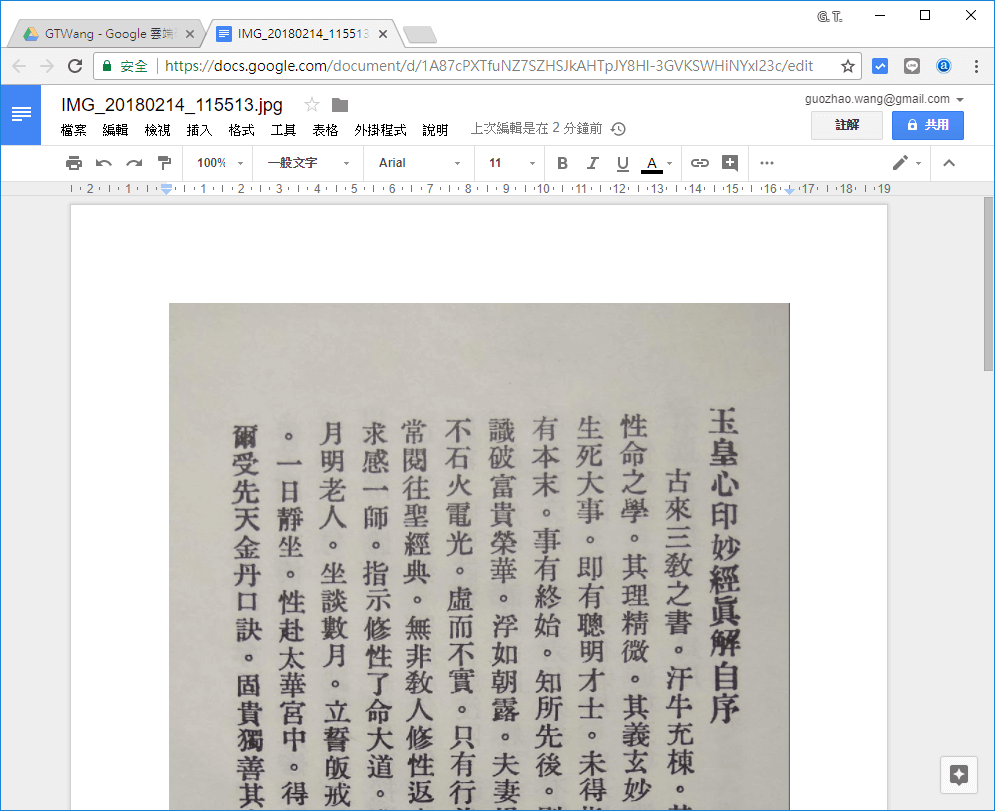
以 Google 文件開啟圖片之後,文件開頭會顯示該圖片。
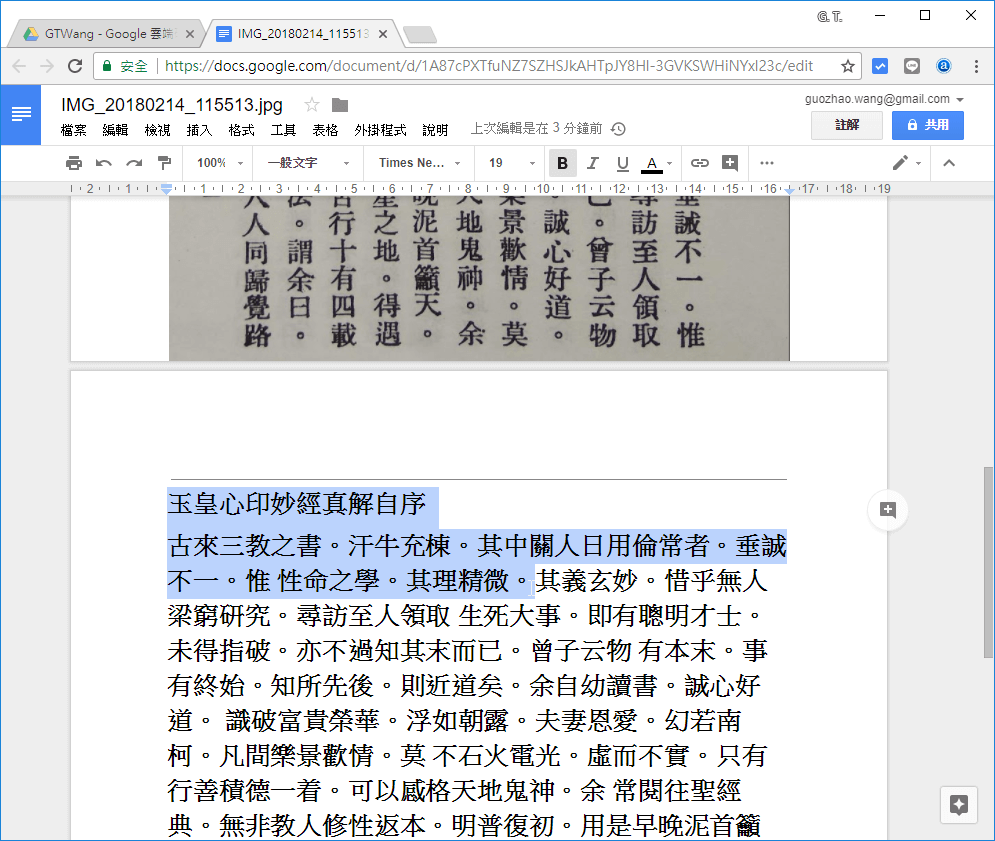
在圖片的下方就會有自動辨識文字的結果,Google 雲端硬碟的文字辨識功能很不錯,它會自動判斷中文字的直書與橫書,產生正確的結果。
這是我拿另外一本古書來辨識的結果,以這種單純的文字來說,辨識的正確率相當高,另外我感覺 Google 雲端硬碟還會自動判斷與選擇相近的字體,只不過不是很準確就是了。
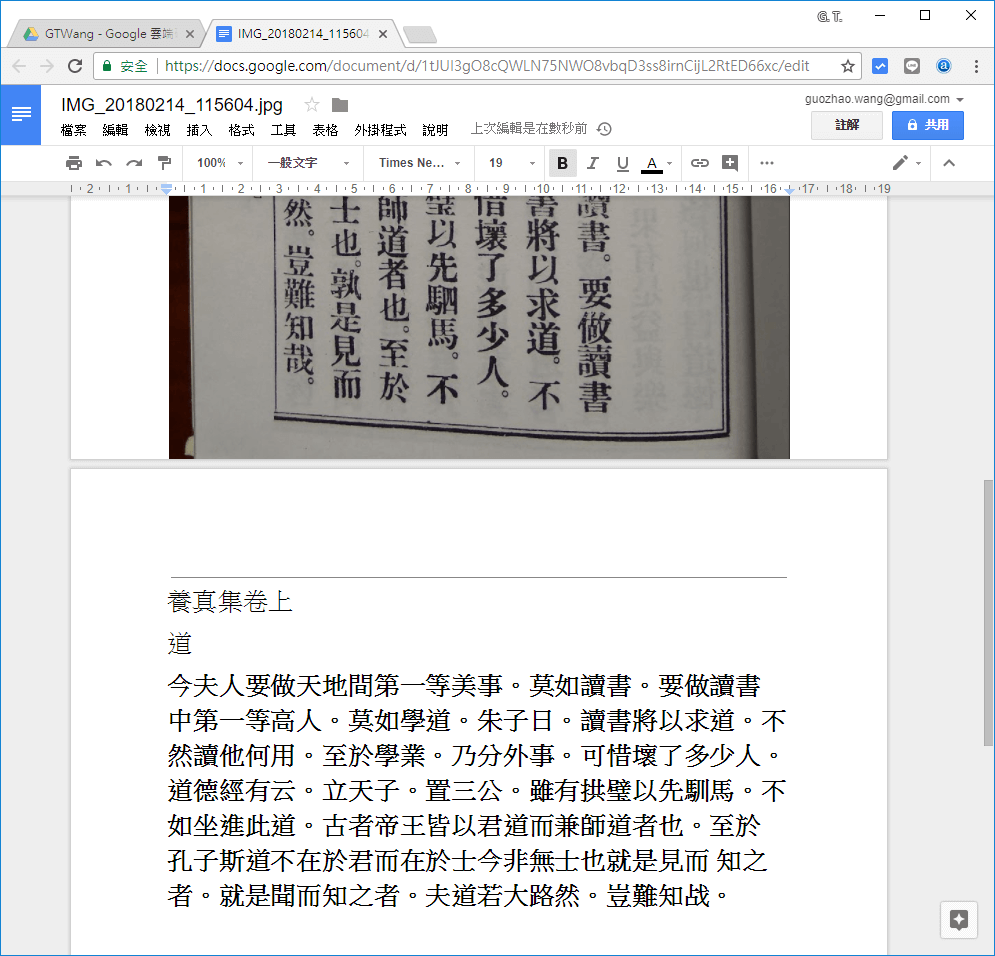
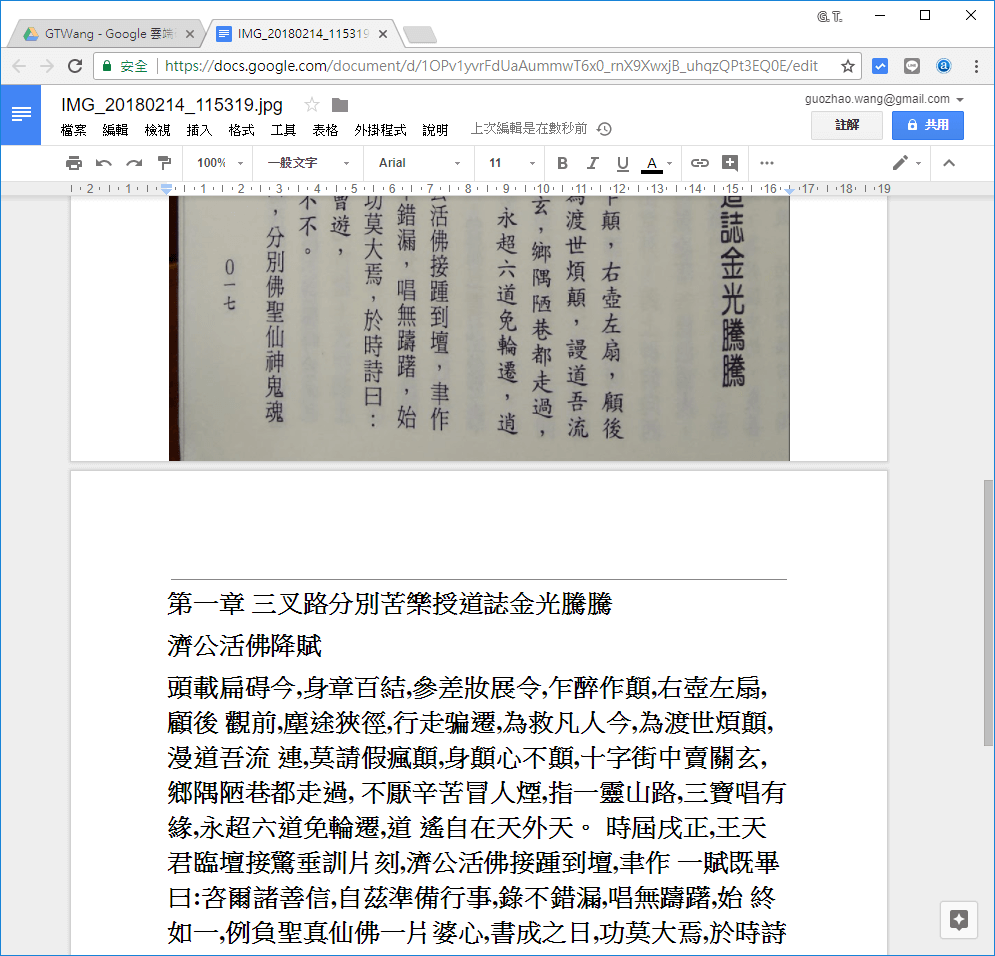
下面這一張是《三界靈針》的內容,這本書是比較偏文言文的書籍,雖然其紙本印刷清晰,但辨識的正確率比一般白話文低很多,會錯的字我看起來大部分都是比較文言的字,這種字可能在 Google 的辨識引擎中較少被訓練到,所以正確率較低。
複雜排版文字
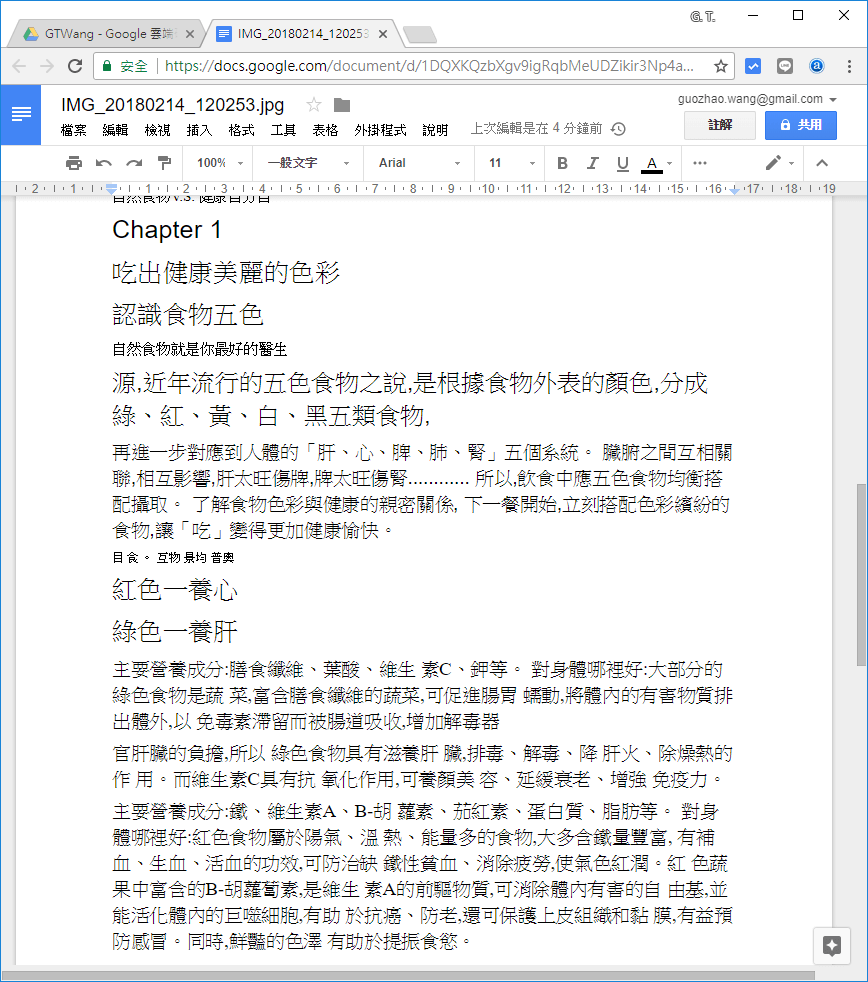
有一些書籍可能會有比較複雜的排版,例如將頁面區分成好幾個小區塊。

像這種有好多區塊的文字,若直接放到 Google 雲端硬碟上進行辨識的話,會造成不同區塊的文字混再一起,不好整理。
直覺的解決方式就是先依照區塊把圖片裁切好,再放到 Google 雲端硬碟上進行辨識。

這樣的效果就會好很多。
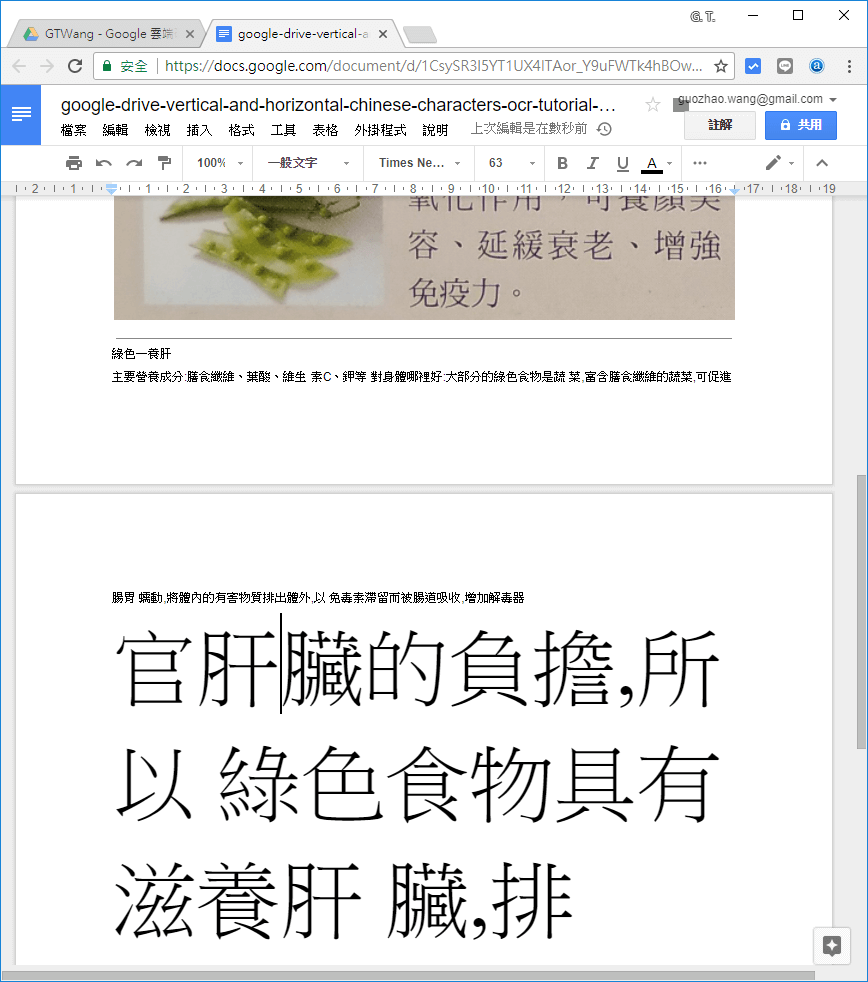
有時候辨識的結果會像這樣字型大小不一,不過看起來文字的內容都是正確的,自己稍微整理一下,就可以很快把圖片轉成文字了。
這裡只是示範用最簡單的方式,手動上傳圖片到 Google 雲端硬碟進行圖片的文字辨識,雖然可以省掉大部分的打字工作,但是如果圖片的數量很龐大時,這個做法也是會花不少時間的,如果想讓這個流程可以自動化,建議參考以 Python 配合 Google 雲端硬碟 API 的方式,讓程式自動處理上傳圖檔與下載結果的動作,減少人工的手動操作。