避免累積太多的 Technical Debt
Technical debt 是指一個專案或程式開發工作在真正完成前,所有應該做完的工作,如果一個專案中所累積的 technical debt 太多而沒有適時消化,到最後這個專案就容易出現問題,甚至可能因此終結。
這裡舉個簡單的例子,在一般的專案的發展過程中,有時候程式設計師會有一些新的想法,這時候他會想要在程式中加入這個新的程式,但是因為程式還在開發,很難一次把所有該更新或改寫的地方一次補齊,例如當程式加入一個新功能時,卻沒有更新對應的說明文件等等,而這些說明文件以及其他該更新的地方,就是常見的 technical debt。
這時候如果很不幸的,原本這個開發團隊因為某些原因離開了,專案交由令一個團隊繼續開發,那些新增之後卻沒有文件的功能就是個大問題,新團隊要花費更多的時間搞清楚它是什麼,如果它裡面還有 bug 的話那就更慘了。

類似像這樣的問題如果持續累積,當 technical debt 多到一定的程度時,程式設計師可能修正這些舊功能的問題就已經佔去他大部分的時間了,沒時間加入新的功能,所以整個專案的發展就停滯在這裡,甚至關閉整個專案。
一般會產生 technical debt 的原因,大致上可歸類為下面幾項:
- 商業壓力(business pressures):由於商業問題,產品常常需要在專案所有的工作都完成前推出,這樣就直接造成一些未完成的 technical debt。
- 欠缺處理或考量(lack of process or understanding):因為站在商業營運獲利的角度上,很容易忽略 technical debt 這件事,並且在沒有考慮後續影響的情況下做出決策。
- 缺乏建立低耦合元件(lack of building loosely coupled components):程式中所有的功能如果都綁在一起,沒有被適當的模組化,降低各元件的耦合程度,那這樣的軟體會非常沒有彈性,一旦需求變動之後,很多東西就要重寫,寫不完的東西就變成 technical debt。
- 缺乏除錯套件(lack of test suite):專案中若有完整的除錯套件,可以讓除錯的效率增加,減低專案的風險,反之若是缺乏除錯套件,那這些除錯工作就可能成為一個 technical debt。
- 缺乏文件(lack of documentation):在程式開發之後,沒有撰寫對應的說明文件,這種狀況是一定會造成 debt 的,而且在實際的專案發展中也常常發生。
- 缺乏合作(lack of collaboration):整個組織中沒有好的合作關係,知識與技術沒有充分交流,間接影響整體開發效率。
- 平行開發(parallel development):同時以兩個以上的分支(branches)進行獨立的開發,到後來就會產生 technical debt,因為所有的分支到最後都要合併為一個,而在這中間只要獨立開發出越多的功能,最後的合併時就會有更多的 debt。
- 太慢進行重構(delayed refactoring):在程式的發展過程中,隨著需求的演進,程式內部的程式結構也會越來越笨拙(失去彈性),這時候就必須對程式進行重構,將程式重新整理過。而進行重構的時機如果拖的越久,那就會有越多的程式以現有的架構撰寫,這樣就會造成在重構時有更多的 debt 需要改寫。
基本上要維持專案與程式的彈性與發展性,在適當的時機就要把這些 technical debt 處理掉,這樣專案與程式才有機會永續發展。
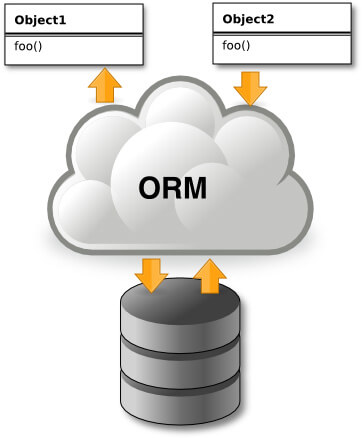
物件關聯對應(ORM)
物件關聯對應(ORM,Object Relational Mappers)是一種程式設計的技術,用在物件導向的語言中,實作不同類型系統之間資料的轉換,它建立一種可以用於程式中的「虛擬物件資料庫」,讓程式設計師在撰寫程式時比較方便。
由於物件導向是從軟體工程基本原則(如耦合、聚合、封裝)的基礎上發展起來的,而關聯式資料庫則是從數學理論發展而來的,兩套理論存在顯著的區別,而 ORM 就是為了解決兩者之間的差異而產生的。
目前在市面上的 ORM 函式庫很多,免費的與付費的都有,像 Hibernate 就是一很常見的 Java ORM 函式庫,其它還有很多各式各樣的 ORM 函式庫,若想研究這類的軟體,可以參考 Wiki 的列表。
雖然 ORM 非常普及,許多程式設計師都很喜歡它,但是程式效能的專家通常比較少在使用 ORM,你知道為什麼嗎?
其實這是魚與熊掌不可兼得的問題,在一般的商業軟體中,程式設計是以符合商業需求為考量,以這樣的前提下,你會在程式中實作各種功能,讓你的軟體具備各式各樣吸引人的特色,程式的效能與擴充性通常不是第一優先的考量。
透過 ORM 的架構可以讓程式設計師更快地開發出新穎且強大功能,並且可以免除使用 SQL 語法雨後端資料庫溝通的困擾,讓程式設計者可以更專注於發展新的功能。
但是站在效能的考量上,許多事情又不一樣了。當 ORM 要與資料庫溝通的時候,它會自己自動產生所有 SQL 的 query,而這樣的做法雖然方便,但是 ORM 自動產生的 query 通常比程式設計師自己寫的還要複雜,這樣會導致資料庫無法對這些 query 做一些最佳化的動作,造成資料庫查詢時的效能降低。
但基本上 ORM 所帶給你的許多好處,通常可以足以彌補它在的效能上的缺點,一般來說你應該不太需要擔心 ORM 的效能影響,在程式發展初期你可以選擇適當的 ORM 使用,加速各種功能的發展,而到後期的效能測試,若真的發現瓶頸出現在資料庫的查詢時,再考慮將 ORM 拿掉(亦可考慮 caching 與 database indexes 的方式),這樣是比較實際的做法,因為在大部分的情況下,ORM 的效能應該不至於影響太大,除非你的程式中有非常頻繁的資料庫查詢等動作,否則應該都是沒問題的。
Synchronous、Serial、Coupled 或 Locking Processes
資料庫的鎖定(Locking)功能
在網頁應用程式中使用資料庫的鎖定(locking)功能就像現實生活中的紅綠燈,通常如果把紅綠燈換成圓環,可以動態的增加可通過這個路口的車流量,當車流量不大時,圓環不會像紅綠燈一樣讓一些車子在路口空等,而在尖峰時刻圓環也可以消化大量的車流量。
如果你真的需要在程式中使用鎖定功能,那麼請使用 InnoDB 的表格(table),因為它有提供比較低階的鎖定功能,你可以不必每次都鎖定整個表格(像 MyISAM 就是這樣)。
Replication
當資料庫的使用量太大而一台 MySQL 伺服器無法負荷時,可以使用多台 MySQL 伺服器同時服務。
MySQL 資料庫的 replication 功能可以用來同步兩台 MySQL 伺服器之間的資料,將一台主要(master)MySQL 資料庫伺服器上的資料複製到備援(slave)的 MySQL 資料庫伺服器上。
透過多台 MySQL 資料庫伺服器與 replication 功能,可以分散流量,讓系統可以負荷更多的使用者。
Semi-Synchronous Replication
Replication 在預設的狀況下是非同步的(asynchronous),也就是說 slave 伺服器不會隨時都與 master 伺服器連線進行同步,而是每隔一段時間才會連到 master 來更新自己的資料。在這樣的情況下,master 伺服器會將所有的 events 先紀錄在二進位的紀錄檔中,但卻不知道 slave 伺服器什麼時候會抓回去執行,如果時候 master 伺服器壞掉了,那些已經被 committed 的交易(transactions)可能根本沒有被送到任何的 slave 伺服器上,這樣就造成資料不同步的錯誤了。

而後來有一種新的半同步 replication(semi-synchronous replication),就是在 master 伺服器上負責交易交付(commit)的執行序(thread),在執行交付之後會等待(也就是 blocking)所有被交付的交易都被至少一個 slave 伺服器全部接收之後才會結束,或是持續等待直到 timeout 發生。
雖然半同步的 replication 可以避免不同步的錯誤發生,但是在交易很頻繁的伺服器上,可能會造成很多的執行序同時在執行,拖慢整個系統效能,所以半同步的 replication 在使用上要注意這一點。
兩段式交付(Two-Phase Commit)
在許多分散式的資料庫系統中,兩段式交付(two-phase commit)是很常見的,然而這樣的機制也是會造成 blocking 的問題,對於系統的整體效能也會造成影響。
系統監控
在一個大型的系統中,如果沒有適當的系統監控工具的幫助,是很難掌握系統中發生哪些事情的,而這樣的狀況下也很難整合業務單位、開發團隊與營運團隊來一起處理擴充性的問題。
一般常用的系統監控工具很多,例如一些使用 SNMP 的 Cacti、Munin、OpenNMS、Ganglia 與 Zabbix 等,你可以選擇適合自己的工具來及時監控自己的系統,通常這類的工具都可以幫你監控很多常用的資訊,例如 CPU、記憶體、磁碟與網路等等,甚至資料庫的 buffer pool、交易記錄、locking sorting、暫存表格與每秒的 queries 量。
除了監控一些系統底層的資訊之外,你也應該關心一些比較應用上的資訊,例如註冊的使用者數,或是軟體銷售量等。
參考資料:High Scalability
前一篇:提高系統與程式擴充性(Scalability)與效能(Performance)的十個方法(ㄧ)