
R 是一個統計計算語言,雖然其功能強大,但是長久以來存在一個問題(也是所有高階語言共同的問題),就是程式執行的速度太慢,對於一些較耗時的程式,需要執行很久。
很幸運的,R 從 2.13 版開始加入了一個內建的標準套件 compiler,這個套件顧名思義就是可以將 R 的程式碼編譯後再執行,可增加執行的速度,因為使用方式非常簡單,程式設計者可以在幾乎不更動原始程式碼的情況下,讓程式的執行速度有明顯的提昇,這次的 2.13 版可能是 R 有史以來最有意義的一次更新。
下面是 R 官方 NEWS 中的敘述:
Package compiler is now provided as a standard package. See ?compiler::compile for information on how to use the compiler. This package implements a byte code compiler for R: by default the compiler is not used in this release. See the ‘R Installation and Administration Manual’ for how to compile the base and recommended packages.
依照這個敘述來看,這個編譯器可以將 R 的程式碼編譯成位元碼(byte code),但是目前這個編譯器還沒有被內建的基本套件使用,不過我們可以使用這個新套件來將我們自己寫的 R 程式編譯成位元碼,這樣可以非常輕鬆的提高程式的執行速度。這裡我們介紹如何使用 R 的編譯器來增加程式執行的效率,並測試各種情況下的執行速度。
使用 R 的 compiler 套件
首先定義一些測試用的函數:
f <- function(n, x=1) for (i in 1:n) x=1/(1+x)
g <- function(n, x=1) for (i in 1:n) x=(1/(1+x))
h <- function(n, x=1) for (i in 1:n) x=(1+x)^(-1)
j <- function(n, x=1) for (i in 1:n) x={1/{1+x}}
k <- function(n, x=1) for (i in 1:n) x=1/{1+x}
接下來先測試正常狀況執行速度,我們使用 rbenchmark 這個套件來測試,使用前要先安裝 rbenchmark 套件:
install.packages(c("inline", "Rcpp"))
接著使用 rbenchmark 來測試:
library(rbenchmark)
N <- 1e6
benchmark(f(N,1), g(N,1), h(N,1), j(N,1), k(N,1),
columns=c("test", "replications",
"elapsed", "relative"), order="relative",
replications=10)
這是測試的結果:
test replications elapsed relative 1 f(N, 1) 10 14.214 1.000000 5 k(N, 1) 10 14.262 1.003377 4 j(N, 1) 10 15.574 1.095680 2 g(N, 1) 10 16.308 1.147320 3 h(N, 1) 10 20.658 1.453356
接下來我們來測試加入 R 編譯器之後的效果,R 編譯器是在 2.13 版以後才有,所以若是您的 R 版本比較舊,就要先把 R 更新至 2.13 以後的版本才能使用編譯器。首先使用 cmpfun() 函數來將上面定義的函數進行編譯:
library(compiler)
lf <- cmpfun(f)
lg <- cmpfun(g)
lh <- cmpfun(h)
lj <- cmpfun(j)
lk <- cmpfun(k)
接著用 rbenchmark 來測試:
N <- 1e6
benchmark(f(N,1), g(N,1), h(N,1), j(N,1), k(N,1),
lf(N,1), lg(N,1), lh(N,1), lj(N,1), lk(N,1),
columns=c("test", "replications",
"elapsed", "relative"),
order="relative", replications=10)
這是測試的結果:
test replications elapsed relative 10 lk(N, 1) 10 5.447 1.000000 6 lf(N, 1) 10 5.530 1.015238 9 lj(N, 1) 10 5.541 1.017257 7 lg(N, 1) 10 5.567 1.022030 8 lh(N, 1) 10 7.332 1.346062 5 k(N, 1) 10 14.245 2.615201 1 f(N, 1) 10 14.490 2.660180 4 j(N, 1) 10 15.780 2.897008 2 g(N, 1) 10 16.484 3.026253 3 h(N, 1) 10 20.882 3.833670
從這個結果來看,編譯後再執行的執行的速度是沒有編譯的兩倍以上,看起來使用 R 編譯器將 R 的程式碼編譯成位元碼之後再執行,確實是可以明顯提高執行的速度,另外,因為程式碼寫法的不同所造成的執行效率差異,在編譯後也變小了,這樣的方式感覺很不錯,只需要對程式碼做非常少許的變動,就能明顯提高執行效率,對大多數的統計研究人員而言是一大福音。
使用 Rcpp 與 inline
介紹完 compiler 套件的用法,接下來我們來比較編譯成位元碼與機械碼的執行速度差異,在 compiler 套件問世之前,要加速 R 的執行速度都是使用 C 語言編寫程式較耗時的部份,再編譯成機械碼給 R 執行,使用前要先安裝 inline 與 Rcpp 套件:
install.packages(c("inline", "Rcpp"))
接下來就可以使用 C 語言編寫程式了,以下是使用 C 語言的版本,首先定義函數:
library(inline)
### and define our version in C++
src <- 'int n = as < int > (ns);
double x = as < double > (xs);
for (int i = 0; i < n; i++) x=1/(1+x);
return wrap(x); '
l <- cxxfunction(signature(ns="integer",
xs="numeric"),
body=src, plugin="Rcpp")
再用 rbenchmark 測試一次:
benchmark(f(N,1), g(N,1), h(N,1), j(N,1), k(N,1),
l(N,1),
lf(N,1), lg(N,1), lh(N,1), lj(N,1), lk(N,1),
columns=c("test", "replications",
"elapsed", "relative"),
order="relative", replications=10)
測試結果:
test replications elapsed relative 6 l(N, 1) 10 0.153 1.00000 7 lf(N, 1) 10 6.008 39.26797 10 lj(N, 1) 10 6.041 39.48366 8 lg(N, 1) 10 6.140 40.13072 11 lk(N, 1) 10 6.254 40.87582 9 lh(N, 1) 10 7.738 50.57516 5 k(N, 1) 10 14.885 97.28758 1 f(N, 1) 10 15.359 100.38562 4 j(N, 1) 10 16.405 107.22222 2 g(N, 1) 10 17.385 113.62745 3 h(N, 1) 10 22.045 144.08497
畫成圖形:
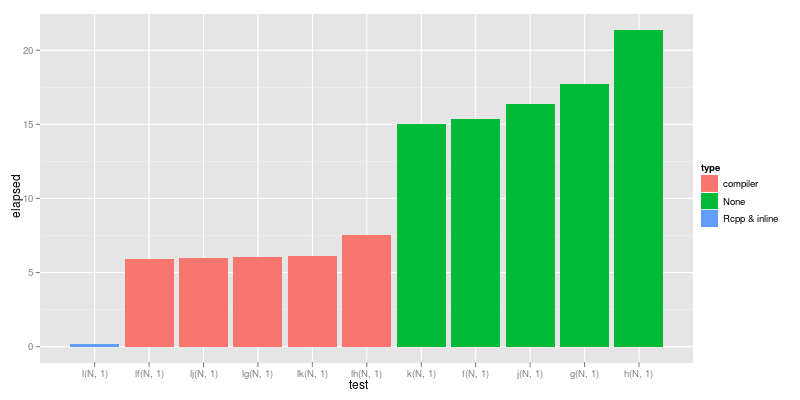
這個結果可以看出位元碼與機械碼之間的差異,大約相差 40 倍,比起原來的程式甚至有上百倍的差異,所以若是真的要算很久的程式,就可以考慮使用 C 語言的方式,當然若是只是算個幾分鐘就沒有必要花個幾十分鐘甚至幾小時來寫 C 語言的程式,直接編譯成位元碼執行就好了,改個幾小時的程式,加速之後其實只跑幾分鐘,其實反而更沒效率。
另外補充一點,這裡我們所拿來測試用的函數並不是真實的程式會用的函數,因為真的要算這樣的值不會用迴圈,直接用向量運算的方式會快很多,所以在實際的程式中,使用編譯器所提昇的執行度速可能不會像這個例子一樣這麼高。