在 Octave 中提供兩種方式可以將多種不同的資料儲存在同一個變數中,一種是類似 C 語言的資料結構(data structure),資料結構中的元素都有對應的名稱;另一種是巢狀陣列(cell array),巢狀陣列中可以包含任意類型與各種維度的資料。而函數的參數與傳回值是以逗點分隔序列(comma separated list)來儲存與傳遞。
資料結構(Data Structures)
Octave 中可以使用資料結構(data structure)將不同的資料儲存在一個變數中,使用上的語法非常類似 C 語言中的結構(structure)。目前其內部是以關聯性陣列的方式實做,而索引限定為字串。
基本用法與範例(Basic Usage and Examples)
資料結構中的欄位可以儲存各種類型的資料,而變數與其欄位名稱中間以句點連接,例如:
x.a = 1;
x.b = [1, 2; 3, 4];
x.c = "string";
這樣會建立一個包含三個欄位的資料結構 x,而 x 中的欄位 a 儲存一個純量,其值為 1,另外兩個欄位 b 與 c 分別為矩陣與字串。若要查看其中的資料,可以像一般的變數一樣輸入其變數名稱:
x
輸出為
x =
{
a = 1
b =
1 2
3 4
c = string
}Octave 在輸出資料結構時,其欄位的順序是不固定的。
資料結構中的欄位也可以指定為另一個資料結構,例如指定 x.d 為另一個資料結構:
x.d.d1 = 3;
x.d.d2 = [1, 2];
x.d
輸出為
ans =
{
d1 = 3
d2 =
1 2
}這時的 x 包含了另一個資料結構:
x
輸出為
x =
{
a = 1
b =
1 2
3 4
c = string
d =
{
d1 = 3
d2 =
1 2
}
}當 Octave 在輸出資料結構中又有包含其他的資料結構時,只會輸出最上面的幾層,例如:
a.b.c.d.e = 1;
a
輸出為
a =
{
b =
{
c =
{
1x1 struct array containing the fields:
d: 1x1 struct
}
}
}限制輸出層數的原因是為了避免產生太長而難以閱讀輸出格式,輸出的層數可以使用 struct_levels_to_print() 函數設定。
val = struct_levels_to_print ()
old_val = struct_levels_to_print (new_val)
設定資料結構的輸出層數上限。
函數的傳回值類型也可以是資料結構,例如:
function y = f (x)
y.re = real (x);
y.im = imag (x);
endfunction
此函數 f(x) 會將輸入的複數純量或矩陣分開成實部與虛部分別儲存在兩個資料結構的欄位中,並傳回之,例如:
f([1+2i, 2+10i])
輸出為
ans =
{
re =
1 2
im =
2 10
}函數的傳回值若是逗點分隔序列,也可以使用資料結構儲存,其使用方式就像一般變數一樣:
[ result.u, result.s(2:3,2:3), result.v ] = svd ([1, 2; 3, 4]);
result
輸出為
result =
{
u =
-0.40455 -0.91451
-0.91451 0.40455
s =
0.00000 0.00000 0.00000
0.00000 5.46499 0.00000
0.00000 0.00000 0.36597
v =
-0.57605 0.81742
-0.81742 -0.57605
}資料結構中的欄位亦可以使用 for 迴圈依序存取,請參考 Octave 敘述(Statements)。
結構陣列(Structure Arrays)
結構陣列(structure arrays)是一種特別的資料結構,此結構的欄位是以巢狀陣列(cell arrays)表示,每一個巢狀陣列有相同的維度。結構陣列亦可視為資料結構所構成的陣列,而陣列中的資料結構所擁有的欄位皆相同。例如:
x(1).a = "string1";
x(2).a = "string2";
x(1).b = 1;
x(2).b = 2;
這樣會建立一個 2 乘 1 的結構陣列,其包含兩個欄位。另一種建立結構陣列的方式是使用 struct() 函數(請參考建立結構)。若要顯示結構陣列中的資料,就像一般變數一樣輸入結構陣列的名稱即可:
x
輸出為
x =
{
1x2 struct array containing the fields:
a
b
}要存取結構陣列中的元素,可以使用索引的方式,例如:
x(1)
這樣會傳回兩個欄位的資料結構,輸出為
ans =
{
a = string1
b = 1
}若直接指定結構陣列中的欄位,則會將此欄位的資料以逗點分隔序列(請參考逗點分隔序列)的格式傳回,例如:
x.a
輸出為
ans = string1 ans = string2
亦可使用逗點分隔序列的方式指定結構陣列中的資料:
[x.a] = deal("new string1", "new string2");
這會設定 x(1).a 與 x(2).a 的資料:
x(1).a
輸出為
ans = new string1
x(2).a
輸出為
ans = new string2
結構陣列與一般數值陣列一樣可以使用向量作為為索引:
x(3:4) = x(1:2);
[x([1,3]).a] = deal("other string1", "other string2");
x.a
輸出為
ans = other string1 ans = new string2 ans = other string2 ans = new string2
size() 函數可以輸出資料結構的維度,例如:
size(x)
輸出為
ans = 1 4
若要刪除結構陣列中的元素可以將其指定為空矩陣(empty matrix),此用法與一般數值陣列相同,例如:
in = struct ("call1", {x, Inf, "last"}, "call2", {x, Inf, "first"})
輸出為
in =
{
1x3 struct array containing the fields:
call1
call2
}將第一個元素刪除:
in(1) = [];
in.call1
輸出為
ans = Inf ans = last
size(in)
輸出為
ans = 1 2
建立結構(Creating Structures)
要建立資料結構除了使用句點(.)的方式之外,亦可使用 struct() 函數來建立資料結構。struct() 函數的輸入參數是兩兩一對:第一個是資料結構的欄位名稱,配上第二個儲存資料的純量(scalar)或巢狀陣列(cell array),例如:
struct ("field1", 1, "field2", 2)
輸出為
ans =
{
field1 = 1
field2 = 2
}若 struct() 輸入的參數中,儲存資料的參數同時含有純量與巢狀陣列時,Octave 會將純量自動轉變為相同大小的巢狀陣列,例如:
s = struct ("field1", {1, "one"}, "field2", {2, "two"}, "field3", 3);
資料結構 s 的內容如下:
s.field1
輸出為
ans = 1 ans = one
s.field2
輸出為
ans = 2 ans = two
s.field3
輸出為
ans = 3 ans = 3
若要建立包含一個獨立巢狀陣列的資料結構,必須將巢狀陣列放入另一個巢狀陣列中,例如:
struct ("field1", {{1, "one"}}, "field2", 2)
輸出為
ans =
{
field1 =
{
[1,1] = 1
[1,2] = one
}
field2 = 2
}struct ("field", value, "field", value, ...)
struct() 函數可以建立資料結構並初始化所儲存的資料。 若參數 value 是巢狀陣列,則會建立結構陣列,其中所有的巢狀陣列必須有相同的維度,單一元素的巢狀陣列或是純量會被自動複製成相同長度的巢狀陣列。若 value 指定為空巢狀陣列,則會產生空結構陣列。
struct()函數的參數若指定為物件,則會傳回此物件內部的資料結構。
isstruct (expr)
isstruct(expr) 函數會判斷 expr 是否為資料結構。
結構操作(Manipulating Structures)
這裡列出一些用於操作資料結構欄位的函數。
rmfield (s, f)
rmfield(s, f) 函數會將資料結構 s 中的 f 欄位刪除,若 f 為字串的巢狀陣列或字元矩陣,則會將對應的欄位刪除。例如:
s = struct ("field1", 1, "field2", 2, "field3", 3, "field4", 4);
s2 = rmfield(s, ["field1"; "field3"])
輸出為
s2 =
{
field2 = 2
field4 = 4
}
[k1, ..., v1] = setfield (s, k1, v1, ...)
setfield(s, k1, v1) 會將資料結構 s 中欄位 k1 的值指定為 v1,並傳回新的資料結構。若欄位 k1 不存在,則會自動新增此欄位,例如:
s = struct ("field1", 1, "field2", 2);
s2 = setfield(s, "new_field", "new")
輸出為
s2 =
{
field1 = 1
field2 = 2
new_field = new
}其功用相當於:
s = struct("field1", 1, "field2", 2);
s2 = s;
s2.new_field = "new"
若是多層次的資料結構,則依序將欄位與索引填入參數中,例如:
sa(1, 1).f0 = 1;
sa2 = setfield (sa, {1, 2}, "fd", {3}, "b", 6);
其功用相當於:
sa(1, 1).f0 = 1;
sa2 = sa;
sa2(1, 2).fd(3).b = 6;
亦可使用另一種寫法:
sa(1, 1).f0 = 1;
sa2 = sa;
i1 = {1,2}; i2 = "fd"; i3 = {3}; i4 = "b";
sa2(i1{:}).(i2)(i3{:}).(i4) = 6;
[t, p] = orderfields (s1, s2)
orderfields(s1, s2) 函數會將資料結構 s1 的欄位依照 s2 所指定的順序排序後,傳回新的資料結構,若省略 s2 則會以字母的順序排序。參數 s2 可以是資料結構、字串的巢狀陣列或是排序向量。例如:
s1 = struct ("f1", 1, "f2", 2, "f3", 3, "f4", 4);
s2 = struct ("f4", 40, "f1", 10, "f2", 20, "f3", 30);
將 s1 以 s2 的順序排序:
orderfields(s1, s2)
輸出為
ans =
{
f4 = 4
f1 = 1
f2 = 2
f3 = 3
}以字串的巢狀陣列指定排序方式:
orderfields(s1, {"f2", "f3", "f4", "f1"})
輸出為
ans =
{
f2 = 2
f3 = 3
f4 = 4
f1 = 1
}以排序向量指定排序方式:
orderfields(s1, [3, 1, 4, 2])
輸出為
ans =
{
f3 = 3
f1 = 1
f4 = 4
f2 = 2
}fieldnames (struct)
fieldnames(struct) 函數會傳回資料結構 struct 的所有欄位名稱。若指定的 struct 不是資料結構,則會產生錯誤。例如:
s = struct ("f1", 1, "f2", 2, "f3", 3, "f4", 4);
fieldnames(s)
輸出為
ans =
{
[1,1] = f1
[2,1] = f2
[3,1] = f3
[4,1] = f4
}isfield (expr, name)
isfield(expr, name) 函數會測試資料結構 expr 中是否包含名稱為 name 的欄位,參數 expr 為資料結構,而 name 為字串。例如:
s = struct ("f1", 1, "f2", 2, "f3", 3, "f4", 4);
isfield(s, "f2")
輸出為
ans = 1
[v1, ...] = getfield (s, key, ...)
getfield(s, key, ...) 函數會取出資料結構 s 中指定欄位的資料,例如:
s = struct ("f1", 1, "f2", 2, "f3", 3, "f4", 4);
getfield(s, "f3")
輸出為
ans = 3
多層次的資料結構:
ss(1,2).fd(3).b = 5;
getfield (ss, {1,2}, "fd", {3}, "b")
輸出為
ans = 5
亦可使用另一種寫法:
i1 = {1,2}; i2 = "fd"; i3 = {3}; i4= "b";
ss(i1{:}).(i2)(i3{:}).(i4)
substruct (type, subs, ...)
substruct() 函數會建立一個 subscript structure,用於 subsref() 或 subsasgn() 函數。
結構的資料處理(Processing Data in Structures)
要處理資料結構中的資料,最簡單的方式就是使用 for 迴圈(請參考 Octave 敘述(Statements))。另外也可以使用 structfun() 函數達到類似的功能,此函數可以將指定的函數套用至資料結構中的每個元素。
structfun (func, s)
[a, b] = structfun (...)
structfun (..., "ErrorHandler", errfunc)
structfun (..., "UniformOutput", val)
structfun(func, s) 函數會將函數 func 套用至資料結構 s 中的每個元素,s 中的每個元素會個別傳入 func 函數中執行。func 可以接受各種函數的形式,包含 inline function、function handle 或函數名稱(字串)。例如:
s = struct("f1", 1, "f2", 2, "f3", 3);
structfun (@(x) x * 2 + 1, s)
這會將資料結構 s 中所有的值乘以 2 再加 1,輸出為
ans = 3 5 7
若參數 "UniformOutput" 設定為 true,則 func 所指定的函數必須傳回一個純量,這些純量會被連接起來而產生一個陣列,若設為 false,則 structfun() 的輸出將會是一個與輸入資料結構 s 有相同欄位的資料結構,其中的值是將 s 中的元素經過 func 函數處理後,再放進輸出資料結構的對應欄位中,在這種情況下輸出的資料形態是沒有限制的。例如:
s.name1 = "John Smith";
s.name2 = "Jill Jones";
structfun (@(x) regexp (x, '(w+)$', "matches"){1}, s, "UniformOutput", false)
輸出為
ans =
{
name1 = Smith
name2 = Jones
}"ErrorHandler" 參數可以將其後方的 errfunc 設定為錯誤處理函數,當 func 函數產生錯誤時,就會呼叫這個函數,此函數的格式為:
function [...] = errfunc (se, ...)
其中傳入的參數 se 是一個資料結構,其包含的欄位有:"identifier"、"message" 與 "index",分別代表錯誤的代碼與訊息,以及錯誤發生的資料位置。
struct2cell (s)
struct2cell(s) 函數會將資料結構 s 轉為巢狀陣列(cell array),若 f 為資料結構 s 的欄位數,則轉換出來的巢狀陣列維度為 [f size(s)]。例如:
s = struct("f1", "abcd", "f2", "1234");
struct2cell(s)
輸出為
ans =
{
[1,1] = abcd
[2,1] = 1234
}巢狀陣列(Cell Arrays)
在儲存資料時常常會需要將各種不同類型的資料除存在一個變數中,巢狀陣列就是為了這個需求而設計的。在一般的情況下巢狀陣列的使用方式與一般的陣列是一樣的,唯一的不同在於巢狀陣列在建立與索引時是使用大括弧({})。
基本巢狀陣列(Basic Usage of Cell Arrays)
巢狀陣列的使用方式與陣列類似,差異只在其使用的是大括弧,例如:
c = {"a string", rand(2, 2)};
要存取巢狀陣列中的元素可以使用大括弧做為索引運算字,例如要取得 c 的第一個元素:
c{1}
輸出為
ans = a string
巢狀陣列與一般陣列一樣可以使用向量索引存取多個元素,例如:
c{1:2}
輸出為
ans = a string ans = 0.730203 0.099916 0.864092 0.812627
索引運算子也可以用來新增巢狀陣列的元素,例如在巢狀陣列 c 中第三個位置新增一個元素 3:
c{3} = 3
輸出為
c =
{
[1,1] = a string
[1,2] =
0.730203 0.099916
0.864092 0.812627
[1,3] = 3
}關於更詳細的巢狀陣列索引說明可參考巢狀陣列索引。
在一般的情況下,巢狀陣列會以階層的方式輸出(就像上面的範例一樣),若是需要以索引的方式輸出可以使用 celldisp() 函數。
celldisp (c, name)
celldisp(c, name) 函數會以遞迴的方式輸出巢狀陣列 c,輸出時的名稱可以使參數 name 指定,若省略 name 參數則使用參數 c 做為輸出名稱。例如輸出上面所建立的巢狀陣列 c:
celldisp(c)
輸出為
c{1} =
a string
c{2} =
0.730203 0.099916
0.864092 0.812627
c{3} =
3iscell (x)
iscell(x) 函數會判斷 x 是否為巢狀陣列,例如:
iscell(c)
輸出為
ans = 1
iscell(3)
輸出為
ans = 0
建立巢狀陣列(Creating Cell Arrays)
在基本巢狀陣列中已經介紹過如何使用已存在的資料建立一個巢狀陣列,然而在某些形況下會需要先建立一個巢狀陣列,而其中的資料隨後才會指定,此時可以使用 cell() 函數先產生指定維度的巢狀陣列,此函數的功能類似 zeros() 函數,由 cell() 函數所產生的巢狀陣列其所有的元素皆為空陣列。例如:
c = cell(2,2)
輸出為
c =
{
[1,1] = [](0x0)
[2,1] = [](0x0)
[1,2] = [](0x0)
[2,2] = [](0x0)
}巢狀陣列與一般陣列一樣可以是多維度的,cell() 函數可以接受任何個數的正整數來指定所產生巢狀陣列的維度,亦可使用向量來指定其維度,例如:
c1 = cell(3, 4, 5);
c2 = cell( [3, 4, 5] );
所產生的 c1 與 c2 是相同的巢狀陣列,要查看其維度可用 size() 函數:
size(c1)
輸出為
ans = 3 4 5
除了
size()函數之外,一般查詢物件大小的函數都可使用於巢狀陣列上,例如:length、numel、rows()與columns()。
cell (x)
cell (n, m)
cell ([n, m])
cell (n, m, p, ...)
cell ([n, m, p, ...])
cell(x) 會建立一個 x 乘 x 的巢狀陣列;cell(n, m) 或 cell([n, m]) 會建立 n 乘 m 的巢狀陣列;cell(n, m, p, ...) 或 cell([n, m, p, ...]) 會建立多維度的巢狀陣列。
若要將數值陣列轉換為巢狀陣列,可以使用 num2cell() 與 mat2cell() 函數。
c = num2cell (m)
c = num2cell (m, dim)
num2cell(m, dim) 會將數值矩陣 m 轉換為巢狀陣列,若有設定 dim 參數,則所傳回的巢狀陣列 c 的第 dim 個維度會是 1,而 c 中的元素則會是向量,例如:
a = [1,2,3;4,5,6];
將矩陣 a 轉為巢狀陣列:
num2cell(a)
輸出為
ans =
{
[1,1] = 1
[2,1] = 4
[1,2] = 2
[2,2] = 5
[1,3] = 3
[2,3] = 6
}num2cell(a, 1)
輸出為
ans =
{
[1,1] =
1
4
[1,2] =
2
5
[1,3] =
3
6
}num2cell(a, 2)
輸出為
ans =
{
[1,1] =
1 2 3
[2,1] =
4 5 6
}b = mat2cell (a, m, n)
b = mat2cell (a, d1, d2, ...)
b = mat2cell (a, r)
mat2cell(a, m, n) 會將矩陣 a 轉換為巢狀陣列,參數 m 與 n 是指定如何分割矩陣 a,例如:
a = [1, 2, 3, 4, 5; 6, 7, 8, 9, 10; 11, 12, 13, 14, 15];
將矩陣 a 以圖中所表示的方法分割後轉為巢狀陣列:
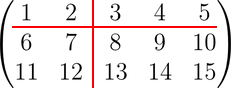
mat2cell(a, [1, 2], [2, 3])
輸出為
ans =
{
[1,1] =
1 2
[2,1] =
6 7
11 12
[1,2] =
3 4 5
[2,2] =
8 9 10
13 14 15
}在 mat2cell(a, m, n) 中 m 的總和必須等於矩陣 a 的第一個維度,n 的總和必須等於矩陣 a 的第二個維度,更高維度的情況以此類推。
若只指定一個維度 r,則其餘的維度會被設定為 a 的維度,即第 i 個維度設為 size(a, i),例如:
mat2cell(a, [1, 2])
輸出為
ans =
{
[1,1] =
1 2 3 4 5
[2,1] =
6 7 8 9 10
11 12 13 14 15
}巢狀陣列索引(Indexing Cell Arrays)
在基本巢狀陣列中提到過巢狀陣列的元素可以使用大括號 {} 來存取,但若是使用者需要將巢狀陣列中的元素取出並依然保持巢狀陣列,則可以使用小括號 () 來存取,以下的範例示範大括號與小括號的差異:
c = {"1", "2", "3"; "a", "b", "c"; "4", "5", "6"};
使用大括號取出元素:
c{2, 3}
輸出為
ans = c
使用小括號取出元素:
c(2, 3)
輸出為
ans =
{
[1,1] = c
}由上面的範例可以看出使用大括號是存取巢狀陣列中的元素,而小括號是存取巢狀陣列中的子巢狀陣列。
巢狀陣列的小括號使用方式與一般多維度的陣列相似,例如將巢狀陣列 c 的第一行與第三行中所有的元素都設為 0:
c(:, [1, 3]) = {0}
輸出為
c =
{
[1,1] = 0
[2,1] = 0
[3,1] = 0
[1,2] = 2
[2,2] = b
[3,2] = 5
[1,3] = 0
[2,3] = 0
[3,3] = 0
}有另外一種寫法也可以:
c(:, [1, 3]) = 0;
這裡的 0 會被 Octave 自動替換為 {0} 然後指定給 c 的子巢狀陣列。
另外一個使用小括號的範例:
c = {1, 2, 3; 4, 5, 6};
c([1, 2], :) = c([2, 1], :)
這會將巢狀陣列 c 的第一行與第二行對調,輸出為
c =
{
[1,1] = 4
[2,1] = 1
[1,2] = 5
[2,2] = 2
[1,3] = 6
[2,3] = 3
}使用大括號取得巢狀陣列中的元素會傳回逗點分隔序列(請參考逗點分隔序列)。例如使用大括號再將上面的巢狀陣列 c 的第一行與第二行對調回來:
[c{[1, 2], :}] = deal(c{[2, 1], :})
輸出為
c =
{
[1,1] = 1
[2,1] = 4
[1,2] = 2
[2,2] = 5
[1,3] = 3
[2,3] = 6
}空矩陣 [] 可以用來刪除巢狀陣列中的元素,例如:
x = {"1", "2"; "3", "4"};
x(1, :) = []
輸出為
x =
{
[1,1] = 3
[1,2] = 4
}使用大括號將巢狀陣列元素的內容刪除,但保留元素的空間:
x = {"1", "2"; "3", "4"};
x{1, 1} = [];
x{1, 2} = [];
x
輸出為
x =
{
[1,1] = [](0x0)
[2,1] = 3
[1,2] = [](0x0)
[2,2] = 4
}字串巢狀陣列(Cell Arrays of Strings)
巢狀陣列常用於儲存多個字串,字元陣列亦可一次儲存多個字串,但其每個字串的長度必須相等,而巢狀陣列則沒有這樣的限制,因此在儲存多個不同長度的字串時,建議使用巢狀陣列。在某些情況下在運算時會需要以字元陣列來儲存字串,Octave 中提供了一些函數可以將資料在巢狀陣列與字元陣列之間轉換:char() 與 strvcat() 函數可以將巢狀陣列轉換為字元陣列(請參考連接字串),而 cellstr() 函數可以將字元陣列轉換為巢狀陣列,例如:
a = ["hello"; "world"];
c = cellstr (a)
輸出為
c =
{
[1,1] = hello
[2,1] = world
}cellstr (string)
cellstr(string) 函數會將字串陣列 string 轉換為巢狀陣列。
在 Octave 中大部分的字串操作函數都支援字串巢狀陣列,因此使用巢狀陣列的另外一個優點就是可以直接套用這些字串操作函數,例如可以使用 strcmp() 函數輸入字串巢狀陣列一次比較多個字串:
c = {"hello", "world"};
strcmp ("hello", c)
strcmp() 函數的參數中若有一個是字串巢狀陣列時,其會將巢狀陣列中的每一個字串與另外一個字串做比較,輸出為
ans = 1 0
以下的字串操作函數都支援巢狀陣列:char()、 strvcat()、 strcat() (請參考連接字串)、 strcmp()、 strncmp()、 strcmpi()、 strncmpi() (請參考字串比較)、 str2double()、 strtrim()、 strtrunc()、 strfind()、 strmatch()、 regexp()、 regexpi() (請參考字串操作)與 str2double() (請參考字串轉換)。
iscellstr (cell)
iscellstr(cell) 函數可以判斷巢狀陣列 cell 中所有的元素是否都是字串。
[idxvec, errmsg] = cellidx (listvar, strlist)
cellidx(listvar, strlist) 函數會傳回 strlist 中所有的字串在 listvar 中的位置索引,第一個傳回值 idxvec 是 listvar 的索引向量,若 strlist 中所列的字串不在 listvar 之中,則會將錯誤訊息傳回至第二個參數 errmsg 中,若只有指定一個輸出參數,則會將錯誤訊息輸出至螢幕上,並離開程式。例如:
a = {"ABC", "123", "abc", "456", "DEF"};
b = {"123", "456"};
cellidx(a, b)
輸出為
ans = 2 4
strlist 與 listvar 兩個參數都可以指定為字元陣列,若指定為字元陣列則每個字串在搜尋前會先以 deblank() 函數將多餘的空白去除。
巢狀陣列的資料處理(Processing Data in Cell Arrays)
儲存在巢狀陣列中的資料依據其實際的資料的類型可以有幾種不同的處理方式,最簡單的方式就是使用一個或多個迴圈來處理,或是直接使用 cellfun() 函數來處理,此函數會將使用者所指定的函數套用至巢狀陣列中的每一個元素。
cellfun (fname, c)
cellfun ("size", c, k)
cellfun ("isclass", c, k)
cellfun (func, c)
cellfun (func, c, d)
[a, b] = cellfun (...)
cellfun (..., "ErrorHandler", errfunc)
cellfun (..., "UniformOutput", val)
cellfun(fname, c) 函數會將指定的函數 fname 套用至巢狀陣列 c 中的每一個元素,c 中的每個元素會個別傳入 fname 函數中做處理,fname 可以指定為下列函數:
"isempty":測試是否為空元素。"islogical":測試是否為邏輯值。"isreal":測試是否為實數。"length":傳回一個向量,向量中包含元素的長度。"ndims":傳回元素的維度。"prodofsize":傳回每個元素維度的乘積。"size":傳回第 k 維的維度大小。"isclass":測試元素的類別。
例如:
c = {"ABC", "12345"};
cellfun("length", c)
輸出為
ans = 3 5
cellfun(func, c, d) 函數可以使用 inline function 或 function handle 的方式指定函數 func,而 c 與 d 則是用於指定 func 輸入的參數,例如:
cellfun (@atan2, {1.1, 0.3}, {0.2, 1.4})
輸出為
ans = 1.39094 0.21109
cellfun() 函數其預設的輸出是一個與輸入參數為度相同的陣列。
若參數 "UniformOutput" 設定為 true,則 func 所指定的函數必須傳回純量,這些純量會被連接起來而產生一個陣列,若設為 false,則 cellfun() 函數會傳回一個巢狀陣列,其中的元素是將輸入巢狀陣列 c 中的元素個別經過 func 函數處理後,再放進輸出巢狀陣列的對應位置,例如:
cellfun (@(x) tolower(x), {"Foo", "Bar", "FooBar"}, "UniformOutput", false)
輸出為
ans =
{
[1,1] = foo
[1,2] = bar
[1,3] = foobar
}"ErrorHandler" 參數可以將其後方的 errfunc 設定為錯誤處理函數,當 func 函數產生錯誤時,就會呼叫這個函數,此函數的格式為:
function [...] = errfunc (s, ...)
其中傳入的參數 s 是一個資料結構,其包含的欄位有:"identifier"、"message" 與 "index",分別代表錯誤的代碼與訊息,以及錯誤發生的資料位置,例如:
function y = foo (s, x), y = NaN; endfunction
cellfun (@factorial, {-1,2},'ErrorHandler',@foo)
輸出為
ans = NaN 2
另外一種巢狀陣列資料的處理方式是將巢狀陣列轉換為其他的資料容器,例如矩陣與資料結構。
m = cell2mat (c)
cell2mat(c) 函數會將巢狀陣列 c 轉換為矩陣,巢狀陣列 c 中的元素必須為數值、邏輯值或字串。
cell2struct (cell, fields, dim)
cell2struct(cell, fields, dim) 函數會將巢狀陣列 cell 轉換為資料結構,參數 fields 所指定的欄位數量必須等於 cell 維度 dim 的大小,即 numel (fields) == size (cell, dim)。例如:
cell = {'Peter', 'Hannah', 'Robert'; 185, 170, 168};
A = cell2struct (cell, {'Name','Height'}, 1);
A(1)
輸出為
ans =
{
Name = Peter
Height = 185
}逗點分隔序列(Comma Separated Lists)
逗點分隔序列(comma separated lists)是 Octave 函數的輸入與輸出參數的基本資料類型,例如:
max(a, b)
其中小括號中的 a, b 就是一個逗點分隔序列,逗點分隔序列可以使用在等號的左邊或右邊,例如:
x = [1 0 1 0 0 1 1; 0 0 0 0 0 0 7];
[i, j] = find (x, 2, "last");
其中等號右邊小括號中的 x, 2, "last" 是一個逗點分隔序列組成的輸入參數,而 find() 函數也會傳回一個逗點分隔序列,並將其中的每個元素分別指定給等號左邊逗點分隔序列中的元素 i, j。
逗點分隔序列另外一個常見的使用方式是在使用中括號([])建立矩陣,或使用大括號({})建立巢狀陣列時:
a = [1, 2, 3, 4];
c = {4, 5, 6, 7};
其中的 1, 2, 3, 4 與 4, 5, 6, 7 都是逗點分隔序列。
使用者無法直接操作逗點分隔序列,但可以將資料結構與巢狀陣列轉換為逗點分隔序列,這樣可以替代原本使用逗點分隔序列的地方,這種特性在某些形況很有用,在下面的教學中會示範這樣的用法。
由巢狀陣列產生逗點分隔序列(Comma Separated Lists Generated from Cell Arrays)
巢狀陣列可以使用大括號將指定元元素取出並組成逗點分隔序列(請參考巢狀陣列索引),而將此逗點分隔序列之外再加上中括號則可以轉換成陣列,例如:
a = {1, [2, 3], 4, 5, 6};
b = [a{1:4}]
輸出為
b = 1 2 3 4 5
使用大括號可以將逗點分隔序列轉換為巢狀陣列,例如將一個巢狀陣列中的元素取出建立一個新的巢狀陣列:
a = {1, rand(2, 2), "three"};
b = { a{ [1, 3] } }
輸出為
b =
{
[1,1] = 1
[1,2] = three
}另外,巢狀陣列使用大括號所取得的逗點分隔序列,可以直接做為函數的輸入參數,這等同於將每個元素分開傳入函數中。例如:
c = {"GNU", "Octave", "is", "Free", "Software"};
printf ("%s ", c{1}, c{2}, c{3}, c{4}, c{5});
輸出為
GNU Octave is Free Software
也可以使用另外一種寫法:
printf ("%s ", c{:});
輸出為
GNU Octave is Free Software
這兩種寫法是完全一樣的,為一的差異只有在於後者不用輸入那麼長的指令,並且可以處理任何長度的巢狀陣列 c。
使用大括號所產生的逗點分隔序列若是放在等號的左邊,則可以有指定的功能,例如:
[result{1:2}] = find (2 * eye (2))
輸出為
result =
{
[1,1] =
1
2
[1,2] =
1
2
}由結構陣列產生逗點分隔序列(Comma Separated Lists Generated from Structure Arrays)
結構陣列可以使用欄位名稱來產生逗點分隔序列,例如:
x = ceil (randn (10, 1));
in = struct ("call1", {x, 3, "last"}, "call2", {x, inf, "first"});
out = struct ("call1", cell (2, 1), "call2", cell (2, 1));
[out.call1] = find (in.call1);
[out.call2] = find (in.call2);