這裡介如何使用自己的資料,以 TensorFlow Object Detection API 訓練出適用於特定物件的模型,建立自己的物件辨識系統。
在 TensorFlow Object Detection API 自動辨識物件教學文章中,我們是直接使用既有已經訓練好的模型來辨識物件,但如果我們有一些比較特別的物件需要進行辨識,而這些物件又沒有被包含在既有模型中的話,就沒辦法直接使用既有的模型,這時候就需要先蒐集一些該物件的影像與標註資料,進一步訓練模型後,才能讓模型辨識出比較特別的物件。
接下來將介紹如何使用自己的資料,訓練出可以辨識特定物件的模型,我們先以 Google 官方所提供的範例來說明自行訓練模型的流程。
這裡我們將使用 Oxford-IIIT Pet Dataset 這套寵物的資料集來訓練一個寵物辨識模型,讓訓練出來的模型可以辨識出貓與狗的品種。
在實作本篇的內容之前,請先參考上一篇的教學,下載 TensorFlow Object Detection API 的原始碼,編譯並安裝好。
準備訓練用資料
使用 TensorFlow Object Detection API 訓練模型時,我們需要影像的資料,加上框住物件的方框(bounding box)以及該物件的類別資訊,而 Oxford-IIIT Pet Dataset 這套資料集所提供的 Dataset 與 Groundtruth data 兩包資料,就剛好涵蓋了我們所需要的所有資訊,請將這兩個壓縮檔下載下來,解壓縮之後放在 models/research/ 之中:
cd models/research/
# 下載 Oxford-IIIT Pet Dataset
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
# 解壓縮至 models/research/
tar zxvf images.tar.gz
tar zxvf annotations.tar.gz
解壓縮完兩個壓縮檔之後,現在 models/research/ 目錄之下應該會包含以下幾個檔案與目錄:
annotations.tar.gzannotations/images.tar.gzimages/object_detection/
這幾個檔案與目錄是這個範例所需要的,所以要確認它們的相對位置,至於其他的目錄目前不會用到,所以就可以不用管它們。
在使用 Tensorflow Object Detection API 在訓練模型時,所讀取的資料格式是 TFRecord,所以我們要先用 create_pet_tf_record.py 這個 Python 指令稿,把 Oxford-IIIT Pet Dataset 的資料轉換為 TFRecord 格式:
# 將 Oxford-IIIT Pet Dataset 資料轉為 TFRecord 格式
python object_detection/dataset_tools/create_pet_tf_record.py
--label_map_path=object_detection/data/pet_label_map.pbtxt
--data_dir=`pwd`
--output_dir=`pwd`
執行之後,在 models/research/ 目錄下應該會產生兩個 TFRecord 檔:
pet_train_with_masks.recordpet_val_with_masks.record
我在撰寫文章時發現這個 create_pet_tf_record.py 指令稿可能因為處於開發階段,有些小 bugs 造成 TFRecord 檔轉不出來,若遇到這種狀況請開啟 create_pet_tf_record.py 指令稿自己除錯。
在預設的轉檔模式下,create_pet_tf_record.py 會產生動物臉部的資料集,若要產生全身動物的資料集,可調整 --faces_only 參數,詳細的使用方式,請直接查看這個程式的原始碼。
將產生的這兩個 TFRecord 檔案放進 models/research/object_detection/data/ 之中:
mv pet_train_with_masks.record object_detection/data/
mv pet_val_with_masks.record object_detection/data/
這樣資料就準備好了。
預訓練模型
要訓練一個高水準的模型,縱使有多張 GPU 卡通常也都需要非常久的時間,而使用預訓練模型(pre-trained model)最為初始值來進行訓練,可以加速訓練的過程。這裡我們拿一個以 COCO 資料集所訓練出來的模型為基礎,作為我們的模型初始值。
下載 Faster RCNN + Resnet101 以 COCO 資料集訓練好的模型:
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
tar zxvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
將模型參數的檢查點(check points)放入 object_detection/data/:
# 將模型參數放入 object_detection/data/
cp faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.* object_detection/data/
建立模型訓練管線
在 Tensorflow Object Detection API 中,所有的模型參數、訓練參數與驗證參數都定義在一個 .config 設定檔中(詳細說明可參考 TensorFlow 的文件),在 object_detection/samples/configs/ 目錄下有許多範例設定檔,這裡我們先以 faster_rcnn_resnet101_pets.config 這個範例設定檔來修改,請使用一般的文字編輯器編輯這個設定檔。
在這個範例設定檔中,尋找含有 PATH_TO_BE_CONFIGURED 的位置,將這些地方替換成自己系統上的路徑。
編輯完成後,將這個設定檔儲存於 models/research/object_detection/data/ 之中。
到現在為止,models/research/object_detection/data/ 這個目錄中應該會包含以下檔案(其他的不重要):
faster_rcnn_resnet101_pets.configmodel.ckpt.data-00000-of-00001model.ckpt.indexmodel.ckpt.metapet_label_map.pbtxtpet_train_with_masks.recordpet_val_with_masks.record
訓練模型
參考 TensorFlow 的文件,進行模型訓練。首先定義一下設定檔與訓練結果的放置路徑:
# 設定檔路徑
PIPELINE_CONFIG="object_detection/data/faster_rcnn_resnet101_pets.config"
# 訓練結果放置路徑
MY_MODEL_DIR="my_model"
接著使用一張好一點的 GPU 卡進行訓練:
# 使用第一張 GPU 卡進行訓練
CUDA_VISIBLE_DEVICES= python object_detection/train.py
--logtostderr
--pipeline_config_path=${PIPELINE_CONFIG}
--train_dir=${MY_MODEL_DIR}/train
如果還有第二張 GPU 卡,可以開啟另外一個終端機(或使用 screen 環境),執行驗證的 Python 指令稿:
# 使用第二張 GPU 卡進行驗證
CUDA_VISIBLE_DEVICES=1 python object_detection/eval.py
--logtostderr
--pipeline_config_path=${PIPELINE_CONFIG}
--checkpoint_dir=${MY_MODEL_DIR}/train
--eval_dir=${MY_MODEL_DIR}/eval
開啟另外一個終端機,執行 TensorBoard 以監看模型訓練情況:
# 啟動 TensorBoard
tensorboard --port=16006 --logdir=${MY_MODEL_DIR}
訓練的過程需要一段時間,我拿一張 NVIDIA GeForce GTX 1060 來跑,大約需要一天多左右,訓練的過程中可以使用 TensorBoard 檢查模型的情況。
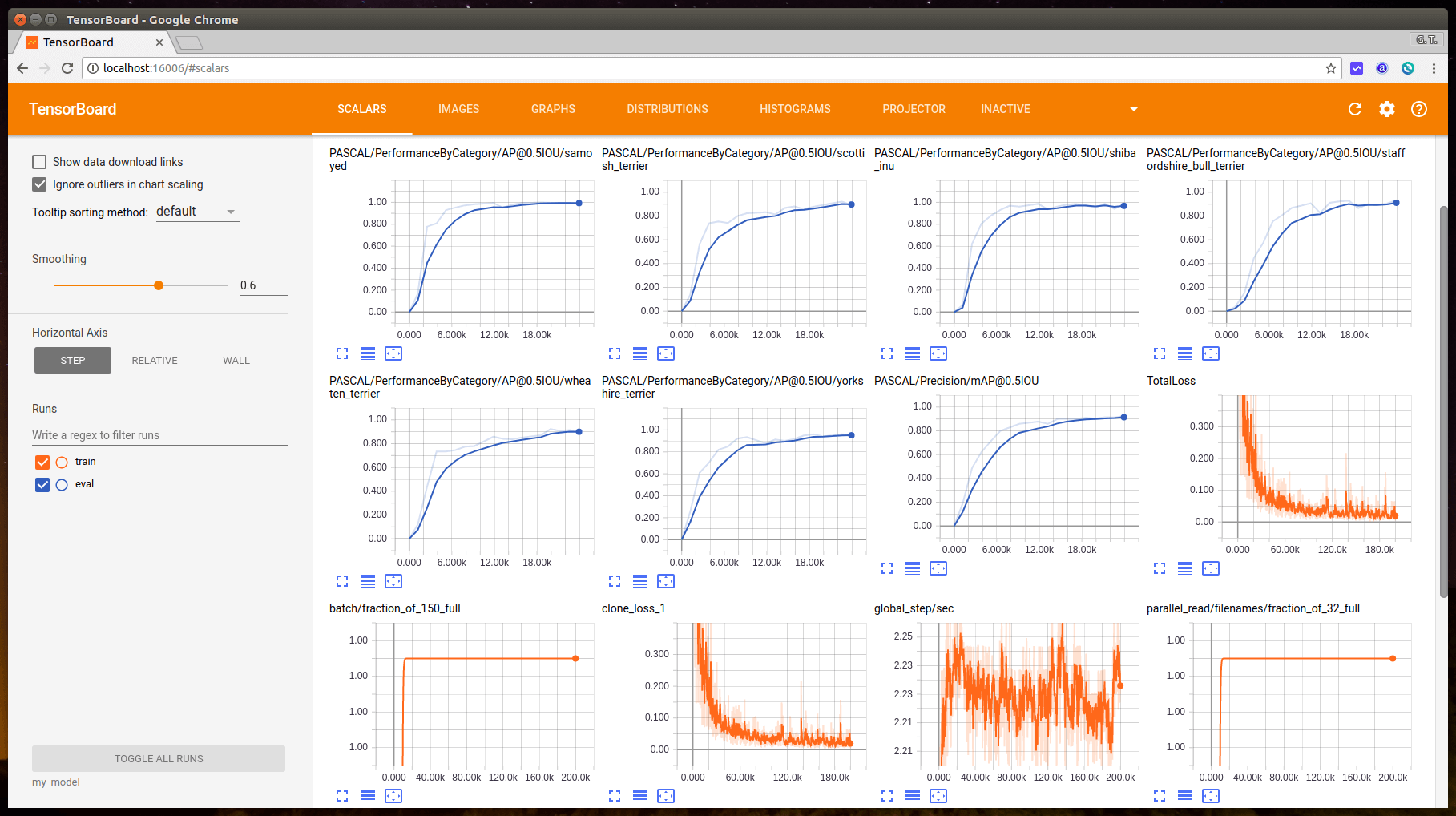
若有同時執行驗證模型的 Python 指令稿的話,就可以同時在 TensorBoard 中觀看驗證結果。
匯出模型
當模型訓練完成後,接著就可以將模型匯出。首先找到訓練模型時所輸出的檢查點檔案,其位於放置檢查點的目錄中(在這個例子中則為 ${MY_MODEL_DIR}/train),而一個檢查點包含三個檔案,分別為:
model.ckpt-${CHECKPOINT_NUMBER}.data-00000-of-00001model.ckpt-${CHECKPOINT_NUMBER}.indexmodel.ckpt-${CHECKPOINT_NUMBER}.meta
找到檢查檔之後,切換至 models/research/ 目錄,執行以下指令將模型匯出:
# 設定檢查點檔案路徑
CHECKPOINT_NUMBER=200000
CKPT_PREFIX=${MY_MODEL_DIR}/train/model.ckpt-${CHECKPOINT_NUMBER}
# 將訓練好的模型匯出
python object_detection/export_inference_graph.py
--input_type image_tensor
--pipeline_config_path ${PIPELINE_CONFIG}
--trained_checkpoint_prefix ${CKPT_PREFIX}
--output_directory my_exported_graphs
匯出的模型會被儲存於 my_exported_graphs 這個目錄中,這樣就完成整個模型的訓練過程了。
預測
將模型匯出之後,就可以稍微修改一下前一篇教學的程式碼,把模型與標註對應檔替換掉,就可以使用新模型進行預測了,這部份請依照自己的路徑來修改。
# 設定模型與標註對應檔路徑
MODEL_NAME = 'path/to/my_exported_graphs'
PATH_TO_LABELS = 'path/to/pet_label_map.pbtxt'
類別數量也要記得改一下:
NUM_CLASSES = 37
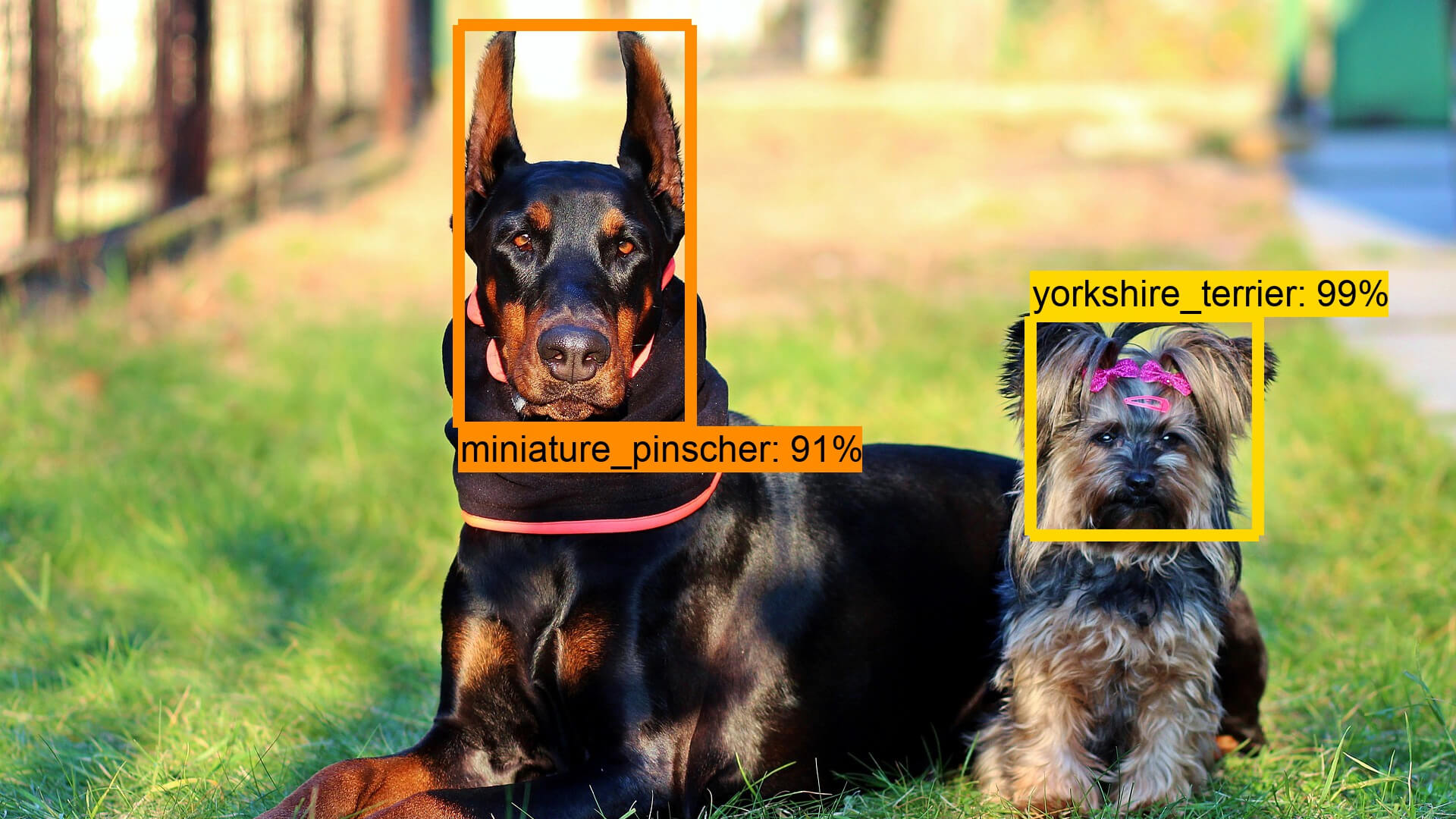
跑出來的結果會像這樣:
測試的時候,可以直接拿 OXFORD-IIIT PET Dataset 的測試資料集來使用,或是從網路下載一些可愛的照片來測試。


以上是拿 OXFORD-IIIT PET Dataset 資料集放進 TensorFlow Object Detection API 訓練模型的流程,事實上只要能夠將資料轉換成正確的格式,任何資料集都可以放進來使用。
網路上還有非常多的資料集可以免費下載使用,接下來我們繼續示範另外一個 PASCAL VOC 2012 資料集的使用方式,請繼續閱讀下一頁。
PASCAL VOC 2012 資料集
首先從 PASCAL VOC 2012 的網站上下載該資料集,整個資料集的大小大約是 2GB,下載時要稍微等一下:
cd models/research/
# 下載 PASCAL VOC 2012 資料集(2GB)
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
使用 create_pascal_tf_record.py 將 PASCAL VOC 2012 資料轉為 TFRecord 格式:
# 將 PASCAL VOC 2012 資料轉為 TFRecord 格式(training set)
python object_detection/dataset_tools/create_pascal_tf_record.py
--data_dir=VOCdevkit
--year=VOC2012
--set=train
--label_map_path=object_detection/data/pascal_label_map.pbtxt
--output_path=object_detection/data/pascal_train.record
# 將 PASCAL VOC 2012 資料轉為 TFRecord 格式(validation set)
python object_detection/dataset_tools/create_pascal_tf_record.py
--data_dir=VOCdevkit
--year=VOC2012
--set=val
--label_map_path=object_detection/data/pascal_label_map.pbtxt
--output_path=object_detection/data/pascal_val.record
這裡同樣以 Faster RCNN + Resnet101 + COCO 的模型作為預訓練模型,下載後放進 object_detection/data/ 目錄:
# Faster RCNN + Resnet101 以 COCO 資料集訓練好的模型
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
# 將模型參數放入 object_detection/data/
tar zxvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
cp faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.* object_detection/data/
接下來要建立一個 .config 設定檔,這部分可參考 faster_rcnn_resnet101_voc07.config 這個內建的範例,將包含 PATH_TO_BE_CONFIGURED 的路徑修改一下,其餘的設定可以不需要更改,編輯完成後同樣儲存於 models/research/object_detection/data/ 之中,由於我們這裡使用的資料是 2012 年的,所以我把新的檔名變更為 faster_rcnn_resnet101_voc12.config。
接著就可以開始訓練模型,訓練模型的方式跟之前相同:
# 設定檔路徑
PIPELINE_CONFIG="object_detection/data/faster_rcnn_resnet101_voc12.config"
# 訓練結果放置路徑
MY_MODEL_DIR="my_voc_model"
# 使用第一張 GPU 卡進行訓練
CUDA_VISIBLE_DEVICES= python object_detection/train.py
--logtostderr
--pipeline_config_path=${PIPELINE_CONFIG}
--train_dir=${MY_MODEL_DIR}/train
# 使用第二張 GPU 卡進行驗證
CUDA_VISIBLE_DEVICES=1 python object_detection/eval.py
--logtostderr
--pipeline_config_path=${PIPELINE_CONFIG}
--checkpoint_dir=${MY_MODEL_DIR}/train
--eval_dir=${MY_MODEL_DIR}/eval
# 啟動 TensorBoard
tensorboard --port=16006 --logdir=${MY_MODEL_DIR}
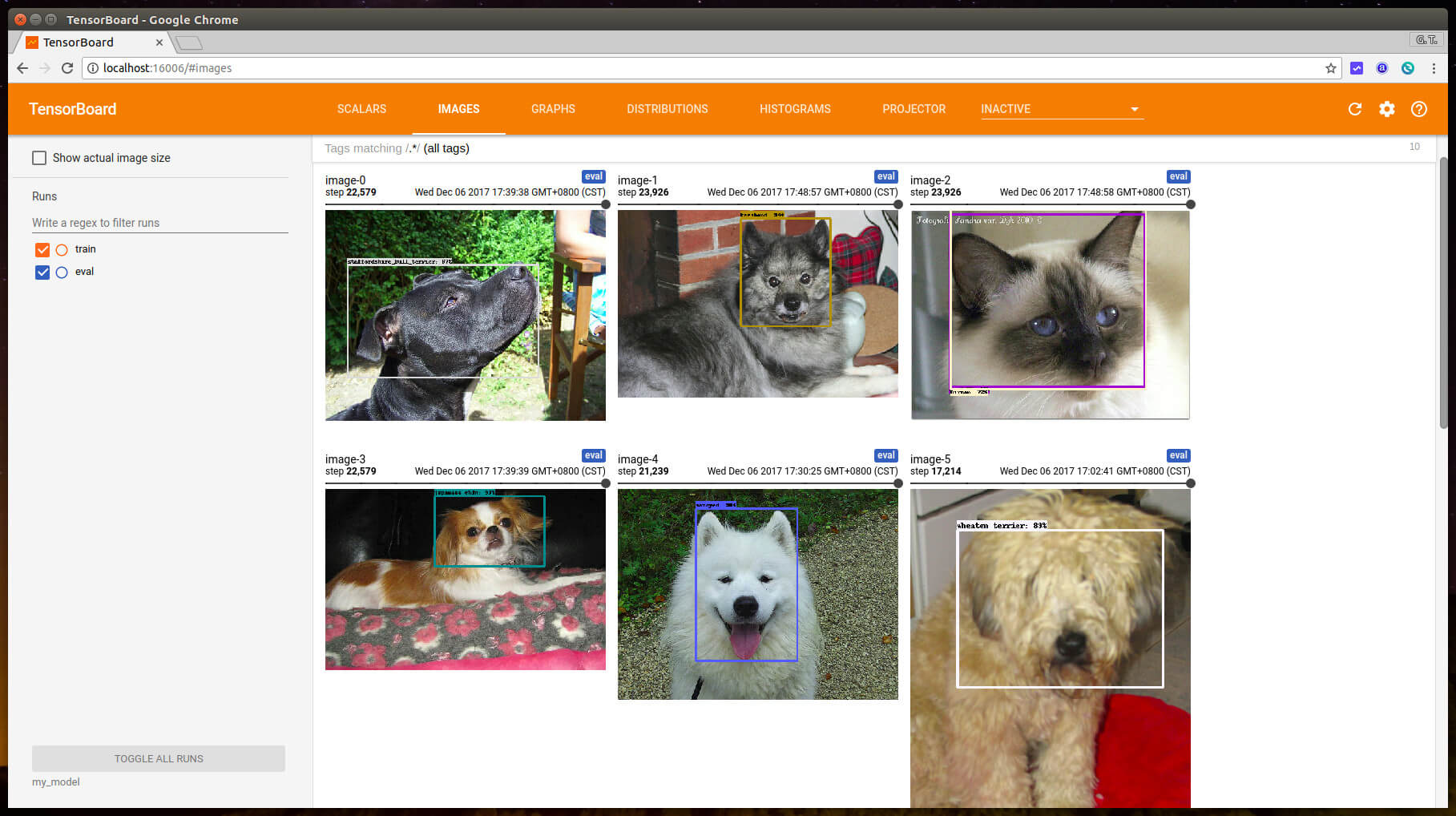
在訓練的過程中,同樣可以使用 TensorBoard 監看模型的狀況:
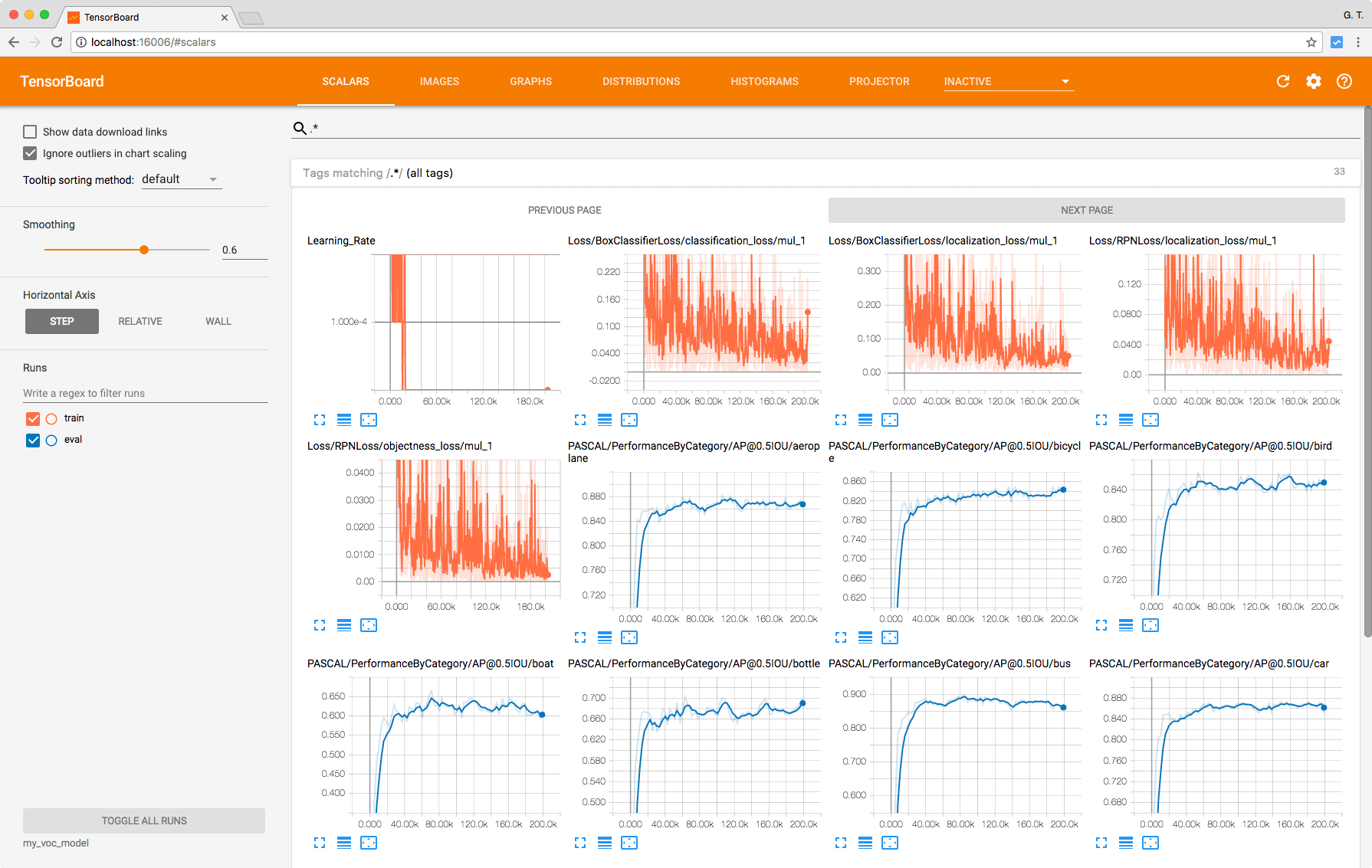
模型訓練好之後,依照同樣的方式匯出模型:
# 設定檢查點檔案路徑
CHECKPOINT_NUMBER=800000
CKPT_PREFIX=${MY_MODEL_DIR}/train/model.ckpt-${CHECKPOINT_NUMBER}
# 將訓練好的模型匯出
python object_detection/export_inference_graph.py
--input_type image_tensor
--pipeline_config_path ${PIPELINE_CONFIG}
--trained_checkpoint_prefix ${CKPT_PREFIX}
--output_directory my_exported_graphs
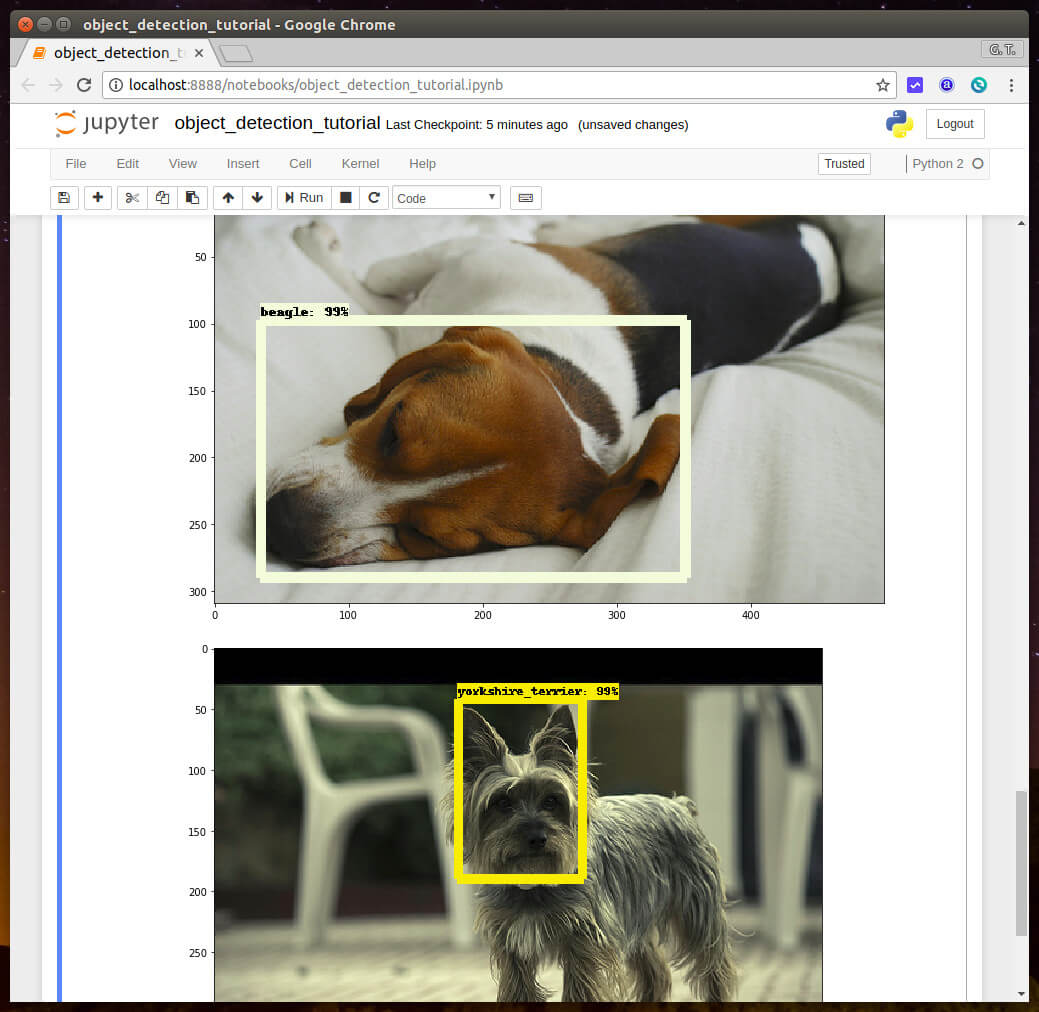
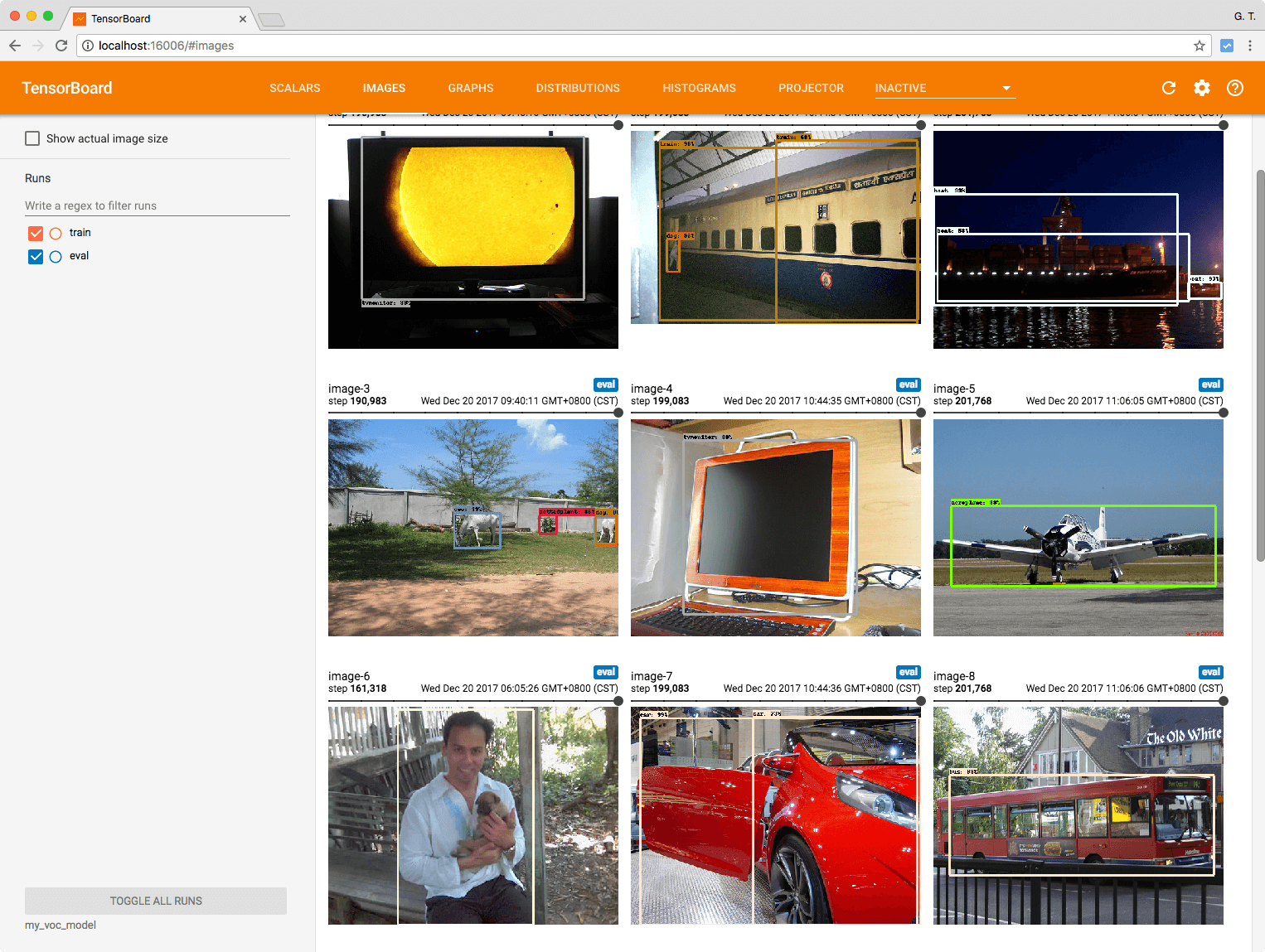
並將新模型套用至前一篇教學的程式碼,跑出來的結果會像這樣:

