各式圖形
qplot 可繪製的圖形並不限於簡單的散佈圖,其 geom 參數可以設定用來呈現資料所使用的幾何圖形,我們可以藉著調整此參數來做出各種變化,有些 geom 參數還會伴隨一些統計量的計算(例如顯示直方圖的同時也需要計算每個 bin 的統計量),以下是一些在呈現二維資料時比較常用的 geom 選項:
"point":使用點的方式呈現資料,這也是qplot在繪製二維資料時預設的方式。"smooth":以 smoother 配適資料,畫出平滑曲線與標準誤差(standard error)。"boxplot":以箱形圖呈現資料分佈情形。"path":以線段連接每一個資料點。"line":類似"path",但"line"只能產生由左至右的線段圖形。
對於一維的資料,常用的 "geom" 參數如下:
"histogram":直方圖,適用於連續型的資料,在資料是一維的情況下,預設會使用此方式。"freqpoly":類似直方圖,但以折線表示。"density":密度函數圖,適用於連續型的資料。"bar":長條圖,適用於離散型的類別資料。
在圖形上加入 Smoother
在資料點很多的二維圖形上,有時候不容易看出整體的資料趨勢,這時候可以加上一條平滑曲線幫助判讀。若要同時指定多種 geom,可以使用 c 函數來指定:
qplot(carat, price, data = diamonds.subset, geom = c("point", "smooth"))
qplot 在解讀 geom 參數時,若遇到多個幾何圖形,就會依照這裡指定的順序依序畫在圖形上:

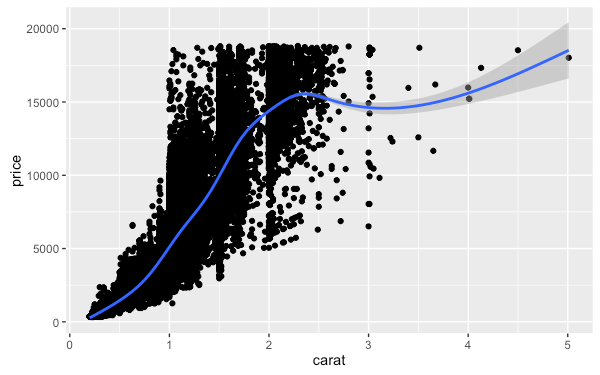
加入平滑曲線
qplot(carat, price, data = diamonds, geom = c("point", "smooth"))
箱形圖與 Jitter 資料點
當一組資料同時含有一個類別型的變數以及一個或多個連續型的變數時,資料分析者通常都會想要比較各類別中各連續型變數的分佈狀況,而最常用的圖形就是箱形圖:
qplot(color, price / carat, data = diamonds, geom = "boxplot")

箱形圖
箱形圖僅帶有 five numbers 的資訊,若想要看到更細部的資訊,可以使用 jitter 的方式繪製資料點,它可以將每一個資料點都畫出來:
qplot(color, price / carat, data = diamonds, geom = "jitter")

Jitter 資料點
在資料量太多的時候,可以使用透明度的技巧:
qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 5))

Jitter 資料點
qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 50))

Jitter 資料點
qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 200))

Jitter 資料點
以 jitter 的方式繪圖可以顯示資料分佈的細部資訊,彌補箱形圖的不足。以這個例子而言,雖然不同透明度的 jitter 資料點可以顯示資料集中的區域,不過箱形圖可能還是比較容易辨識。
以 jitter 繪製資料點時,可以同時配合散佈圖中的各種參數來調整圖形,例如:size、color 與 shape,而箱形圖也可以使用 color、fill 與 size 來調整顏色與線條粗細。
練習
# 以資料點的形狀區分 cut 變數 qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 5), shape = cut) # 以資料點的顏色區分 color 變數 qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 5), color = color) # 以資料點的顏色區分 cut 變數 qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 5), color = cut) # 以箱形圖的外框顏色區分 color 變數 qplot(color, price / carat, data = diamonds, geom = "boxplot", color = color) # 以箱形圖的內部顏色區分 color 變數 qplot(color, price / carat, data = diamonds, geom = "boxplot", fill = color) # 調整箱形圖的外框粗細 qplot(color, price / carat, data = diamonds, geom = "boxplot", size = I(2))
直方圖與密度函數
直方圖可以顯示一維資料的分佈狀況:
qplot(carat, data = diamonds, geom = "histogram")

直方圖
直方圖的 bin 寬度可以使用 binwidth 參數調整:
qplot(carat, data = diamonds, geom = "histogram", binwidth = 0.5, xlim = c(0, 3))

直方圖
某些資料的細部資訊可能要在 bin 的寬度非常小的情況下才會顯現出來:
qplot(carat, data = diamonds, geom = "histogram", binwidth = 0.01, xlim = c(0, 3))

直方圖
若要同時呈現多組資料、相互比較時,可以加上美學對應:
qplot(carat, data = diamonds, geom = "histogram", fill = color)

直方圖
當美學對應指定為一個類別型的變數時,會讓資料以此類別變數為依據區分為多個群組,所以 qplot 在這種狀況下就會用不同顏色畫出不同的鑽石顏色的資料,產生堆疊式的直方圖。
密度函數圖的作用也跟直方圖類似:
qplot(carat, data = diamonds, geom = "density")

密度函數圖
使用 adjust 參數調整密度函數圖的平滑程度,這個值越大則曲線越平滑,其效果類似直方圖的 bin 寬度:
qplot(carat, data = diamonds, geom = "density", adjust = 3)

密度函數圖
密度函數圖可以同時呈現多組資料的分佈:
qplot(carat, data = diamonds, geom = "density", color = color)

密度函數圖
在比較多組資料時,密度函數圖可能比較容易閱讀,不過這種圖形是假設資料本身是屬於無界(unbounded)的連續型資料,若資料的類型不屬於這種就要注意。
如果要將直方圖密度函數圖畫在一起,可將 y 軸的單位指定為密度,再畫出兩種圖形:
qplot(carat, ..density.., data = diamonds, geom = c("histogram", "density"))

直方圖密度函數圖
長條圖
長條圖跟直方圖類似,用於表示類別型的離散資料,在 ggplot 系統下使用 bar 這個 geom 繪製長條圖時,它會自動計算每個類別的數量,不需要像傳統的 barchart 一樣自行計算列聯表。如果您已經把列聯表算出來了,或是想要自行指定列聯表的計算方式,可以使用 weight 這個參數指定數值的來源。
qplot(color, data = diamonds, geom = "bar")

長條圖
qplot(color, data = diamonds, geom = "bar", weight = carat) + ylab("carat")

長條圖
時間序列與路徑
line 與 path 這兩種 geom 可以用來繪製時間序列與路徑類型的資料,path 會依據資料在 data frame 中的順序,將每一個點以線段連接起來,而 line 則是會將點的順序依據 x 軸座標來排序。通常 line 圖形的 x 軸是時間的資訊,用來呈現某個變數隨著時間的變化,而 path 則是用在比較兩個變數隨的時間變化的關係。
由於在 diamonds 資料集中沒有時間的資訊,我們改用 economics 這個資料集來示範,這個資料集包含了美國近 40 年的一些經濟發展相關數據。
unemploy 是失業人口,而 pop 則是人口總數,單位都是千人,相除之後即可計算失業率:
qplot(date, unemploy / pop, data = economics, geom = "line")

時間序列
uempmed 是失業時間的中位數,單位為週:
qplot(date, uempmed, data = economics, geom = "line")

時間序列
如果想要進一步細看失業率與失業時間之間的關係,最簡單的做法就是將這兩個數值用 x 與 y 的散佈圖畫出來,不過這樣的缺點就是無法看出時間上的資訊,另外一種畫法是使用 path 的方式依據時間把每個點連接起來:
qplot(unemploy / pop, uempmed, data = economics, geom = c("point", "path"))

路徑
為了讓時間的資訊更容易辨識,可以再加上顏色來表示不同的年份:
year <- function(x) as.POSIXlt(x)$year + 1900 qplot(unemploy / pop, uempmed, data = economics, geom = "path", colour = year(date))

路徑
從這樣的圖形上可以看得出來,失業率與失業時間之前呈現高度的正相關,而且最近幾年在相同失業率的狀況下,失業時間中位數比以往更高。
對於多個個體的時間序列資料,我們可能會需要在一張圖形上畫出好多條線,每一條線代表一個個體,以利互相比較,這種狀況則可使用 group 這個美學對應。