
本篇介紹如何安裝與使用 TensorFlow Object Detection API,自動辨識照片或影片中的物件。
Tensorflow Object Detection API 是 Google 以 TensorFlow 為基礎所開發的物件偵測程式開發架構(framework),其以開放原始碼的方式釋出,所有想要開發以深度學習自動辨識物件程式的人,都可以很方便的利用這套架構發展自己的系統。
安裝 Tensorflow Object Detection API
首先安裝 TensorFlow 的基本環境:
# CPU 版
pip install tensorflow
# GPU 版
pip install tensorflow-gpu
若在 Ubuntu Linux 中,其餘的套件可以使用 apt 安裝:
sudo apt-get install protobuf-compiler python-pil python-lxml
sudo pip install jupyter
sudo pip install matplotlib
在其他的 Linux 系統中,則可統一用 pip 安裝:
sudo pip install pillow
sudo pip install lxml
sudo pip install jupyter
sudo pip install matplotlib
從 GitHub 上面下載 Tensorflow Object Detection API 的原始碼:
git clone https://github.com/tensorflow/models.git
Tensorflow Object Detection API 在使用之前,要先編譯 Protobuf 函式庫:
# 編譯 Protobuf 函式庫
cd models/research
protoc object_detection/protos/*.proto --python_out=.
接著將 models/research 與 models/research/slim 加入 PYTHONPATH 環境變數中,這個步驟在每次使用 Tensorflow Object Detection API 之前都要執行,建議可以加入 ~/.bashrc 中:
# 將 models/research 與 models/research/slim 加入 PYTHONPATH
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
若沒有出現錯誤訊息的話,接下來就可以開始使用 Tensorflow Object Detection API 偵測物件了。
常見問題
如果 protoc 的版本太舊,編譯時可能會出現這樣的錯誤訊息:
object_detection/protos/anchor_generator.proto:11:3: Expected "required", "optional", or "repeated". object_detection/protos/anchor_generator.proto:11:32: Missing field number.
若遇到這樣的狀況,可以直接下載預先編譯好的 protoc 來使用:
# 建立放置 protoc 的目錄
mkdir protoc_3.3
# 下載與解壓縮 protoc 3.3
cd protoc_3.3
wget https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip
chmod 775 protoc-3.3.0-linux-x86_64.zip
unzip protoc-3.3.0-linux-x86_64.zip
# 使用 protoc 3.3 編譯
/your/path/protoc_3.3/bin/protoc object_detection/protos/*.proto --python_out=.
Hello World
Tensorflow Object Detection API 的原始碼中有附帶一個簡單的入門範例程式,位於 models/research/object_detection/object_detection_tutorial.ipynb,適合初學者來學習如何使用這套 API,這個範例程式是一個 .ipynb 的文件,必須要在 IPython Notebook 的環境中執行。
進入 object_detection 目錄,開啟 Jupyter Notebook:
cd object_detection
jupyter notebook
開啟 Jupyter Notebook 之後,開啟 object_detection_tutorial.ipynb 這個範例程式碼:
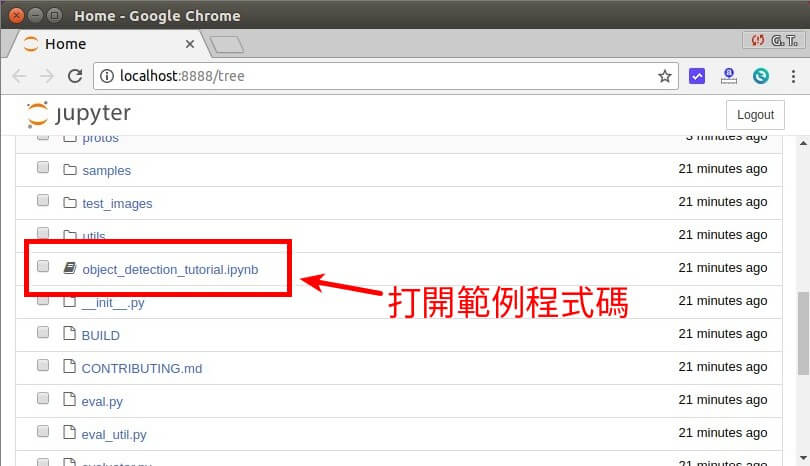
這個範例程式碼是由 Google 官方所提供的,裡面還有一些簡略的說明,對於熟悉 Python 與 TensorFlow 架構的人來說,應該是很容易就可以看得懂。
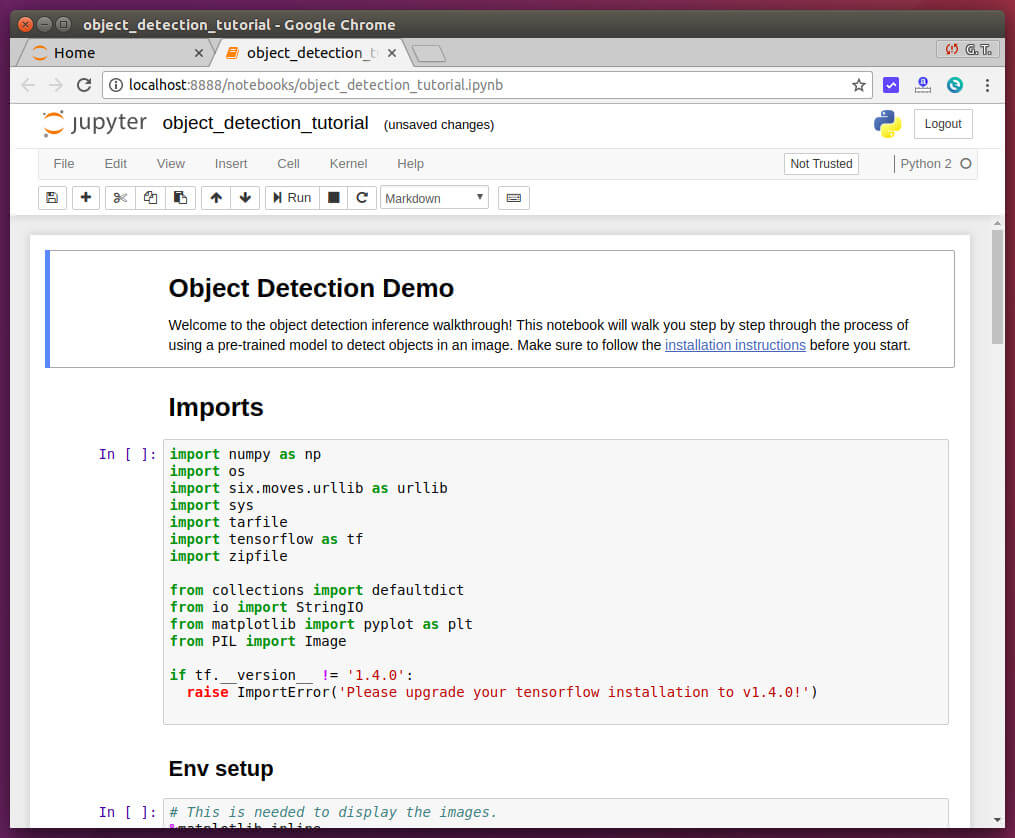
這個範例程式本身就有附帶測試用的圖片資料,所以可以直接執行,正常來說執行後就會得到兩張偵測結果的圖片。
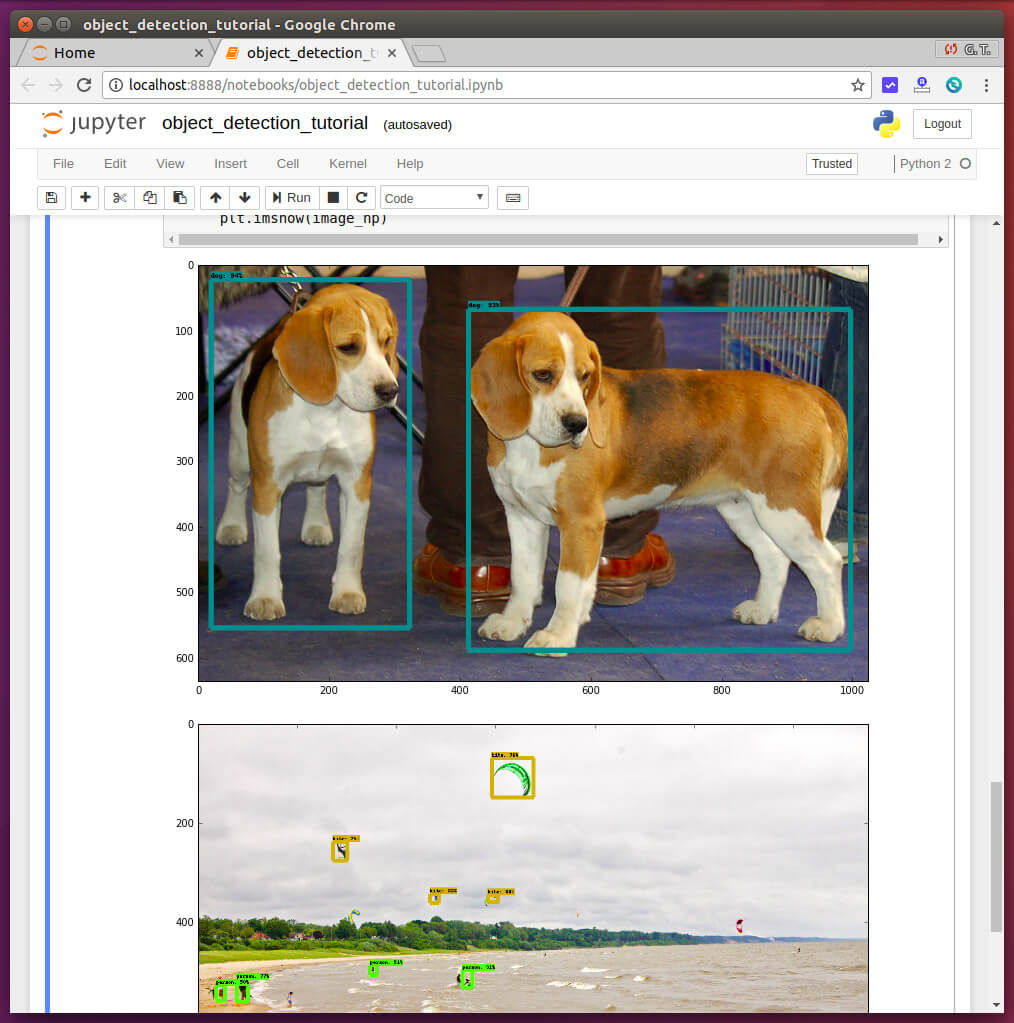
這樣就完成 Tensorflow Object Detection API 基本的環境安裝與測試了。
我直接拿幾張照片來測試,這個範例程式碼所使用的模型是 SSD + Mobilenet,辨識物件的速度非常快,但是精確度似乎不是非常好。
這份範例程式碼的的測試圖檔是由 TEST_IMAGE_PATHS 這個變數來設定的,我們可以修改它,加上自己的圖片來測試一下:
# 設定測試用的圖檔
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 2) ]
以下是一些 Tensorflow Object Detection API 測試結果的圖片。





接下來我們將以這個範例程式碼為基礎,介紹如何修改裡面的設定,根據自己的需求製作出適合的自動物件辨識引擎。
指定模型
Tensorflow Object Detection API 提供了許多種不同的模型,每個模型各有優缺點,Speed 是辨識的速度,而 COCO mAP 則代表準確度,入門範例中使用的 ssd_mobilenet_v1_coco 模型是速度最快的,但是準確度也是最差的,這種模型適合用在即時(real time)的應用。如果比較在意準確度而不在意速度的話,就可以考慮其它模型。
在這個範例中,我們可以透過 MODEL_NAME 來指定模型,這裡示範換成準確度比較高的 Faster RCNN + NAS(Neural Architecture Search)模型:
# 使用 Faster RCNN + NAS 模型
MODEL_NAME = 'faster_rcnn_nas_coco_2017_11_08'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
以下是用 Faster RCNN + NAS 模型所跑出來的結果:





換成 Faster RCNN + NAS 模型之後,大部分的結果都很不錯,只差小獅子會被誤判成貓與狗,不過感覺起來準確度是可以接受的。
影片與網路攝影機的物件辨識
以上的應用都是拿靜態的圖片進行物件辨識,接下來我們要示範如何從影片或即時的網路攝影機取得影像,靠著 Tensorflow Object Detection API 辨識出串流影片中的物件,並產生有物件標註的影片檔。
首先將上面的範例儲存成一般的 Python 指令稿,然後參考 OpenCV 擷取網路攝影機串流影像的技巧,將這個範例中的輸入影像替換為攝影機的影像,讓每個串流影格經過 Tensorflow Object Detection API 物件辨識處理後,再即時顯示在 OpenCV 的視窗中。
完整個範例程式碼如下:
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
import scipy.misc
# 加入 OpenCV 模組
import cv2
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
if tf.__version__ != '1.4.0':
raise ImportError('Please upgrade your tensorflow installation to v1.4.0!')
# 建立 VideoCapture 物件
cap = cv2.VideoCapture(1)
# 設定擷取的畫面解析度
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 960)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
sys.path.append("..")
from utils import label_map_util
from utils import visualization_utils as vis_util
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# 使用無窮迴圈,持續擷取網路攝影機影像
while True:
# 讀取一個影格
ret, image_np = cap.read()
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
image_np_expanded = np.expand_dims(image_np, axis=)
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=4)
# 以 OpenCV 視窗即時顯示辨識結果
cv2.imshow('object detection', image_np)
if cv2.waitKey(25) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
執行之後,就可以從網路攝影機擷取串流的影像,即時產生辨識的結果。
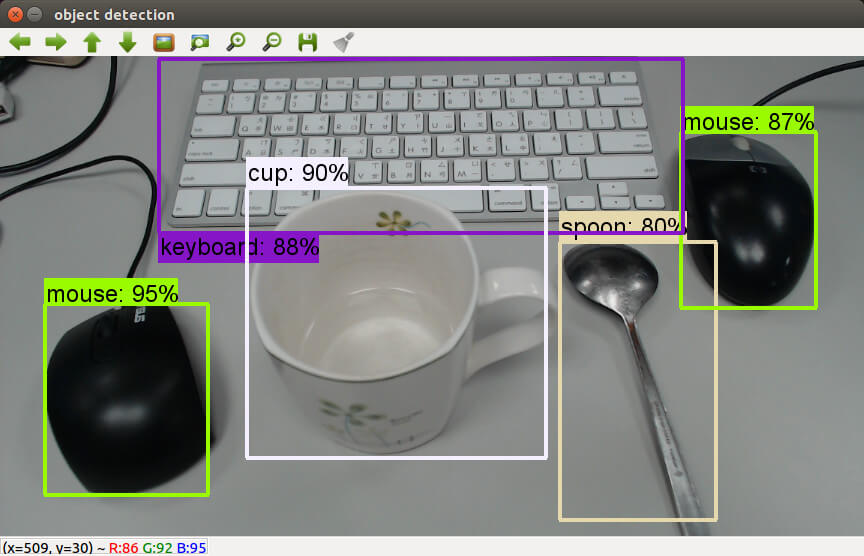
這是我將每個影格辨識的結果輸出成影片的樣子。
在這種即時性的應用,就比較適合使用 SSD + Mobilenet 這類運算比較快的模型,若使用 Faster RCNN + NAS 這種比較慢的模型,每個畫面運算就要等比較久。
除了即時擷取網路攝影機的影像之外,也可以從影片檔案讀取畫面來進行物件辨識,我拿之前用樹莓派拍攝的縮時攝影來測試,以下是測試結果: