在 R 中所有的變數都有一個類別(class)屬性,它紀錄每個變數所屬的類別,例如大部分的數值都屬於 numeric 類別,而邏輯值則是屬於 logical 類別。
嚴格來說應該是數值向量屬於
numeric類別,而邏輯向量屬於logical類別,因為在 R 中最基礎的資料結構就是向量,並沒有單一的純量。
R 的 class 函數可以用來判斷變數所屬的類別:
class(c(TRUE, FALSE))
[1] "logical"
由 TRUE 與 FALSE 所組成的向量是屬於 logical 類別。
除了類別(class)之外,R 的變數還有一個內部儲存用的類型(type)屬性、一個模式(mode)屬性,以及一個儲存模式(storage mode)屬性,這幾種屬性是前幾代舊版的 R 所遺留下來的,一般的使用者在大部份的狀況下並不會直接使到它們(除非您準備要加入 R 的核心開發者團隊),目前我們只需要熟悉類別(class)即可,以下我們在討論變數的類型時,都會以變數的類別(class)為主。關於四種屬性的對應關係,請參考後面的補充資料。
各種數值變數
在 R 中的數值總共有三種,分別為:
numeric:浮點數。integer:整數。complex:複數。
我們可以使用 class 函數來檢查變數的類型,一般的數字預設都會是浮點數:
class(3)
[1] "numeric"
如果要指定整數,可以在數字後面加上 L:
class(3L)
[1] "integer"
這是複數:
class(2 + 3i)
[1] "complex"
一般的序列會是整數:
class(5:10)
[1] "integer"
序列經過某些數學運算之後,會轉為浮點數:
class(sqrt(5:10))
[1] "numeric"
不過某些別的數學運算也還是會保持整數的類型:
class(sum(5:10))
[1] "integer"
這是浮點數組成的序列:
class(1.3:5.3)
[1] "numeric"
R 處理數值的限制
R 的 .Machine 這個內建變數中有一些關於數值資料的資訊,這些資訊可能會因為不同的電腦而有不同(不過對大多數的電腦而言,通常都是一樣的),以下是跟一般使用者比較相關的數值。
.Machine$double.xmax 與 .Machine$double.xmin 分別表示目前 R 所能處理的最大浮點數與最小正浮點數:
.Machine$double.xmax
[1] 1.797693e+308
.Machine$double.xmin
[1] 2.225074e-308
.Machine$integer.max 則是 R 可以處理的最大整數值:
.Machine$integer.max
[1] 2147483647
2147483647 這個值就等於 \(2^{31}-1\)。
如果需要更高精度的數值運算,可以使用 Rmpfr 這個套件,而如果是大數運算,則可以使用 brobdingnab 套件。
.Machine$double.eps 是 R 中不同數值的最小差異值,如果兩個不同數值的差異小於這個值,那麼 R 會將兩個數值視為相同的,而 all.equal 在判斷兩個向量是否相同時,也是使用這個值。
.Machine$double.eps
[1] 2.220446e-16
如果要讓 R 判斷 1 + \(\epsilon\) 不等於 1,則這個 \(\epsilon\) 值就不可以小於上面這個門檻值,如果 \(\epsilon\) 小於這個門檻值,R 就會無法判斷:
1 + 2.220446e-16 == 1
[1] FALSE
1 + 2.220446e-17 == 1
[1] TRUE
其餘各類型變數
除了最常用到的數值變數與邏輯變數之外,R 還有三種主要的變數類型,分別為字元(character)、因子(factor)以及原始(raw)類型,以下介紹這幾種類型的變數使用方式。
字元向量
字元向量跟一般數值向量一樣可以使用 c 函數來建立:
c("Hello", "World")
使用 class 來檢查字元向量:
class(c("Hello", "World"))
[1] "character"
R 是屬於比較高階的語言,在 R 中的字元變數不會像其他低階的程式語言一樣有區分單一字元與字串,也不需要像 C 語言一樣考慮字串結尾的 null 字元問題,使用者只需要直接很直覺的使用它即可。
因子向量
一般的程式語言在處理類別型的資料時,都會以整數來表示,例如男性與女性的資料可能就會以 1 與 2 來代表,但這樣的表示方法會讓人很難閱讀,另外有一種比較好一點做做法是直接使用文字來表示,例如男性以 male 表示,而女性則使用 female 表示,然而這樣還是有其缺點,畢竟類別型的資料跟一般的文字還是有不同的地方。
R 本身對於類別型的資料有獨特的處理方式,它將整數與文字的概念結合,建立一種專門表示類別資料的因子(factor)資料型態:
gender <- factor(c("male", "female", "male"))
gender
[1] male female male Levels: female male
因子變數的內容看起來跟字元變數很類似,我們可以直接看得到每個值的名稱,我們可以使用 levels 來列出因子變數中所有的類別:
levels(gender)
[1] "female" "male"
而 nlevels 則是可以計算因子變數類別的總數:
nlevels(gender)
[1] 2
因子變數在建立時,預設會以類別名稱來排序(依照英文字母的順序),所以
female會是第一個,而male則是第二個。
因子變數的名稱背後其實對應的是一些整數資料(R 內部在儲存這些資料時,都是使用整數),我們可以使用 as.integer 來看其對應的數值:
as.integer(gender)
[1] 2 1 2
相較於一般文字資料,以整數的形式儲存類別資料會比較節省記憶體空間,尤其是在類別數量少而資料量大的時候特別明顯,以下我們做一個測試,首先以一般的字元變數來產生 5000 個男生與女生的取樣資料,再將這個資料轉換為因子變數。
gender.char <- sample(c("female", "male"), 5000, replace = TRUE)
gender.factor <- as.factor(gender.char)
這裡的 as.factor 會將 gender.char 這個字元的向量轉換為因子向量。接下來我們使用 object.size 來比較看看兩者之間的大小差異:
object.size(gender.char)
40136 bytes
object.size(gender.factor)
20512 bytes
object.size 函數會傳回變數所使用的記憶體大小,將字元變數轉換為因子變數之後,可以節省不少記憶體空間。
如果要將因子變數轉換回字元變數,可以使用 as.character 函數:
as.character(gender)
[1] "male" "female" "male"
Raw 向量
raw 向量是專門用來儲存二進位資料的向量,我們可以將 0 到 255 之間的整數使用 as.raw 轉換為 raw 向量,而這種 raw 向量在輸出時,會以十六進位的方式輸出:
as.raw(0:16)
[1] 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10
as.raw 將資料轉換為 raw 向量時,只接受 0 到 255 之間的整數,所有的小數或是虛數都會被捨去,如果遇到不在這個區間的數值,會被直接轉換為 00:
as.raw(c(pi, 4 + 3i, -23, 300))
[1] 03 04 00 00
如果發生了上述幾種轉換的狀況,R 也會送出警告訊息:
Warning messages: 1: 強制變更時丟棄了虛數部分 2: 在強制變更成純量值時,任何溢位值當作 0 來處理
如果是字元變數要轉換為 raw 向量的話,可以使用 charToRaw 函數:
charToRaw("gtwang")
[1] 67 74 77 61 6e 67
除了以上介紹的幾種變數類型之外,R 還有很多其他類型的變數,其餘的部分會在後續的教學內容中慢慢介紹。
檢查與變更變數類別
在互動式的 R 操作環境之下,使用 class 函數可以立即檢查變數的類型,但是如果要在 R 的指令稿中確認變數的類型,class 函數就不是那麼方便使用了,此時可以改用 is 函數:
x <- 3
is(x, "numeric")
[1] TRUE
is 函數的第一個參數是要檢查的變數,而第二個參數則是類型名稱,它在檢查之後會傳回一個布林值(TRUE 或 FALSE),這樣可以很方便的放在判斷式中使用,例如:
if(is(x, "class_name")) {
# ...
}
大部分的變數類型都會有一個對應的 is.* 檢查函數,使用這類的函數會比一般性的 is 函數更有效率一些:
is.character("gtwang")
[1] TRUE
is.* 這類的函數有很多,我們可以使用下面這行指令列出所有 ls 開頭的指令:
ls(pattern = "^is", baseenv())
[1] "is.array" "is.atomic" "is.call" [4] "is.character" "is.complex" "is.data.frame" [7] "is.double" "is.element" "is.environment" [10] "is.expression" "is.factor" "is.finite" [13] "is.function" "is.infinite" "is.integer" [16] "is.language" "is.list" "is.loaded" [19] "is.logical" "is.matrix" "is.na" [22] "is.na.data.frame" "is.na.numeric_version" "is.na.POSIXlt" [25] "is.na<-" "is.na<-.default" "is.na<-.factor" [28] "is.na<-.numeric_version" "is.name" "is.nan" [31] "is.null" "is.numeric" "is.numeric_version" [34] "is.numeric.Date" "is.numeric.difftime" "is.numeric.POSIXt" [37] "is.object" "is.ordered" "is.package_version" [40] "is.pairlist" "is.primitive" "is.qr" [43] "is.R" "is.raw" "is.recursive" [46] "is.single" "is.symbol" "is.table" [49] "is.unsorted" "is.vector" "isatty" [52] "isBaseNamespace" "isdebugged" "isIncomplete" [55] "isNamespace" "isNamespaceLoaded" "isOpen" [58] "isRestart" "isS4" "isSeekable" [61] "isSymmetric" "isSymmetric.matrix" "isTRUE"
這裡我們是使用正規表示法(regular expression)列出 baseenv 這個基礎環境中所有 is 開頭的函數,這些細節在後面的教學中會陸續介紹。
數值變數的檢查函數常用的有 is.numeric、is.integer 與 is.double 這三個,is.numeric 對於整數或是浮點數都會傳回 TRUE:
is.numeric(1)
[1] TRUE
is.numeric(1L)
[1] TRUE
而 is.integer 只會對於整數傳回 TRUE:
is.integer(1)
[1] FALSE
is.integer(1L)
[1] TRUE
is.double 則是對於浮點數傳回 TRUE:
is.double(1)
[1] TRUE
is.double(1L)
[1] FALSE
變數轉型(Casting)
改變變數的類型稱為轉型(casting),在 R 中我們可以使用 as 來處理變數轉型的問題:
x <- "23.96"
as(x, "numeric")
[1] 23.96
而上述的各種 is.* 函數通常都會有對應的 as.* 函數,運用這類的函數會比一般的性的 as 更有效率:
as.numeric(x)
[1] 23.96
將數值向量轉換為 data frame:
y <- c(25, 53, 82, 33)
as.data.frame(y)
y 1 25 2 53 3 82 4 33
另外還有一種改變變數類型的方式,就是直接指定變數的類別名稱:
x <- "23.96"
class(x) <- "numeric"
x
[1] 23.96
is.numeric(x)
[1] TRUE
檢驗變數
這裡介紹一些在 R 中常用的變數檢視方式。
print 函數
當我們在 R 的命令列輸入運算式或變數名稱時,R 會自動輸出計算的結果,這是因為 R 自動呼叫變數所對應的 print 方法所導致的,也就是說執行
3 * 2
跟執行
print(3 * 2)
所做的動作是一樣的。但如果是在函數或迴圈當中,R 就不會自動呼叫 print 來輸出結果:
prime <- c(2, 3, 5, 7, 11, 13)
for (x in prime) {
x
}
如果我們需要在函數獲迴圈中輸出變數的值,就要明確呼叫 print 函數:
for (x in prime) {
print(x)
}
[1] 2 [1] 3 [1] 5 [1] 7 [1] 11 [1] 13
在
cat這個低階函數來輸出資料,cat函數通常只有在開發各種
summary 函數
除了直接輸出變數內容之外,我們也可以使用 summary 函數來檢視變數的基本統計量,幫助我們快速了解資料的分佈狀況,對於數值類的資料 summary 會計算平均值(mean)、中位數(median)、還有各個分位數(quantiles):
x <- rnorm(30)
summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max. -3.27700 -0.45780 0.02265 0.07430 0.92850 1.94900
這裡我們呼叫 rnorm 產生 30 筆標準常態分佈的資料,並使用 summary 來檢視資料的概況。
若遇到類別型的因子變數,summary 會計算每個值出現的次數:
y <- sample(c("A", "B", "C"), 30, replace = TRUE)
y.factor <- factor(y)
summary(y.factor)
A B C 9 7 14
這裡的我們使用 sample 函數對 c("A", "B", "C") 進行重複取樣,取出的樣本再轉換為因子變數,最後呼叫 summary 輸出每個字母出現的總數。
布林值的變數也是跟因子變數類似,同樣會輸出每個值出現的次數:
z <- sample(c(TRUE, FALSE, NA), 30, replace = TRUE)
summary(z)
Mode FALSE TRUE NA's logical 14 5 11
對於多維度的資料,summary 會對每個欄位的資料分別計算基本統計量,這裡我們使用上面建立好的三個變數組成一個 data frame:
xyz.df <- data.frame(x, y, z)
我們可以使用 head 查看 data frame 開頭的幾列資料,稍微瞭解一下原始資料的形式:
head(xyz.df)
x y z 1 0.80229870 C FALSE 2 0.97031534 C TRUE 3 0.97657093 A FALSE 4 1.26690080 C FALSE 5 0.41189886 A TRUE 6 -0.01411904 B NA
接著呼叫 summary:
summary(xyz.df)
x y z Min. :-3.27717 A: 9 Mode :logical 1st Qu.:-0.45777 B: 7 FALSE:14 Median : 0.02265 C:14 TRUE :5 Mean : 0.07430 NA's :11 3rd Qu.: 0.92848 Max. : 1.94892
str 函數
str 是一個用來檢視變數資料結構的函數,他會顯示變數的類型以及開頭的幾個值:
str(x)
num [1:30] 0.802 0.97 0.977 1.267 0.412 ...
str 特別適合用於檢視像 data frame 這類較複雜的變數:
str(xyz.df)
'data.frame': 30 obs. of 3 variables: $ x: num 0.802 0.97 0.977 1.267 0.412 ... $ y: Factor w/ 3 levels "A","B","C": 3 3 1 3 1 2 2 1 3 1 ... $ z: logi FALSE TRUE FALSE FALSE TRUE NA ...
變數內部結構
我們之前提過每一種變數都有對應的 print 函數,變數的內容會透過這些 print 函數的控制,進而將資料以適當(易讀)的方式輸出,有時候 print 會忽略一些變數內部的結構,只輸出資料本身的資訊,讓使用者更容易清楚地閱讀。
如果我們想要查看變數內部原始的資料結構,可以使用 unclass 函數將變數的類別屬性移除,使變數在輸出時跳過 print 函數的解析步驟,直接以原始的形式輸出:
unclass(y.factor)
[1] 3 3 1 3 1 2 2 1 3 1 2 1 2 1 3 3 1 3 2 2 3 3 3 2 3 3 1 3 3 1 attr(,"levels") [1] "A" "B" "C"
另外 attributes 函數也可以用來顯示變數的屬性:
attributes(y.factor)
$levels [1] "A" "B" "C" $class [1] "factor"
圖形介面工具
在 R 中如果要檢視二為的資料矩陣或 data frame,可以使用 View 這個工具(請注意 V 是大寫),它可以使用類似 Excel 試算表的方式呈現二維的資料:
View(xyz.df)
執行之後,會開啟這樣的視窗:
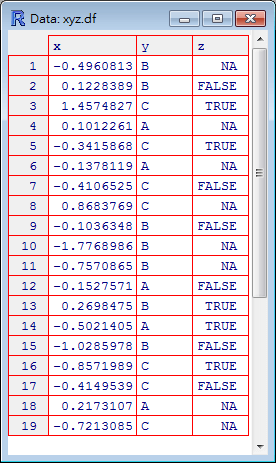
使用 View 所開啟的視窗只供使用者閱讀資料,無法直接修改,若要在上面直接修改資料,請改用 edit:
xyz.df.new <- edit(xyz.df)
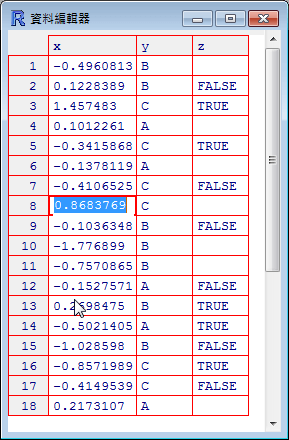
這樣在修改完之後,新的資料會儲存在 xyz.df.new 這個變數中,如果要直接修改原本的 xyz.df,可以使用 fix:
fix(xyz.df)
工作空間
在 R 的互動式環境下工作時,我們可以使用 ls 來列出目前已經被建立的變數名稱:
foo <- 3
bar <- "Hello World"
foo.bar <- 1:5
ls()
[1] "bar" "foo" "foo.bar"
ls 的 pattern 參數可以指定搜尋的關鍵字,篩選變數名稱:
ls(pattern = "foo")
[1] "foo" "foo.bar"
在預設的狀況下,ls 不會顯示以句點(.)開頭的隱藏變數(這跟 UNIX/Linux 系統上的規則相同),如果想要連同隱藏的變數一起列出來,可以加上 all.names = TRUE 參數:
.hide.var <- 23
ls()
[1] "bar" "foo" "foo.bar"
ls(all.names = TRUE)
[1] ".hide.var" "bar" "foo" "foo.bar"
ls.str 是結合 ls 與 str 的一個函數,可以列出各個變數的名稱與內部結構:
ls.str()
bar : chr "Hello World" foo : num 3 foo.bar : int [1:5] 1 2 3 4 5
browseEnv 可以在瀏覽器中顯示目前工作空間中的變數:
browseEnv()
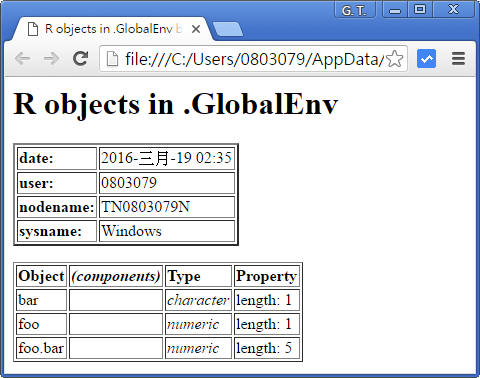
通常在 R 的環境下工作一段時間之後,會在工作空間中建立許多的變數,如果要刪除一些不再使用的變數,可以使用 rm 函數:
rm(bar, foo)
rm 可以配合 ls 將所有的變數一次刪除:
rm(list = ls())
補充資料
R 有四種區分變數類型的屬性,分別為類別(class)、類型(type)、模式(mode)與儲存模式(storage mode),大部分的狀況下我們只會使用到類別(class),遇到類別不敷使用時才會需要使用其他幾個屬性(例如區分陣列(array)的狀況),這時候就可以使用 is.numeric 這類的函數。
下表是 R 各種類型變數的類別(class)、類型(type)、模式(mode)與儲存模式(storage mode)的對應。
| 類別 | 類型 | 模式 | 儲存模式 | |
|---|---|---|---|---|
| Logical | logical | logical | logical | logical |
| Integer | integer | integer | numeric | integer |
| Floating Point | numeric | double | numeric | double |
| Complex | complex | complex | complex | complex |
| String | character | character | character | character |
| Raw Byte | raw | raw | raw | raw |
| Categorical | factor | integer | numeric | integer |
| Null | NULL | NULL | NULL | NULL |
| Logical Matrix | matrix | logical | logical | logical |
| Numeric Matrix | matrix | double | numeric | double |
| Character Matrix | matrix | character | character | character |
| Logical Array | array | logical | logical | logical |
| Numeric Array | array | double | numeric | double |
| Character Array | array | character | character | character |
| List | list | list | list | list |
| Data Frame | data.frame | list | list | list |
| Function | function | closure | function | function |
| Environment | environment | environment | environment | environment |
| Expression | expression | expression | expression | expression |
| Call | call | language | call | language |
| Formula | formula | language | call | language |