這裡介紹如何使用 RabbitMQ 實作工作佇列(work queues),將耗時的工作分配至多個 works 來處理。
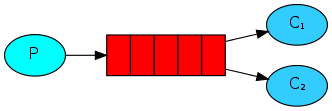
在上一個 RabbitMQ 訊息佇列教學中,我們實作一個可以透過 queue 傳送與接收訊息的簡單架構,這裡我們將繼續修改之前的範例程式碼,加入工作處理的功能。
工作佇列(work queues,又名 task queues)主要的概念就是將耗時的工作放在後端進行排程處理,不要讓前端的應用程式或使用者一直等待。這裡我們將工作包裝成訊息的格式,透過 work queue 傳遞給後方的 worker 處理,如果同時有很多工作產生時,我們還可以建立多個 workers 一起分攤這些工作。
這樣的做法對於網頁應用程式十分有用,當一個工作無法在一個 HTTP 請求所容許的短暫時間內完成時,就可以改用這樣的方式。
模擬耗時工作
之前的範例程式中,我們只是單純傳送一個 "Hello World!" 字串,而現在我們要傳送一個代表耗時工作的文字訊息,這裡為了方便示範,我們會呼叫 time.sleep() 函數來模擬耗時工作的處理過程,而工作所耗費的時間則使用訊息中的句點數目來代表,一個句點代表使用一秒的時間,例如 "Hello..." 就是一個耗費 3 秒的工作。
首先修改之前的 send.py 程式碼,讓它執行時可以指定送出的訊息,並將新的指令稿命名為 new_task.py:
import sys message = ' '.join(sys.argv[1:]) or "Hello World!" channel.basic_publish(exchange='', routing_key='hello', body=message) print " [x] Sent %r" % (message,)
之後我們會使用 new_task.py 將工作放進 work queue 中進行排程處理。
另外在 receive.py 的部分,也要做一些修改,讓它可以解析 new_task.py 所產生的訊息內容,模擬工作的處理(每個句點花費一秒),我們將新的指令稿命名為 worker.py:
import time def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done"
Round-robin
使用工作佇列的其中一個好處就是可以很容易的平行處理多項工作,當工作量增加時,只要加入新的 worker 即可立即分擔整個系統的負載,擴充非常方便。
首先在兩個 shell 中分別執行 worker.py,建立兩個 workers:
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
然後在開啟另外一個 shell,執行 new_task.py 送出多個代表耗時工作的訊息:
shell3$ python new_task.py First message. shell3$ python new_task.py Second message.. shell3$ python new_task.py Third message... shell3$ python new_task.py Fourth message.... shell3$ python new_task.py Fifth message.....
這時候,在 shell1 的 worker 輸出為:
[x] Received ‘First message.’
[x] Received ‘Third message…’
[x] Received ‘Fifth message…..’
而 shell2 的 worker 輸出為:
[x] Received ‘Second message..’
[x] Received ‘Fourth message….’
在預設的狀況下,RabbitMQ 會將訊息依序輪流配送至每一個 consumer,平均來說每一個 consumer 會收到相同數量的訊息,這樣的配送方式稱為 round-robin,你可以嘗試加入更多的 worker 測試看看。
訊息確認(Message Acknowledgment)
依據目前我們實作的程式碼,RabbitMQ 將工作交給 worker 之後並不會將訊息內容保留下來,全部的處理責任都落在 worker 身上,處理耗時的工作有可能會花費很久的時間,萬一在處理的期間 worker 發生問題沒有將工作處理完成,那麼該項工作就會出問題,而 RabbitMQ 也無從追蹤或重新派送。
如果要監控每一個派送出去的工作,可以藉由 RabbitMQ 的訊息確認(message acknowledgment)的功能來達成,consumer 可以使用這個方式告知 RabbitMQ 各種資訊,例如某個訊息是否已接收到或是已經處理完成等,讓 RabbitMQ 可以在確認工作都正常完成後,再刪除 queue 中的訊息。
如果某一個 consumer 處理到一半出問題,導致 RabbitMQ 收不到確認訊息,這樣的狀況 RabbitMQ 就可以將工作改送給其他的 worker 來處理,避免該項工作整個遺失。而 RabbitMQ 只有在 worker 連線中斷時,才會嘗試改送給其他的 worker,沒有預設的逾時(timeout)設定,所以即使工作需要很長的時間來處理也沒有問題。
訊息確認的功能預設就已經開啟了,不過之前的範例中我們沒有使用,只是單純將他指定為 no_ack=True,現在我們將這部分修改一下:
def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue='hello')
這樣一來,當有 worker 突然出問題時,RabbitMQ 就會將為處理完成的工作送給其他的 worker 來處理,你可以在 worker.py 執行到一半時,按下 Ctrl + c 測試看看。
這裡要注意不要忘記加上 basic_ack,如果沒有加上這一行,RabbitMQ 就會無法掌控該工作到底有沒有完成,因此就永遠無法刪除該訊息,時間一久也會造成記憶體用量不斷累積。如果要針對這類的問題除錯,可以使用 rabbitmqctl 將 messages_unacknowledged 欄位印出欄看看:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Listing queues …
hello 0 0
…done.
訊息的續航力(Message Durability)
在上面的教學中,我們已經可以確保在 consumer 出問題時,未處理完成的工作不會遺失,但是如果 RabbitMQ 伺服器出問題時,在伺服器上的排程等待的工作一樣會不見。
在預設的情況下,當 RabbitMQ 伺服器關閉或是 crash 之後,所有的佇列與訊息也都會消失,如果想要讓 RabbitMQ 可以持續保留佇列與訊息,可以將佇列與訊息都設定為 durable,這樣 RabbitMQ 就會自動將它們保留下來。
durable 佇列的設定方式為:
channel.queue_declare(queue='hello', durable=True)
基本上這樣就可以了,但是由於我們之前已經建立了一個名為 hello 的佇列,RabbitMQ 不允許相同的佇列名稱卻以不同的參數設定重複建立,所以我們在這裡我們將新的佇列更名為 task_queue:
channel.queue_declare(queue='task_queue', durable=True)
更改佇列名稱記得要同時套用至 producer 與 consumer 的程式碼中。
設定好佇列之後,接著再把訊息設定成 persistent,讓訊息也可以保留下來:
channel.basic_publish(
exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
這裡我們將訊息設定為 persistent 其實也並不能完全保證每一條訊息都不會遺失,因為 RabbitMQ 雖然會將每一條訊息都儲存在硬碟中,但是如果 RabbitMQ 出問題的時間點,剛好落在接收訊息之後與寫入硬碟之前這段短暫的時間內,那麼該訊息就無法被保留下來,而且 RabbitMQ 並不會針對每一條訊息呼叫 fsync,所以也很可能有些訊息是寫在緩衝區中,而沒有實際被寫入硬碟。
Fair Dispatch
上面我們以 round-robin 的方式分配工作,因為每一件工作所需要的處理時間都不同,有時候會讓工作量分配不平均,造成有些 worker 的負載很重,而有些 worker 卻很輕。

為了可以讓每個 worker 能夠平均分擔所有的工作,我們可以使用 basic.qos 設定 prefetch_count=1,告知 RabbitMQ 一次指派送一個工作給一個 worker,也就是說 RabbitMQ 只會將工作派送給閒置的 worker 來處理,如果一個 worker 正在處理某一項工作,那麼 RabbitMQ 會等收到該項工作的完成確認訊息之後,才會再配送下一個工作給這個 worker。
channel.basic_qos(prefetch_count=1)
在這樣的狀況下,使用者必須注意 workers 的數量是否足以消化佇列中所有的工作,如果工作產生的速度遠大於 workers 消化的速度,整個佇列可能會被塞滿,這時候就要增加一些 workers 或是更改架構的設計。
完整的程式碼
以下是 new_task.py 的完整程式碼:
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) message = ' '.join(sys.argv[1:]) or "Hello World!" channel.basic_publish( exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent )) print " [x] Sent %r" % (message,) connection.close()
以下則是 worker.py 的完整程式碼:
#!/usr/bin/env python import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) print ' [*] Waiting for messages. To exit press CTRL+C' def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue='task_queue') channel.start_consuming()
繼續閱讀:以 RabbitMQ 實作 Publish/Subscribe 模型(Python 版本)