
本篇為史丹佛大學機器學習(Machine Learning)課程 Lecture 4 的前半段筆記,接續 Lecture 3 的內容。
Lecture 4 的線上課程錄影可以從 YouTube 網站上觀看。
使用牛頓法找 \(l(\theta)\) 的最大值
這裡我們繼續討論 \(g(z)\) 是 sigmoid function 的狀況,介紹另外一種求 \(l(\theta)\) 極大值的方法。
首先我們介紹可以找尋函數零點的牛頓法,假設我們有一個函數 \(f : \mathbb{R} \mapsto \mathbb{R}\),而我們想要找一個 \(\theta\) 可以讓 \(f(\theta) = 0\)(這裡的 \(\theta \in \mathbb{R}\) 是一個實數),牛頓法就是用下面這個迭代式來求這個 \(\theta\):
\[ \theta := \theta - \frac{f(\theta)}{f'(\theta)} \]這個方式其實就是計算每個迭代位置的切線與 \(x\) 軸的交點,來作為下一個迭代的 \(\theta\) 值,下面這個動畫就是整個牛頓法迭代的過程(擷取自 Wiki):
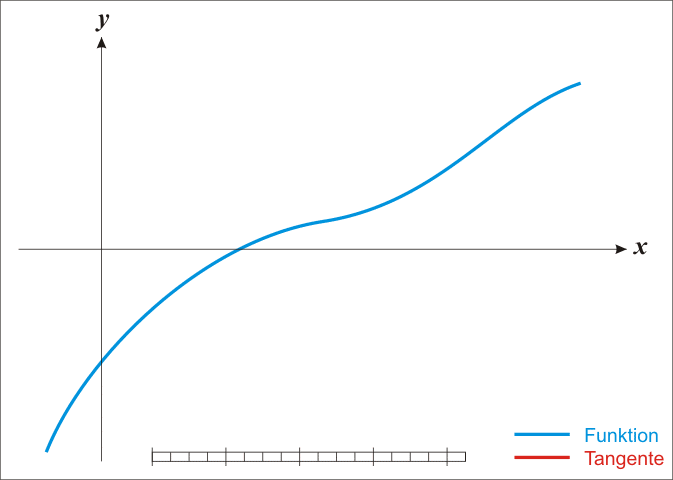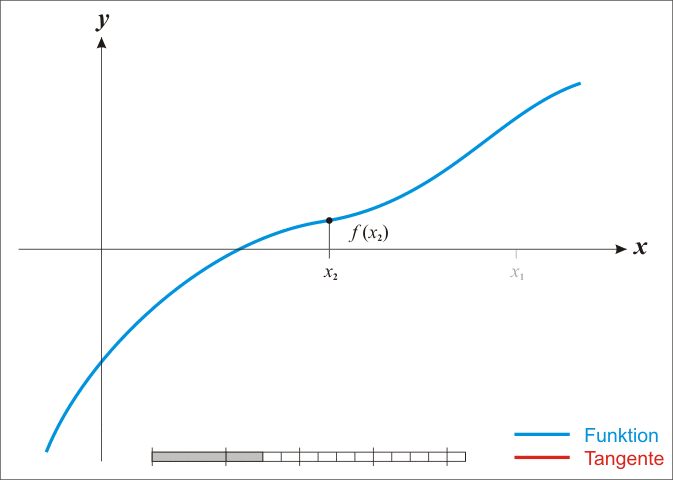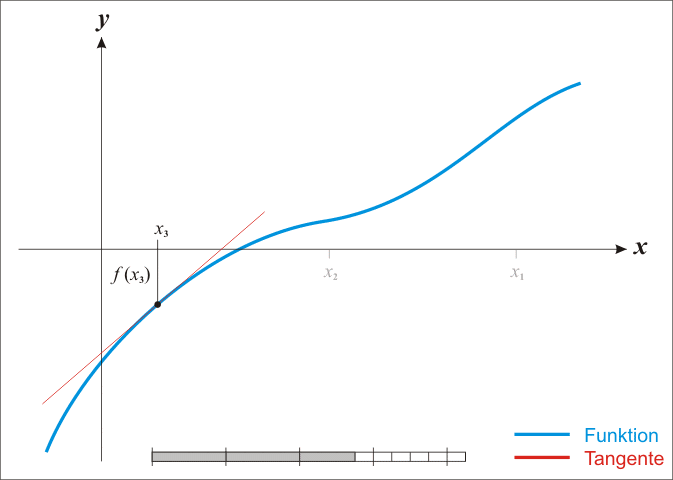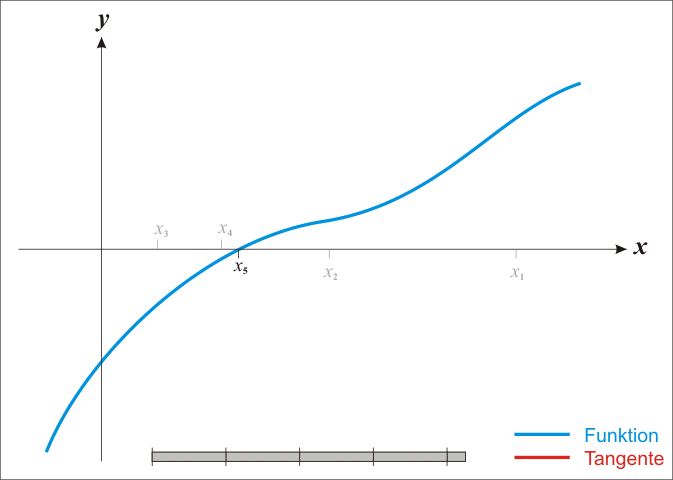
關於牛頓法詳細的解說,請參考 Wiki 的說明。
一般的牛頓法可以求 \(f(\theta) = 0\) 的解,但是在這裡我們要找的是 \(l(\theta)\) 的最大值,而 \(l(\theta)\) 的最大值會發生在 \(l'(\theta)\) 等於 0 的點上,所以可以直接套用牛頓法,令 \(f(\theta) = l'(\theta)\),則可得到:
\[ \theta := \theta - \frac{l'(\theta)}{l''(\theta)} \]而在我們的羅吉斯迴歸問題中,\(\theta\) 是一個向量,所以我們必須使用多維度的牛頓法(也稱作 Newton-Raphson 方法):
\[ \theta := \theta-H^{-1}\nabla_{\theta}l(\theta) \]其中 \(\nabla\_{\theta}l(\theta)\) 是 \(l(\theta)\) 對每個 \(\theta\_i\) 做偏微分所得到的向量,而 \(H\) 是一個 \(n\) 乘以 \(n\)(如果截距項也算,就是 \(n+1\) 乘以 \(n+1\))的 Hessian 矩陣,此矩陣的元素為
\[ H_{ij}=\frac{\partial^{2}l(\theta)}{\partial\theta_i\partial\theta_j} \]牛頓法收斂的速度通常會比 gradient descent 快,也就是說牛頓法需要的迭代數比較少,但是牛頓法的每個迭代所需要的計算量會比 gradient descent 大,因為它每次迭代都需要計算一個 \(n\) 乘以 \(n\) 的 Hessian 矩陣,而且還要計算它的反矩陣,不過如果 \(n\) 沒有很大的話,牛頓法所需要的總時間還是會比較短。
這裡將牛頓法用在求最大概似函數(maximum likelihood function)的極大值上,這個作法也稱為 Fisher’s scoring 演算法。
廣義線性模型(Generalized Linear Models)
在前面的課程中,我們討論過迴歸(regression)與分類(classification)的問題,在迴歸的問題中所使用的模型為 \(y|x;\theta\sim\mathcal{N}(\mu,\sigma^2)\),而分類問題所使用的模型則為 \(y|x;\theta\sim\mbox{Bernoulli}(\phi)\),其中的 \(\mu\) 與 \(\phi\) 是 \(x\) 與 \(\theta\) 的函數。
在這裡我們將介紹廣義線性模型(generalized linear models,簡稱 GLM),之前的兩種模型都是廣義線性模型的特例,除此之外廣義線性模型還可以推導出其他不同的模型,適用於其他類型的分類或迴歸問題。
指數族(The Exponential Family)
在介紹廣義線性模型之前,要先介紹指数族分布(exponential family distributions),如果一個分布的機率密度函數(probability density function)或是機率質量函數(probability mass function)可以寫成
\[ p(y;\eta)=b(y)\exp(\eta^TT(y)-a(\eta)) \]則稱該分布屬於指数族。這裡的 \(\eta\) 稱為該分布的 natural parameter(或 canonical parameter);\(T(y)\) 是一個充分統計量(sufficient statistic),在我們討論的例子中,\(T(y)\) 都是等於 \(y\);\(a(\eta)\) 是一個 log partition 函數。\(e^{-a(\eta)}\) 是一個用來讓整個函數正規化(normalization)的常數,也就是讓整個 \(p(y;\eta)\) 函數對 \(y\) 積分或加總之後會等於 1。
選定 \(T\)、\(a\) 與 \(b\) 之後,就會得到一個參數為 \(\eta\) 的分布族,當我們改變 \(\eta\) 的值,就可以得到該分布族的一個分布。
接下來我們將證明 Bernoulli 與 Gaussian 分布其實也都是指數族分布的一種,也就是說上面的 \(T\)、\(a\) 與 \(b\) 經過適當的選擇之後,就可以得到這兩個分佈的機率密度函數(或機率質量函數)。
Bernoulli(\(\phi\)) 分布的機率質量函數為
\[ p(y;\phi) = \left\{\begin{array}{ll} \phi,& \mbox{if y=1} \\ 1-\phi,& \mbox{if y=0} \end{array} \right. \]當我們改變 \(\phi\) 的值的時候,就可以得到不同平均數的 Bernoulli 分布。上面這個式子可以改寫成
\[ \begin{aligned} p(y;\phi) & = \phi^y(1-\phi)^{1-y}\\ & = \exp\big(y\log\phi+(1-y)\log(1-\phi)\big)\\ & = \exp\Big(\big(\log\big(\frac{\phi}{1-\phi}\big)\big)y+\log(1-\phi)\Big) \end{aligned} \]這樣就可以看出來 natural parameter 為 \(\eta=\log(\phi/(1-\phi))\)