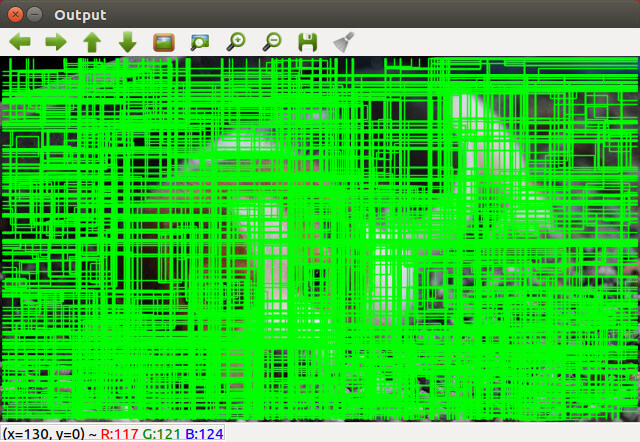
本篇介紹如何在 OpenCV 中實作 Selective Search 物體偵測候選區域演算法。
初版的 R-CNN 是將 Selective Search 所得到的候選區域,放進 CNN 中進行判斷,為了更清楚理解 Selective Search 的運作,以下我們直接使用 OpenCV 來撰寫一個 Selective Search 的實作版本,觀察該演算法實際執行的結果。
Selective Search 理論
Selective Search 的理論概念就是使用圖像分割(segmentation)後的結果,套用階層群聚演算法(hierarchical grouping algorithm),產生物體的候選區域(object proposal),最後再用 SVM 辨識物體。

(b) 中的兩隻貓可以使用顏色區分,但是去無法使用紋理區分。(c) 中的變色龍可以使用紋理區分,但是卻無法使用顏色區分。(d) 中的車子與輪胎顏色與紋理皆不同,但是由於形狀吻合度很高,所以可以視為一體。從這些角度來看,要找出各種物體的話,需要結合多種不同的特徵才能達成。另外在 (a) 中的桌面上有一個碗,碗中有湯匙,這說明了一般的物體本質上就具有階層式的結構,無法使用單一尺度就涵蓋這些物體。
多尺度(Multiscale)設計概念
由於物體之間存在階層關係,在圖片中的大小也不確定,所以 Selective Search 在搜尋時會考慮所有大小的區域。下圖中我們可以在不同尺度下捕捉到不同的物體。
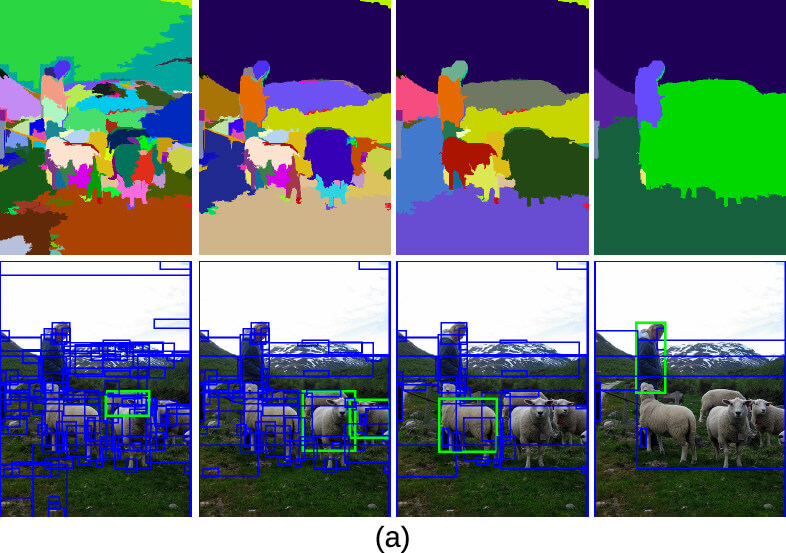
下圖也是一個不同尺度下捕捉到不同物體的例子。

階層群聚演算法
Selective Search 使用階層群聚演算法,以 Graph Based Segmentation(實作可參考實作 Graph Based Segmentation 圖形分割演算法)的結果為基礎,進行階層式的合併,然後產生最後的候選區域,演算法的流程如下。

這裡比較需要注意的地方就是兩個區域的相似度 \(s(r_i, r_j)\) 該如何計算,由於計算效能的考量,我們在設計這個函數時最好可以讓 \(r_i\) 與 \(r_j\) 兩個區域在合併成 \(r_t\) 之後,在後續計算相似度時,可以不需要重新以個別像素做計算。
相似度計算法
由於影像的特徵有很多種,我們無法使用單一特徵來處理所有的情況,這篇文章依據四種特徵來計算不同區域的相似度。
顏色相似度
對於每個區域先計算色彩的分佈直方圖(color histogram),RGB 每個色彩各取 25 個 bins,經過 \(L_1\) norm 標準化,因此每個 \(r_i\) 可以得到 \(C_i={c_i^1,...,c_i^n}\),,而當 RGB 三個色彩都使用時,\(n\) 就會等於 75。
而 \(r_i\) 與 \(r_j\) 之間的顏色相似度定義為:
\[s_{colour}(r_i,r_j)=\sum_{k=1}^nmin(c_i^k,c_j^k)\]這樣定義出來的顏色相似度在區域合併時也可以很輕易地計算出新的顏色相似度。
紋理相似度
這裡採用 SIFT-Like 的方式來衡量紋理(請參考 Exploring Features in a Bayesian Framework for Material Recognition),對每個顏色 channel 計算八個不同方向 \(sigma=1\) 的高斯微分(Gaussian derivatives),每個顏色與方向分別計算出 10 個 bins 的直方圖(\(L_1\) norm 標準化),可得到 \(r_i\) 區域的紋理的特徵直方圖 \(T_i={t_i^1,...,t_i^n}\),這裡的 \(n\) 等於 240。
而 (r_i) 與 (r_j) 之間的紋理相似度定義為:
\[s_{texture}(r_i,r_j)=\sum_{k=1}^nmin(t_i^k,t_j^k)\]大小相似度
為了讓區域合併的過程可以比較均勻,在合併的過程才能有效涵蓋各種大小的物體,避免一個大區域吃掉所有的小區域,所以在定義大小相似度時會讓小的區域比較相似。
\(r_i\) 與 \(r_j\) 之間的大小相似度定義為:
\[s_{size}(r_i,r_j)=1-\frac{size(r_i)+size(r_j)}{size(im)}\]其中 \(size(im)\) 代表整張圖形的大小(像素數量)。
形狀吻合相似度
如果一個區域 \(r_i\) 包含另一個區域 \(r_j\),則將這兩個區域先進行合併可以避免區域呈現空洞的狀況,反之若兩個區域不相交,就比較可能是兩個不同的物體,不應當合併。
為了計算方便,我們只考慮區域的像素數量,假設 \(BB_{ij}\) 是 \(r_i\) 與 \(r_j\) 的 bounding box,則 \(r_i\) 與 \(r_j\) 之間的形狀吻合相似度定義為:
\[s_{fill}(r_i,r_j)=1-\frac{size(BB_{ij})-size(r_i)-size(r_j)}{size(im)}\]綜合相似度
結合以上四種相似度,定義出這篇論文所使用的綜合相似度:
\[ \begin{aligned} s(r_i,r_j) = &a_1s_{colour}(r_i,r_j) + a_2s_{texture}(r_i,r_j) +\\ &a_3s_{size}(r_i,r_j) + a_4s_{fill}(r_i,r_j) \end{aligned} \]其中 \(a_i \in \{0,1\}\),代表是否要使用對應的相似度。
有個相似度的定義之後,就可以使用階層群聚演算法,產生出候選區域,接著放進 SVM 中訓練,而這裡我們的重點只在於產生候選區域,SVM 的部分就省略了。
安裝 OpenCV
OpenCV 的 Selective Search 功能放在 OpenCV contrib 當中,請參考 Graph Based Segmentation 圖形分割演算法的文章,將 OpenCV 與 contrib 額外模組都一起裝起來。
實作 Selective Search
以下是一個使用 OpenCV 實作 Selective Search 的範例程式,程式會讀取 image.jpg 這個圖檔,進行 Selective Search 之後,將結果顯示在圖形視窗中。
import cv2
# 讀取圖檔
im = cv2.imread('image.jpg')
# 建立 Selective Search 分割器
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
# 設定要進行分割的圖形
ss.setBaseImage(im)
# 使用快速模式(精準度較差)
ss.switchToSelectiveSearchFast()
# 使用精準模式(速度較慢)
# ss.switchToSelectiveSearchQuality()
# 執行 Selective Search 分割
rects = ss.process()
print('候選區域總數量: {}'.format(len(rects)))
# 要顯示的候選區域數量
numShowRects = 100
# 每次增加或減少顯示的候選區域數量
increment = 50
while True:
# 複製一份原始影像
imOut = im.copy()
# 以迴圈處理每一個候選區域
for i, rect in enumerate(rects):
# 以方框標示候選區域
if (i < numShowRects):
x, y, w, h = rect
cv2.rectangle(imOut, (x, y), (x+w, y+h), (0, 255, 0), 1, cv2.LINE_AA)
else:
break
# 顯示結果
cv2.imshow("Output", imOut)
# 讀取使用者所按下的鍵
k = cv2.waitKey() & 0xFF
# 若按下 m 鍵,則增加 numShowRects
if k == 109:
numShowRects += increment
# 若按下 l 鍵,則減少 numShowRects
elif k == 108 and numShowRects > increment:
numShowRects -= increment
# 若按下 q 鍵,則離開
elif k == 113:
break
# 關閉圖形顯示視窗
cv2.destroyAllWindows()
由於 Selective Search 所得到的候選區域非常多,為了方便觀看處理結果,一開始只顯示一部分的區域:
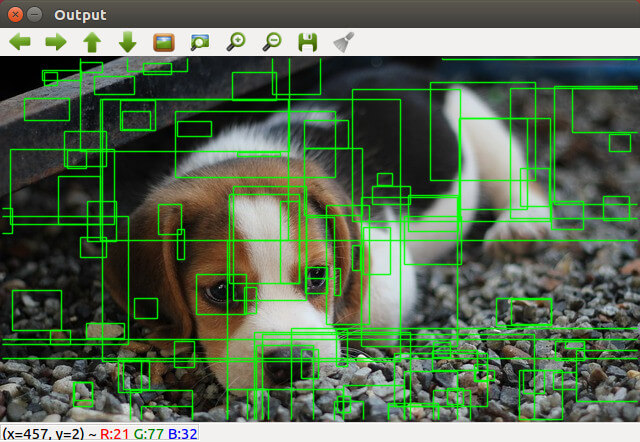
若要看更多個候選區域,則可按 m 鍵,若要減少顯示的候選區域,則按 l 鍵。