這裡介紹如何使用 Python 的 Beautiful Soup 模組自動下載並解析網頁資料,開發典型的網路爬蟲程式。
Beautiful Soup 是一個 Python 的函式庫模組,可以讓開發者僅須撰寫非常少量的程式碼,就可以快速解析網頁 HTML 碼,從中翠取出使用者有興趣的資料、去蕪存菁,降低網路爬蟲程式的開發門檻、加快程式撰寫速度。
Beautiful Soup 這套模組的網頁結構搜尋與萃取功能相當完整,這裡我們只介紹比較常用的幾種功能,更詳細的用法請參考 Beautiful Soup 官方的說明文件。
安裝 Beautiful Soup
Beautiful Soup 可以使用 pip 安裝:
# 安裝 Python 2 的 Beautiful Soup 4 模組
pip install beautifulsoup4
# 安裝 Python 3 的 Beautiful Soup 4 模組
pip3 install beautifulsoup4
在 Ubuntu Linux 中亦可使用 apt 安裝:
# 安裝 Python 2 的 Beautiful Soup 4 模組
sudo apt-get install python-bs4
# 安裝 Python 3 的 Beautiful Soup 4 模組
sudo apt-get install python3-bs4
Beautiful Soup 基本用法
Beautiful Soup 的運作方式就是讀取 HTML 原始碼,自動進行解析並產生一個 BeautifulSoup 物件,此物件中包含了整個 HTML 文件的結構樹,有了這個結構樹之後,就可以輕鬆找出任何有興趣的資料了。
以下是一個簡單的小程式,示範如何使用 Beautiful Soup 模組解析原始的 HTML 程式碼:
# 引入 Beautiful Soup 模組
from bs4 import BeautifulSoup
# 原始 HTML 程式碼
html_doc = """
<html><head><title>Hello World</title></head>
<body><h2>Test Header</h2>
<p>This is a test.</p>
<a id="link1" href="/my_link1">Link 1</a>
<a id="link2" href="/my_link2">Link 2</a>
<p>Hello, <b class="boldtext">Bold Text</b></p>
</body></html>
"""
# 以 Beautiful Soup 解析 HTML 程式碼
soup = BeautifulSoup(html_doc, 'html.parser')
這裡的 soup 就是解析完成後,所產生的結構樹物件,接下來所有資料的搜尋、萃取等操作都會透過這個物件來進行。
首先我們可以將完整個 HTML 結構經過排版後輸出,觀察整份文件的輪廓:
# 輸出排版後的 HTML 程式碼
print(soup.prettify())
<html>
<head>
<title>
Hello World
</title>
</head>
<body>
<h2>
Test Header
</h2>
<p>
This is a test.
</p>
<a href="/my_link1" id="link1">
Link 1
</a>
<a href="/my_link2" id="link2">
Link 2
</a>
<p>
Hello,
<b class="boldtext">
Bold Text
</b>
</p>
</body>
</html>取得節點文字內容
若要輸出網頁標題的 HTML 標籤,可以直接指定網頁標題標籤的名稱(title),即可將該標籤的節點抓出來:
# 網頁標題 HTML 標籤
title_tag = soup.title
print(title_tag)
<title>Hello World</title>
HTML 標籤節點的文字內容,可以透過 string 屬性存取:
# 網頁的標題文字
print(title_tag.string)
Hello World
搜尋節點
我們可以使用 find_all 找出所有特定的 HTML 標籤節點,再以 Python 的迴圈來依序輸出每個超連結的文字:
# 所有的超連結
a_tags = soup.find_all('a')
for tag in a_tags:
# 輸出超連結的文字
print(tag.string)
Link 1 Link 2
取出節點屬性
若要取出 HTML 節點的各種屬性,可以使用 get,例如輸出每個超連結的網址(href 屬性):
for tag in a_tags:
# 輸出超連結網址
print(tag.get('href'))
/my_link1 /my_link2
同時搜尋多種標籤
若要同時搜尋多種 HTML 標籤,可以使用 list 來指定所有的要列出的 HTML 標籤名稱:
# 搜尋所有超連結與粗體字
tags = soup.find_all(["a", "b"])
print(tags)
[<a href="/my_link1" id="link1">Link 1</a>, <a href="/my_link2" id="link2">Link 2</a>, <b class="boldtext">Bold Text</b>]
限制搜尋節點數量
find_all 預設會輸出所有符合條件的節點,但若是遇到節點數量很多的時候,就會需要比較久的計算時間,如果我們不需要所有符合條件的節點,可以用 limit 參數指定搜尋節點數量的上限值,這樣它就只會找出前幾個符合條件的節點:
# 限制搜尋結果數量
tags = soup.find_all(["a", "b"], limit=2)
print(tags)
[<a href="/my_link1" id="link1">Link 1</a>, <a href="/my_link2" id="link2">Link 2</a>]
如果只需要抓出第一個符合條件的節點,可以直接使用 find:
# 只抓出第一個符合條件的節點
a_tag = soup.find("a")
print(a_tag)
<a href="/my_link1" id="link1">Link 1</a>
遞迴搜尋
預設的狀況下,find_all 會以遞迴的方式尋找所有的子節點:
# 預設會以遞迴搜尋
soup.html.find_all("title")
[<title>Hello World</title>]
如果想要限制 find_all 只找尋次一層的子節點,可以加上 recursive=False 關閉遞迴搜尋功能:
# 不使用遞迴搜尋,僅尋找次一層的子節點
soup.html.find_all("title", recursive=False)
[]
接下來我們要介紹一些更詳細的使用方式。
以 HTML 屬性搜尋
我們也可以根據網頁 HTML 元素的屬性來萃取指定的 HTML 節點,例如搜尋 id 屬性為 link2 的節點:
# 根據 id 搜尋
link2_tag = soup.find(id='link2')
print(link2_tag)
<a href="/my_link2" id="link2">Link 2</a>
我們可以結合 HTML 節點的名稱與屬性進行更精確的搜尋,例如搜尋 href 屬性為 /my_link1 的 a 節點:
# 搜尋 href 屬性為 /my_link1 的 a 節點
a_tag = soup.find_all("a", href="/my_link1")
print(a_tag)
[<a href="/my_link1" id="link1">Link 1</a>]
搜尋屬性時,也可以使用正規表示法,例如以正規表示法比對超連結網址:
import re
# 以正規表示法比對超連結網址
links = soup.find_all(href=re.compile("^/my_linkd"))
print(links)
[<a href="/my_link1" id="link1">Link 1</a>, <a href="/my_link2" id="link2">Link 2</a>]
我們也可以同時使用多個屬性的條件進行篩選:
# 以多個屬性條件來篩選
link = soup.find_all(href=re.compile("^/my_linkd"), id="link1")
print(link)
[<a href="/my_link1" id="link1">Link 1</a>]
在 HTML5 中有一些屬性名稱若直接寫在 Python 的參數中會有一些問題,例如 data-* 這類的屬性直接寫的話,就會產生錯誤訊息:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>', 'html.parser')
# 錯誤的用法
data_soup.find_all(data-foo="value")
SyntaxError: keyword can't be an expression
遇到這種狀況,可以把屬性的名稱與值放進一個 dictionary 中,再將此 dictionary 指定給 attrs 參數即可:
# 正確的用法
data_soup.find_all(attrs={"data-foo": "value"})
[<div data-foo="value">foo!</div>]
以 CSS 搜尋
由於 class 是 Python 程式語言的保留字,所以 Beautiful Soup 改以 class_ 這個名稱代表 HTML 節點的 class 屬性,例如搜尋 class 為 boldtext 的 b 節點:
# 搜尋 class 為 boldtext 的 b 節點
b_tag = soup.find_all("b", class_="boldtext")
print(b_tag)
[<b class="boldtext">Bold Text</b>]
CSS 的 class 屬性也可以使用正規表示法搜尋:
# 以正規表示法搜尋 class 屬性
b_tag = soup.find_all(class_=re.compile("^bold"))
print(b_tag)
[<b class="boldtext">Bold Text</b>]
一個 HTML 標籤元素可以同時有多個 CSS 的 class 屬性值,而我們在以 class_ 比對時,只要其中一個 class 符合就算比對成功,例如:
css_soup = BeautifulSoup('<p class="body strikeout"></p>', 'html.parser')
# 只要其中一個 class 符合就算比對成功
p_tag = css_soup.find_all("p", class_="strikeout")
print(p_tag)
[<p class="body strikeout"></p>]
我們也可以拿完整的 class 字串來進行比對:
# 比對完整的 class 字串
p_tag = css_soup.find_all("p", class_="body strikeout")
print(p_tag)
[<p class="body strikeout"></p>]
不過如果多個 class 名稱排列順序不同時,就會失敗:
# 若順序不同,則會失敗
p_tag = css_soup.find_all("p", class_="strikeout body")
print(p_tag)
[]
遇到多個 CSS class 的狀況,建議改用 CSS 選擇器來篩選:
# 使用 CSS 選擇器
p_tag = css_soup.select("p.strikeout.body")
print(p_tag)
[<p class="body strikeout"></p>]
以文字內容搜尋
若要依據文字內容來搜尋特定的節點,可以使用 find_all 配合 string 參數:
links_html = """
<a id="link1" href="/my_link1">Link One</a>
<a id="link2" href="/my_link2">Link Two</a>
<a id="link3" href="/my_link3">Link Three</a>
"""
soup = BeautifulSoup(links_html, 'html.parser')
# 搜尋文字為「Link One」的超連結
soup.find_all("a", string="Link One")
[<a href="/my_link1" id="link1">Link One</a>]
亦可使用正規表示法批配文字內容:
# 以正規表示法搜尋文字為「Link」開頭的超連結
soup.find_all("a", string=re.compile("^Link"))
[<a href="/my_link1" id="link1">Link One</a>, <a href="/my_link2" id="link2">Link Two</a>, <a href="/my_link3" id="link3">Link Three</a>]
向上、向前與向後搜尋
前面介紹的 find_all 都是向下搜尋子節點,如果需要向上搜尋父節點的話,可以改用 find_parents 函數(或是 find_parent),它可讓我們以某個特定節點為起始點,向上搜尋父節點:
html_doc = """
<body><p class="my_par">
<a id="link1" href="/my_link1">Link 1</a>
<a id="link2" href="/my_link2">Link 2</a>
<a id="link3" href="/my_link3">Link 3</a>
<a id="link3" href="/my_link4">Link 4</a>
</p></body>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
link2_tag = soup.find(id="link2")
# 往上層尋找 p 節點
p_tag = link2_tag.find_parents("p")
print(p_tag)
[<p class="my_par"> <a href="/my_link1" id="link1">Link 1</a> <a href="/my_link2" id="link2">Link 2</a> <a href="/my_link3" id="link3">Link 3</a> <a href="/my_link4" id="link3">Link 4</a> </p>]
如果想要在在同一層往前尋找特定節點,則可用 find_previous_siblings 函數(或是 find_previous_sibling):
# 在同一層往前尋找 a 節點
link_tag = link2_tag.find_previous_siblings("a")
print(link_tag)
[<a href="/my_link1" id="link1">Link 1</a>]
如果想要在在同一層往後尋找特定節點,則可用 find_next_siblings 函數(或是 find_next_sibling):
# 在同一層往後尋找 a 節點
link_tag = link2_tag.find_next_siblings("a")
print(link_tag)
[<a href="/my_link3" id="link3">Link 3</a>, <a href="/my_link4" id="link3">Link 4</a>]
網頁檔案
如果我們想要用 Beautiful Soup 解析已經下載的 HTML 檔案,可以直接將開啟的檔案交給 BeautifulSoup 處理:
from bs4 import BeautifulSoup
# 從檔案讀取 HTML 程式碼進行解析
with open("index.html") as f:
soup = BeautifulSoup(f)
以下我們提供了幾個實際以 Beautiful Soup 開發的網路爬蟲範例程式。
下載 Yahoo 頭條新聞
Beautiful Soup 本身只是一個 HTML 解析工具,它並不負責下載網頁,所以通常我們在開發爬蟲程式時,會搭配 requests 模組一同使用。
在這個範例中,我們打算開發一個爬蟲程式,可從 Yahoo 的首頁把頭條新聞的標題與網址抓下來,在開發程式之前,我們通常都會先用瀏覽器的開發人員工具,觀察一下目標網頁的 HTML 結構,找出我們有興趣的資料所在位置,並設計好萃取資料的規則。
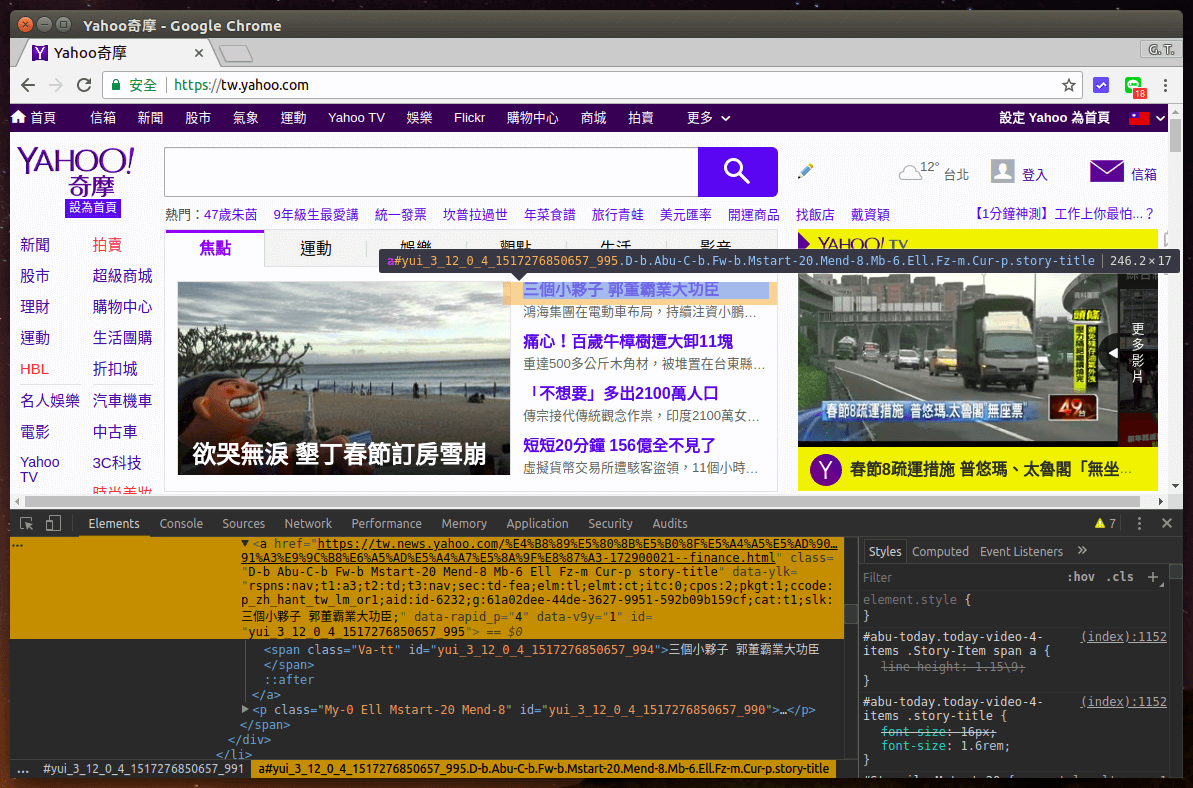
以 Yahoo 頭條新聞來說,我們可以發現網頁中的頭條新聞超連結都有 story-title 這個 CSS 的 class,所以我們只要找出網頁中所有符合此條件的標籤,就可以把頭條新聞的資訊抓出來了。
以下是使用 requests 模組從 Yahoo 下載首頁的 HTML 資料後,以 Beautiful Soup 翠取出頭條新聞標題的指令稿:
import requests
from bs4 import BeautifulSoup
# 下載 Yahoo 首頁內容
r = requests.get('https://tw.yahoo.com/')
# 確認是否下載成功
if r.status_code == requests.codes.ok:
# 以 BeautifulSoup 解析 HTML 程式碼
soup = BeautifulSoup(r.text, 'html.parser')
# 以 CSS 的 class 抓出各類頭條新聞
stories = soup.find_all('a', class_='story-title')
for s in stories:
# 新聞標題
print("標題:" + s.text)
# 新聞網址
print("網址:" + s.get('href'))
程式執行之後,就會輸出 Yahoo 首頁頭條新聞的標題與網址:
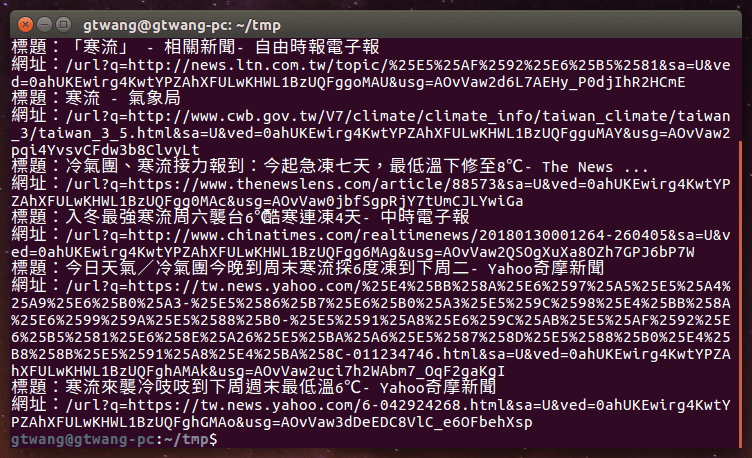
下載 Google 搜尋結果
這個範例我們要開發一個可以自動送出關鍵字到 Google 進行搜尋,並將搜尋結果抓回來的爬蟲程式,基本的開發概念都相同,只不過 Google 的網頁會因為瀏覽器(User-Agent)不同而產生不同的結果,所以在觀察程式碼的時候,最好是使用 Beautiful Soup 的 prettify 把抓回來的 HTML 原始碼排版後印出來,這樣看會比較準確。
Google 搜尋引擎網址是 https://www.google.com.tw/search,而關鍵字則是透過 q 這個參數送給它,這個規則只要稍微觀察一下瀏覽器所顯示的網址即可推論出來,有了這個規則之後,就可以用 requests 與 BeautifulSoup 先把 Google 搜尋結果的 HTML 原始碼抓下來看看。
接著再設計一下萃取資料的規則,這裡我使用一個自己設計的 CSS 的選擇器:
div.g > h3.r > a[href^="/url"]
它可以抓出 class 為 g 的 <div>,底下緊接著 class 為 r 的 <h3>,底下又接著網址為 /url 開頭的超連結。
設計好資料萃取的規則後,就可以把整個程式來了,以下是完整的 Google 搜尋爬蟲程式:
import requests
from bs4 import BeautifulSoup
# Google 搜尋 URL
google_url = 'https://www.google.com.tw/search'
# 查詢參數
my_params = {'q': '寒流'}
# 下載 Google 搜尋結果
r = requests.get(google_url, params = my_params)
# 確認是否下載成功
if r.status_code == requests.codes.ok:
# 以 BeautifulSoup 解析 HTML 原始碼
soup = BeautifulSoup(r.text, 'html.parser')
# 觀察 HTML 原始碼
# print(soup.prettify())
# 以 CSS 的選擇器來抓取 Google 的搜尋結果
items = soup.select('div.g > h3.r > a[href^="/url"]')
for i in items:
# 標題
print("標題:" + i.text)
# 網址
print("網址:" + i.get('href'))
執行後,就可以自動透過 Google 搜尋關鍵字,然後馬上把結果抓回來。