本篇介紹如何在 TensorFlow 中以輸入管線讀取任意格式的檔案,並提供 Python 的範例程式碼。
在 TensorFlow 中總共有三種讀取資料的方式,在之前的 TensorFlow 入門教學文章中,我們已經使用過 placeholder 與常數這兩種比較簡單的方式,這裡將介紹第三種輸入管線的方式。
TensorFlow 的輸入管線(input pipeline)是一個從檔案讀取資料的流程,使用者可以自行建立符合自己需求的管線,讀取較大量的資料。
在 TensorFlow 中以輸入管線的方式從檔案讀取資料時,流程通常包含以下幾個步驟:
- 提供檔案名稱。
- 打散檔案名稱。(可省略)
- 設定 epoch 限制。(可省略)
- 建立檔案名稱佇列(filename queue)。
- 根據檔案格式,建立檔案讀取器。
- 根據資料格式,建立資料解析器。
- 資料前處理。(可省略)
- 建立資料佇列。
讀取 CSV 檔案
以下我們以一個讀取 CSV 檔案的範例進行說明,建立一個基本的輸入管線。
準備檔案名稱
首先要準備 CSV 檔案的名稱,通常大量的資料都會分散成好多的檔案來儲存,這裡我們要依照自己的檔名規則,產生檔案的總表。檔案總表的產生方式可以使用直接列出的方式:
["file0", "file1"]
或是使用 for 迴圈來產生:
[("file%d" % i) for i in range(2)]
或是使用 tf.train.match_filenames_once 函數來依照關鍵字自動抓取。
建立檔名佇列
有了所有的檔案名稱之後,接著把檔名總表傳入 tf.train.string_input_producer 函數,建立檔案名稱佇列(queue):
# 建立檔名佇列
filename_queue = tf.train.string_input_producer(
["file0.csv", "file1.csv"])
tf.train.string_input_producer 會建立一個先進先出(FIFO)的佇列用於存放檔案名稱,提供檔名給檔案讀取器來使用。
tf.train.string_input_producer 的 shuffle 參數可以設定是否要將檔名打散(隨機排序),而 num_epochs 參數則可用來設定 epoch 的上限值。
佇列執行器(queue runner)會依照這裡的設定,在每一次的 epoch 將所有的檔名打散後(若 shuffle=True)放入檔名佇列,這種做法讓檔名的抽樣過程都保持一致,可避免 under-sampling 或 over-sampling 的問題。
佇列執行器會以一個獨立的執行緒(thread)來執行,所以打散檔名以及放入檔名佇列的過程不會影響到檔案讀取器的效能。
讀取檔案
根據自己的檔案格式,選擇一個適合的檔案讀取器,這裡我們要讀取的檔案是 CSV 檔,這種檔案的資料格式是一行一筆資料,所以適合使用 tf.TextLineReader 這個讀取器。
將建立好的檔名佇列傳入讀取器:
# 選擇讀取器
reader = tf.TextLineReader()
# 讀取檔案
key, value = reader.read(filename_queue)
讀取器在讀取資料後,會傳回一個用來辨識檔案與資料的 key 值(可用於除錯),還有一行實際的資料 value。
處理資料
將檔案中的資料讀取進來之後,接著要進行資料解析與前處理的動作,將文字的資料轉換為 tensor,這樣才能放入 TensorFlow 中使用。
CSV 的資料我們可以使用 tf.decode_csv 這個解析器,它可以把 CSV 的文字資料轉為一連串的 tensors:
# 設定每個欄位預設的值以及資料類型
record_defaults = [[1], [1], [1], [1], [1]]
# 解析 CSV 資料
col1, col2, col3, col4, col5 = tf.decode_csv(
value, record_defaults=record_defaults)
# 把 CSV 資料的前四欄打包成一個 tensor
features = tf.pack([col1, col2, col3, col4])
tf.decode_csv 在使用時要以 record_defaults 參數指定每個欄位預設的值以及資料類型,這樣才能進行正確的資料解析。
執行
建立好整個資料的輸入管線之後,最後就是要建立一個 session 來實際執行所有的動作,而在實際讀取資料前,要先在另外一個執行緒中啟動佇列執行器,才能讀取資料:
# 建立 session
with tf.Session() as sess:
# 建立 Coordinator
coord = tf.train.Coordinator()
# 啟動佇列執行器
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
# 讀取一筆資料
example, label = sess.run([features, col5])
# 結束 Coordinator
coord.request_stop()
coord.join(threads)
如果沒有啟動佇列執行器的話,檔名佇列中沒有檔名可用,在讀取資料時就會卡住。
固定長度資料
若要讀取二進位(binary)的資料,可以使用 tf.FixedLengthRecordReader 函數配合 tf.decode_raw 來解析,tf.decode_raw 會將文字資料轉換為 uint8 的 tensor。
CIFAR-10 資料集就是一個二進位資料,它以一個位元組(byte)儲存圖片標示(label),然後以 3072 個位元組儲存圖片資料。
TensorFlow 標準資料格式
我們也可以直接把自己的資料轉為 TensorFlow 的標準資料格式,這樣對於結合各種資料時會更方便。
TensorFlow 建議使用的標準資料格式為 TFRecords 檔案,其包含 tf.train.Example,內部為 Features。
我們可以用 f.python_io.TFRecordWriter 寫一個小程式,把自己的資料塞進 tf.train.Example,然後寫入 TFRecords 檔案中,這部分可參考 MNIST 轉換為 TFRecords 檔案的範例。
若要讀取 TFRecords 檔案,可以使用 tf.TFRecordReader 配合 tf.parse_single_example 解析資料,parse_single_example 可將 tf.train.Example 轉換為 tensors。
資料前處理
資料前處理包含資料的整理、標準化、抽樣等各種與模型訓練參數無關的動作,這部分可參考 [CIFAR-10 的資料輸入範例][10]。
批次處理
在輸入管線後方通常會接上另一個佇列,將資料分批已進行後續的處理(例如訓練模型、驗證與預測),tf.train.shuffle_batch 這一個佇列會自動將資料的順序打散,以下是一個簡單的使用範例。
# 自行定義的讀與檔案函數
def read_my_file_format(filename_queue):
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
# 將資料打散,分批處理
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue 指定打散資料用的緩衝區大小,
# 這個值越大代表資料打散資料的效果越好,
# 不過值越大則啟動準備時間較長,記憶體用量也較大
min_after_dequeue = 10000
# capacity 一定要比 min_after_dequeue 更大一些,
# 多出來的部分可用於預先載入資料,建議值為:
# min_after_dequeue + (num_threads + a small safety margin) * batch_size
capacity = min_after_dequeue + 3 * batch_size
# 使用 tf.train.shuffle_batch 將資料打散並分批處理
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
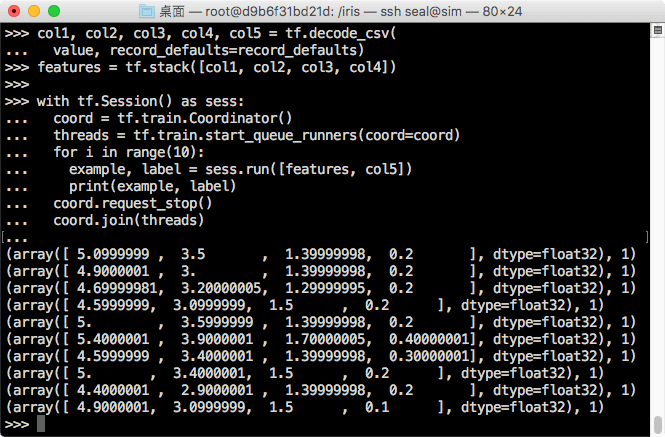
實際範例
這裡我拿鳶尾花資料集來製作一個簡單的範例,CSV 檔的格式如下:
5.1,3.5,1.4,0.2,1 4.9,3,1.4,0.2,1 4.7,3.2,1.3,0.2,1 4.6,3.1,1.5,0.2,1 [略]
我將三種花的資料分別分成 iris1.csv、iris2.csv 與 iris3.csv 這三個檔案來儲存,以下是使用輸入管線讀取 CSV 黨的程式碼。
import tensorflow as tf
filename_queue = tf.train.string_input_producer(
["iris1.csv", "iris2.csv", "iris3.csv"])
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [[0.0], [0.0], [0.0], [0.0], []]
col1, col2, col3, col4, col5 = tf.decode_csv(
value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4])
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
example, label = sess.run([features, col5])
print(example, label)
coord.request_stop()
coord.join(threads)
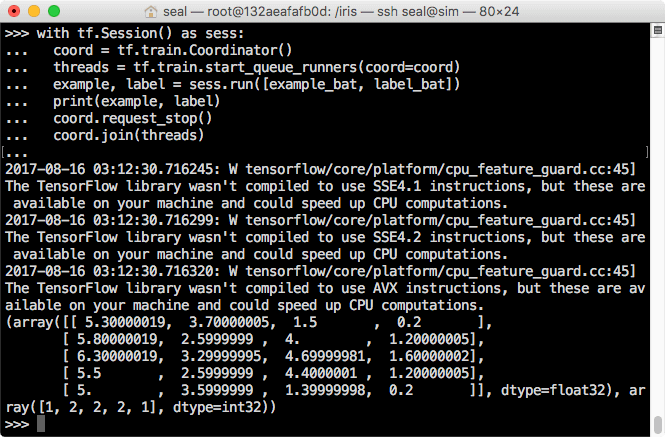
批次處理範例
這是以批次處理的方式讀取鳶尾花資料的範例程式碼:
import tensorflow as tf
def read_my_file_format(filename_queue):
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [[0.0], [0.0], [0.0], [0.0], []]
col1, col2, col3, col4, col5 = tf.decode_csv(
value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4])
return features, col5
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
filenames = ["iris1.csv", "iris2.csv", "iris3.csv"]
example_bat, label_bat = input_pipeline(filenames, 5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
example, label = sess.run([example_bat, label_bat])
print(example, label)
coord.request_stop()
coord.join(threads)