
這裡用一個美國遊說活動的資料為例,說明資料科學家(Data Scientist)到底在做什麼。
上個月的 Data Science DC Meetup 會議中,一些來自 Sunlight Foundation 的研究者報告了一些使用進階資料分析與視覺化的方法,使一般的文字資料更容易讓人理解。
其中有一些資料是關於美國遊說活動(lobbying activities)的開放性原始資料,而任何人也都可以在遵守 FOIA(Freedom of Information Act)條款下取得這些資料,但是這些資料如果沒有經過整理,你可能很難完全消化,因為這個原始資料沒有特定的結構,都是一般的文字報告,就像這樣:


如果只有幾份報告,那是沒什麼問題,但是現在這種報告有 7814 份,包含 987 個法案、678 個機構、170 種行業,這些報告都是近年來(2007 年至 2012 年)跟移民法案(immigration bills)相關的遊說報告,我們有興趣的是有沒有什麼資訊隱藏在這將近八千份的文件中,因為沒有人有辦法一次看完將近八千份文件,所以我們會需要一些資料科學家來幫忙做分析。
Sunlight 的資深員工 Lee Drutman 與它的同事決定來著手處理這些資料,他們從這些雜亂的報告中拿出部份的資料,轉換成比較有意義的內容,藉此看出各行各業的遊說活動與移民改個法案的關係,他們所使用的方法是將這些資料轉換為互動式的網路圖,你可看出哪些是大家關心的議題,大家如何積極爭取他們的權益。
Lee 在會議中報告了他處理這個資料的技術細節,包含如何蒐集這些資料、使用統計方法分析、然後產生這些圖等。當他拿到這些資料時,經過他們團隊的評估,他們認為如果使用網路圖的呈現方式會讓這些資料更有意義。
在實際分析各行業遊說活動與移民改革法案之間的關係之前,必須先了解這些各式各樣法案之間的關係,Sunlight 的研究人員 Zander Furnas 解說了如何使用 Latent Semantic Analysis 從改革法案文件的 subtopic 欄位找出法案之間的相似度,他與他的團隊將每一個法案以一個向量(vector)來表示,使用法案的簡述(因為完整的法案太冗長了)建立語料庫(corpus),當每個法案都以向量的形式表示時,他們只要比較這些向量就可以得到其相似程度了,而比較的方法則是使用 Hierarchical Agglomerative Clustering(HAC)這個演算法,再配合 Ward’s method 來決定 linkage criteria,最後就得到一個比較平均的分群結果:
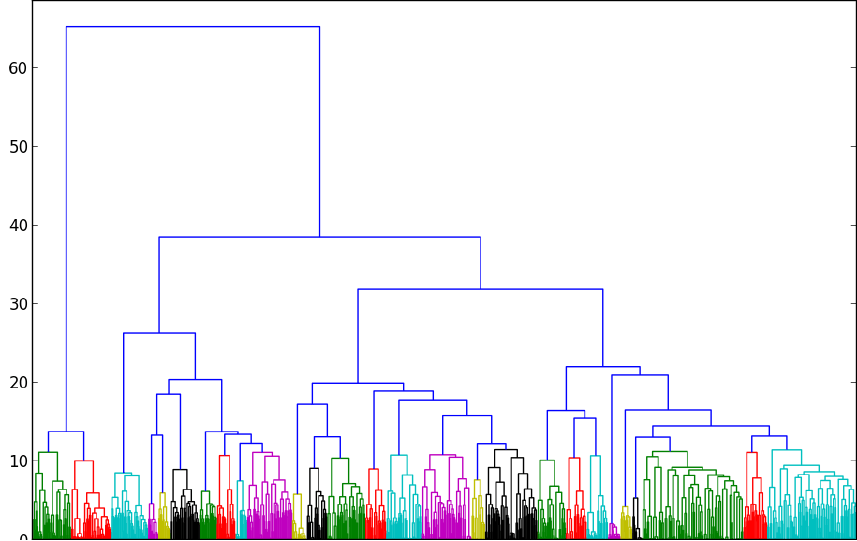
HAC 分析所輸出的資料是一個 dendrogram(上圖),接著就要使用網路圖將這個資料與遊說活動的資料結合。
首先 Zander 說明了 Sunlight 團隊如何使用二分圖(bipartite graph)來建立這個網路,第一類的 node 代表行業,第二類的 node 代表個別的法案,而 edge 則是從第一類的 node 連到第二類的 node 上(也就是從各個行業連到他們所遊說的法案上),而 edge 的權重(weight)就是依照遊說活動的數量來決定(也就是遊說報告的數量),這樣的網路圖雖然保有很精確的資訊,但是在視覺上其實很難看出什麼東西:
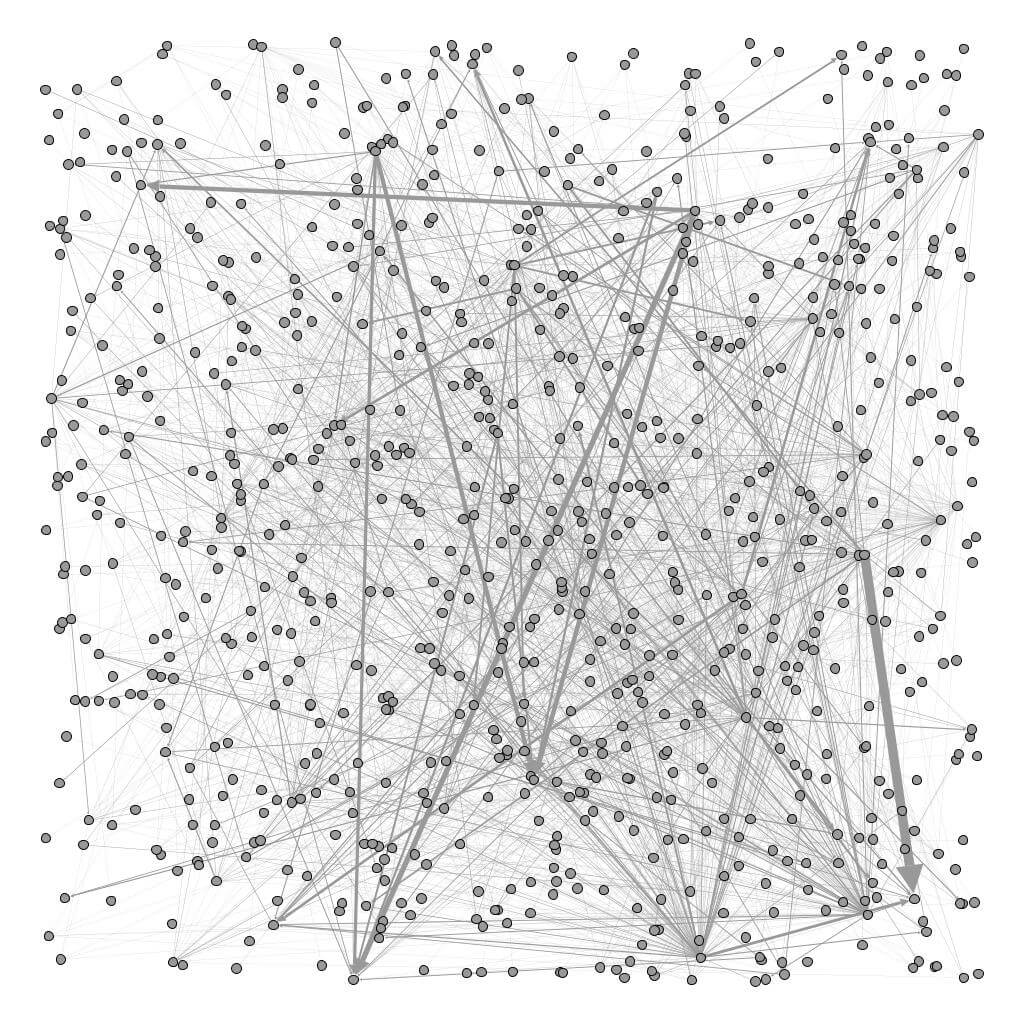
接著 Zander 說明如何化簡這張網路圖的方法,他將那些比較少進行遊說活動的行業剔除,只要某個行業所參與的遊說活動數量低於一個門檻值,就把它的資料拿掉不看,而所使用的方法是 K-Core sub-graph 方法(degeneracy 設為 3),經過 K-Core 的篩選之後,得到的網路圖雖然比較乾淨,但視覺上還是有點凌亂。接著他們使用 Gephi(一個開放原始碼的視覺化工具)的 OpenOrd layout 功能,把這些資料整理後產生一些比較緊密的群集,然後他又再使用加權的 nodes(行業與法案的權重都來自於它們的遊說活動數量)來改善整張網路圖。
在 Zander 分析完成後,又交給 Sunlight 的圖形設計師 Amy Cesal,她的任務就是美化 Zander 所建立的網路圖,經過他的設計之後,得到這樣的網路圖:
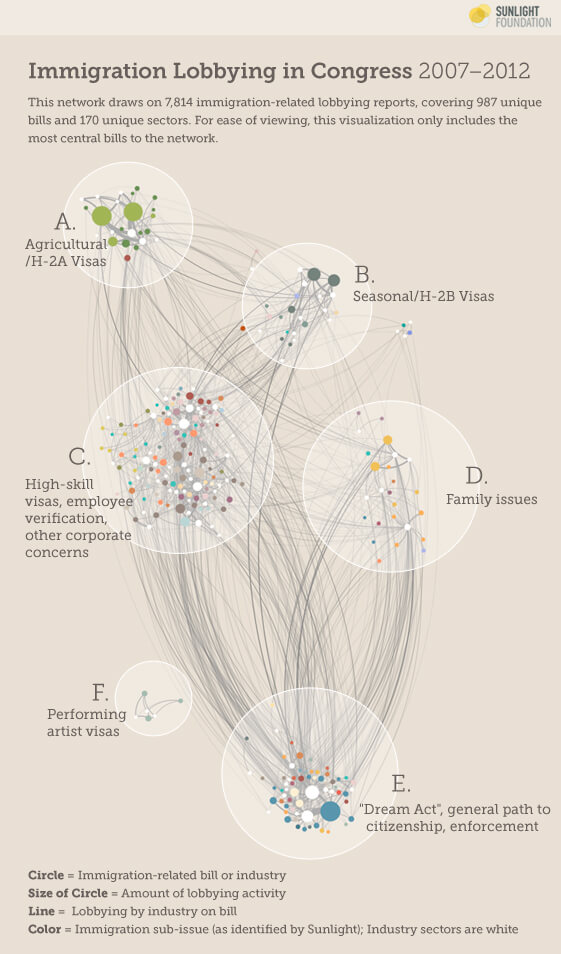
透過這樣比較清楚又容易理解的網路圖,我們就可以瞭解在這將近八千份的報告中,所隱藏的資訊:
- 整體來看,我們可以看到近年來遊說活動的五大議題(也就是圖中的 A 到 F 這五個大圈圈)。
- 如果我們將焦點放在單一個議題中(A 到 F 其中一個圈圈中),可以看到更細部的但比較雜亂的各種問題。
- 最後,透過[互動式的網路圖][4],我們可以探索每個議題與法案之間的關係,這裡面包含成千上萬的連結。
如果你想知道更詳細地分析報告,可以去看 Sunlight Fundation 官方部落格上的說明文章。
這裡有一點很重要,Lee、Zander 與 Amy 現在也常常進行類似這樣的資料分析,因為現在很多的機構不管是政府機關或是民營企業,每天都會有很多像這樣凌亂的資料產生,但這些資料除了取得之外,更重要的是分析它們,並轉換成一般人可以理解的形式,否則這樣的大量資料(Big Data)很快地就會變成大量垃圾(Big Garbage)。
資料科學家就是負責把這些資料轉換成大家都看得懂的形式,他們必須要有很穩固的數學與統計的基礎以及程式設計得能力,甚至要具備基本的美學概念,然後才能分析這些資料,並轉換為對大家有意義的形式。而具備這樣能力的資料科學家,其實在資料科學的領域中是很有價值的。