
這裡介紹如何讓 Hadoop 可以直接讀取 HDFS 中的 Gzip、Bzip2、Snappy 與 LZO 壓縮檔,省去解壓縮的麻煩。
巨量資料在儲存時,通常都會經過適當的壓縮以節省儲存空間,如果在分析時還要先解壓縮的話,可能會遇到儲存空間上的麻煩,以文字檔來說解壓縮之後的資料大小會是原本的好幾倍,而且解壓縮也會需要非常大量的時間。
若遇到資料壓縮與解壓縮的問題,可以將資料以 Hadoop 支援的幾種格式來壓縮存放,這樣在分析時就可以直接靠 Hadoop 解壓縮,讓分析者可以不需要手動處理巨量資料的解壓縮問題,也不必煩惱要準備額外的儲存空間。
Hadoop 支援的壓縮格式
Hadoop 支援的壓縮格式有 gzip、bzip2、snappy 與 LZO,以下是各種壓縮格式的比較:
| Codec | 副檔名 | 是否可分割 | 壓縮率 | 壓縮速度 |
|---|---|---|---|---|
| Gzip | .gz | 否 | 普通 | 普通 |
| Bzip2 | .bz2 | 是 | 佳 | 慢 |
| Snappy | .snappy | 否 | 普通 | 快 |
| LZO | .lzo | 要有索引才能分割 | 普通 | 普通 |
在使用壓縮資料之前,要先檢查 Hadoop 的 core-site.xml 設定檔,確認其中有包含自己要使用的 codec,以下是一個設定參考範例:
<!-- Compression Codecs -->
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.DeflateCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
若要改變 Map 輸出資料的壓縮格式,可以修改 mapred-site.xml,以下是一個 LZO 的參考範例:
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapred.child.env</name>
<value>JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH:/path/to/your/hadoop-lzo/libs/native</value>
</property>
Gzip 壓縮範例
這是一個使用 gzip 壓縮資料的字數計算(word count)範例:
# 在 HDFS 上建立測試用的目錄
hadoop fs -mkdir wordcount
# 建立測試用資料
echo "this is a test that is a test" >> words.txt
# 壓縮資料
gzip words.txt
# 將資料放進 HDFS
hadoop fs -put words.txt.gz wordcount/
# 執行 Word Count 範例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
wordcount wordcount/ wordcount_out/
# 輸出結果
hadoop fs -text wordcount_out/part*
a 2 test 2 that 1 is 2 this 1
測試完之後,將 HDFS 上的資料清除乾淨:
# 清理資料
hadoop fs -rm -r wordcount_out/
hadoop fs -rm -r wordcount/
Bzip2 壓縮範例
這是一個使用 bzip2 壓縮資料的字數計算(word count)範例:
# 在 HDFS 上建立測試用的目錄
hadoop fs -mkdir wordcount
# 建立測試用資料
echo "this is a test that is a test" >> words.txt
# 壓縮資料
bzip2 -z words.txt
# 將資料放進 HDFS
hadoop fs -put words.txt.bz2 wordcount/
# 執行 Word Count 範例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
wordcount wordcount/ wordcount_out/
# 輸出結果
hadoop fs -text wordcount_out/part*
a 2 test 2 that 1 is 2 this 1
測試完之後,將 HDFS 上的資料清除乾淨:
# 清理資料
hadoop fs -rm -r wordcount_out/
hadoop fs -rm -r wordcount/
LZO 壓縮範例
安裝 lzop 壓縮程式:
sudo yum install lzop lzo lzo-devel
或是從官方網站下載:
# 下載 lzop 壓縮程式
wget http://www.lzop.org/download/lzop-1.03-i386_linux.tar.gz
# 解壓縮
tar zxvf lzop-1.03-i386_linux.tar.gz
以下是使用 LZO 壓縮資料的字數計算範例:
# 在 HDFS 上建立測試用的目錄
hadoop fs -mkdir wordcount
# 建立測試用資料
echo "this is a test that is a test" >> words.txt
# 壓縮資料
lzop words.txt
# 將資料放進 HDFS
hadoop fs -put words.txt.lzo wordcount/
# 執行 Word Count 範例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
wordcount wordcount/ wordcount_out/
# 輸出結果
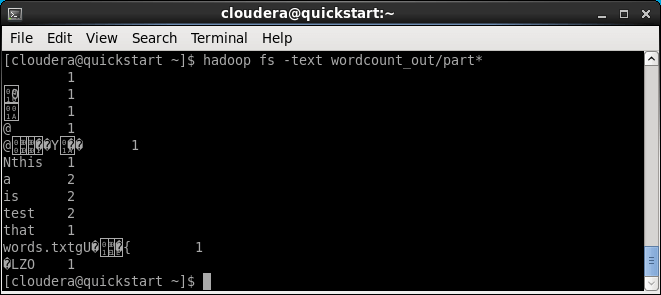
hadoop fs -text wordcount_out/part*
a 2 test 2 that 1 is 2 this 1
測試完之後,將 HDFS 上的資料清除乾淨:
# 清理資料
hadoop fs -rm -r wordcount_out/
hadoop fs -rm -r wordcount/
如果結果出現類似這樣的亂碼,通常是因為 Hadoop 的 codec 沒設定好,沒有正常解壓縮 LZO 壓縮檔索引起的。
若遇到 LzoCodec 找不到的情況,可參考 StackOverflow 的說明安裝 hadoop-lzo。