這裡介紹如何運用 R 的 rvest 套件來擷取任何的網頁資料,直接將資料從網頁中萃取出來,匯入 R 中進行後續的處理。
在巨量資料(big data)與物聯網(IOT)的時代,有相當多的資料都是透過網路來取得的,由於資料量日益增加,對於資料分析者而言,如何使用程式將網頁中大量的資料自動匯入是很重要的。
許多程式語言都有網頁擷取的工具可以使用,R 語言也不例外,以下我們要介紹如何使用 R 的 rvest 套件擷取任意的網頁資料,並將大量結構化的資料直接匯入 R 中,讓資料分析者可以省去手動整理資料的時間。
網頁資料結構
首先我們要先簡單介紹 HTML 的資料結構,以及 CSS 選擇器(selector)的使用方式,有了這些觀念才能精準地抓出網頁中的資料。
HTML 資料基本觀念
目前網路上絕大部分的網頁都是以 HTML 格式來呈現的,因此若想要抓取其中的資料,就必須對 HTML 的格式有初步的了解,這裡簡單介紹基本 HTML 的資料格式與概念,有了基本的概念才能做進一步的資料擷取。若您已經熟悉 HTML 的語法,可以跳過這一段的說明。
以下是一個簡單的 HTML 網頁原始程式碼。
<html>
<head>
<title>網頁標題</title>
</head>
<body>
<div class="container">
<p>網頁內容</p>
<p>
<ul>
<li>foo</li>
<li>bar</li>
</ul>
</p>
</div>
</body>
</html>
一個 HTML 網頁中含有各種網頁的元素(elements),每一個元素通常都會使用 HTML 的標籤(tags)前後包起來,例如:
<p>網頁內容</p>
而大部分的 HTML 元素都是以巢狀的資料結構存在的,也就是說一個元素中可能還會包含其他很多不同的元素,例如:
<ul>
<li>foo</li>
<li>bar</li>
</ul>
這樣的狀況就是一個 <ul> 元素中還包含兩個 <li> 元素。
基本上每一個 HTML 網頁中的資料都是以這樣的階層式規則來呈現的,當要抓取網頁中的資料時,只要明確得知資料在這個階層結構中的位置,就可以很容易的將資料以程式自動取出。
若只是要抓取網頁資料,僅需了解 HTML 基本的朝狀結構概念即可,網頁中的每個 HTML 標籤都有不同的意義,關於細部的內容請自行參考網路上的教學。
CSS 選擇器(Selector)
CSS 選擇器(Selector)是 CSS 用來指定網頁元素的一種語法,假設一個 HTML 網頁中有一個 <p> 元素:
<p class="key" id="principal"> ... </p>
若要使用 CSS 選擇器來選擇這個元素的話,可以直接寫標籤名稱:
p { /* CSS 設定值 ... */ }
這樣寫的意思就是取出所有網頁 HTML 中所有的 <p> 元素,但是這樣可能會連同其它不需要的 <p> 元素也一起選取進來,如果要更精準的選取元素,可以加上 class 屬性的資訊:
p.key { /* CSS 設定值 ... */ }
這樣就會選取網頁中 class 屬性為 key 的 <p> 元素,另外也可以單獨使用 class 屬性來篩選:
.key { /* CSS 設定值 ... */ }
這樣就會選取網頁中 class 屬性為 key 的所有元素。最精準的方式則是使用 id 屬性:
#principal { /* CSS 設定值 ... */ }
這樣就會選取網頁中 id 屬性為 principal 的元素。
對於比較複雜的結構,也可以用階層式的 CSS 選擇器來指定,假設 HTML 程式碼為:
<div class="foo">
<p>
<span class="bar"> ... </span>
</p>
</div>
若要選擇此結構下最內層的 <span> 元素,可以使用:
div.foo p span.bar { /* CSS 設定值 ... */ }
以上就是基本的 HTML 結構與 CSS 選擇器的概念,對於這些技術有基本的認識之後,就可以開始進行網頁資料的擷取工作了。
SelectorGadget
SelectorGadget 是 Google Chrome 瀏覽器的一個外掛工具,可以用來顯示網頁中任意元素的 CSS 選擇器路徑,幫助我們快速擷取網頁上的資料。
名稱:SelectorGadget
適用瀏覽器:Google Chrome
下載網址:Chrome 線上應用程式商店
官方網站:https://selectorgadget.com/
SelectorGadget 這個工具的安裝方式有兩種,一種是從 Chrome 線上應用程式商店直接安裝(一般使用者建議使用此方式),而另外一種則是直接將 SelectorGadget 官方網站上所提供的連結拖曳至瀏覽器書籤,要使用的時候點選這個連結即可。
安裝好 SelectorGadget 之後,我們以 R 語言的 Wiki 頁面來做示範,說明如何定位出網頁中的任何資料。
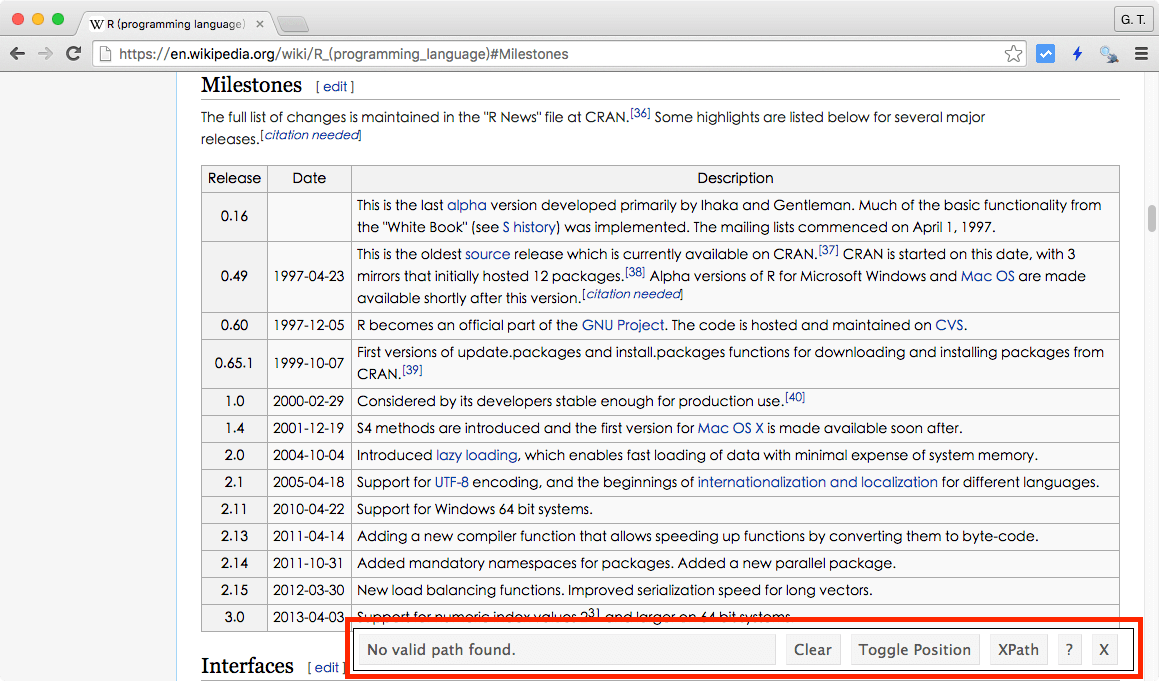
Step 1
打開 R 語言的 Wiki 頁面,並開啟 SelectorGadget 工具列,SelectorGadget 工具列在開啟之後,就會顯示在頁面的右下角。
Step 2
使用滑鼠點選要擷取的資料。
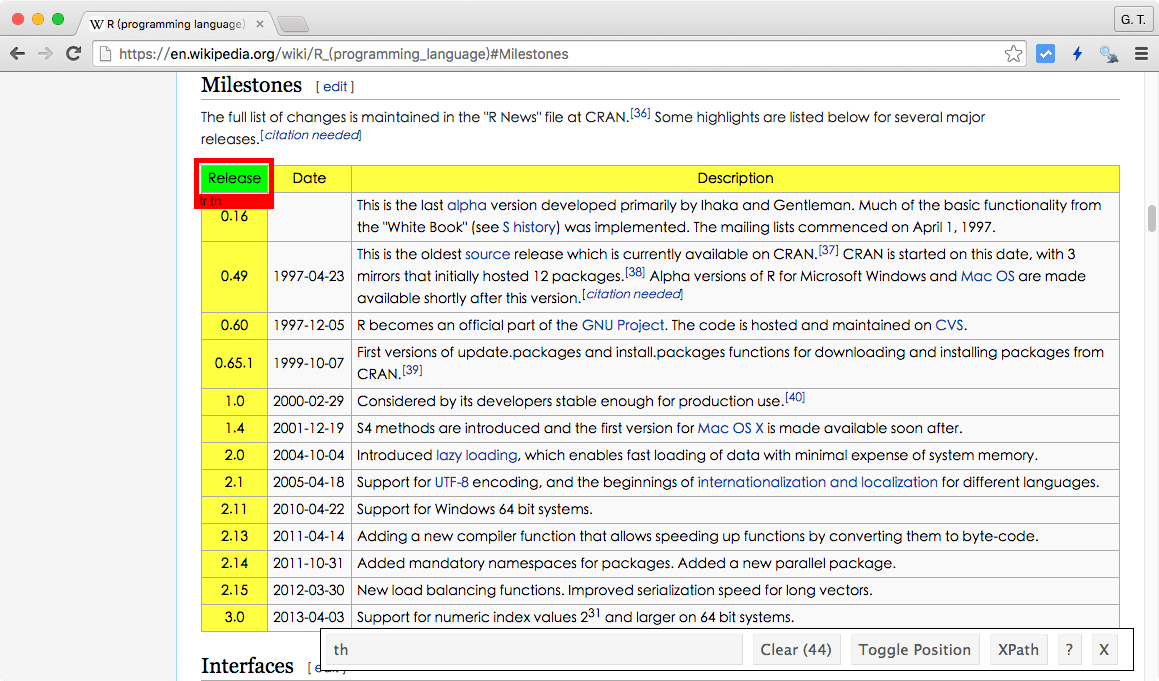
被點選的 HTML 元素會以綠色標示,而這時候 SelectorGadget 會嘗試偵測使用者想要抓取資料的規則,產生一組 CSS 選擇器並顯示在 SelectorGadget 工具列上,同時網頁上所有符合這組 CSS 選擇器的 HTML 元素都會以黃色標示,也就是說目前這組 CSS 選擇器會擷取所有綠色與黃色的 HTML 元素。
Step 3
通常 SelectorGadget 所自動偵測的 CSS 選擇器可能會包含一些我們不想要的資料,這時候請使用滑鼠將那些被標示為黃色但是應該要排除的 HTML 元素。
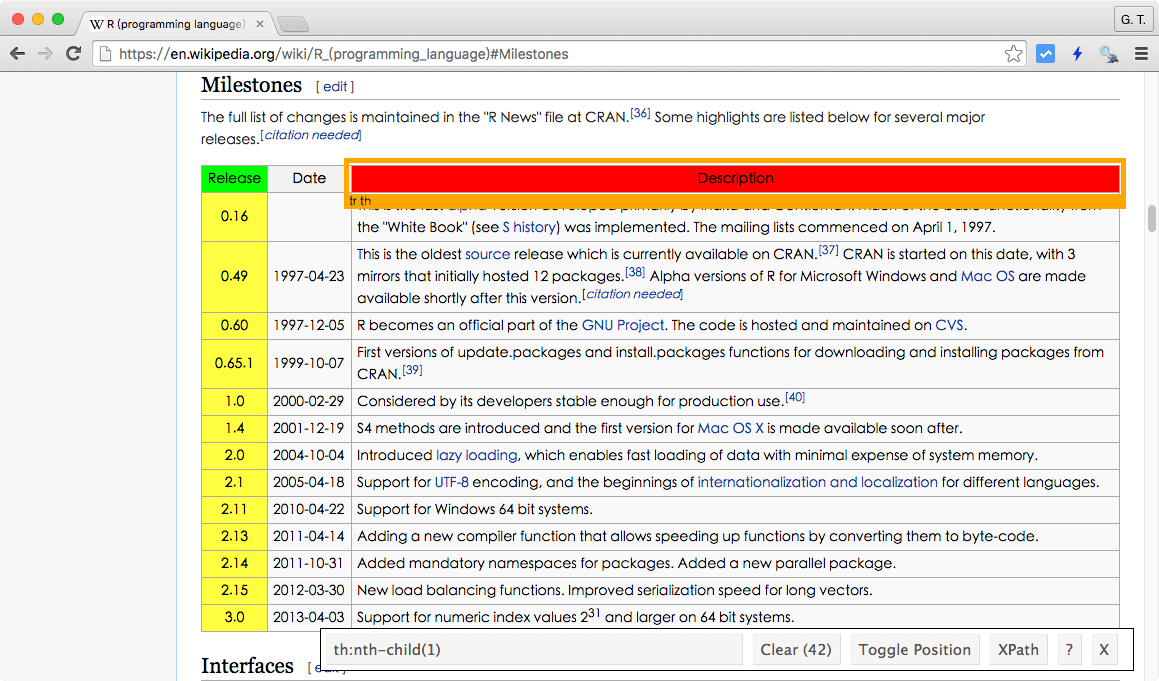
當滑鼠點擊黃色的元素之後,該元素就會變成紅色,並且將該元素排除在外。
Step 4
使用滑鼠的選擇與排除功能,將所有要擷取的元素精準的標示出來,產生一組精確的 CSS 選擇器。
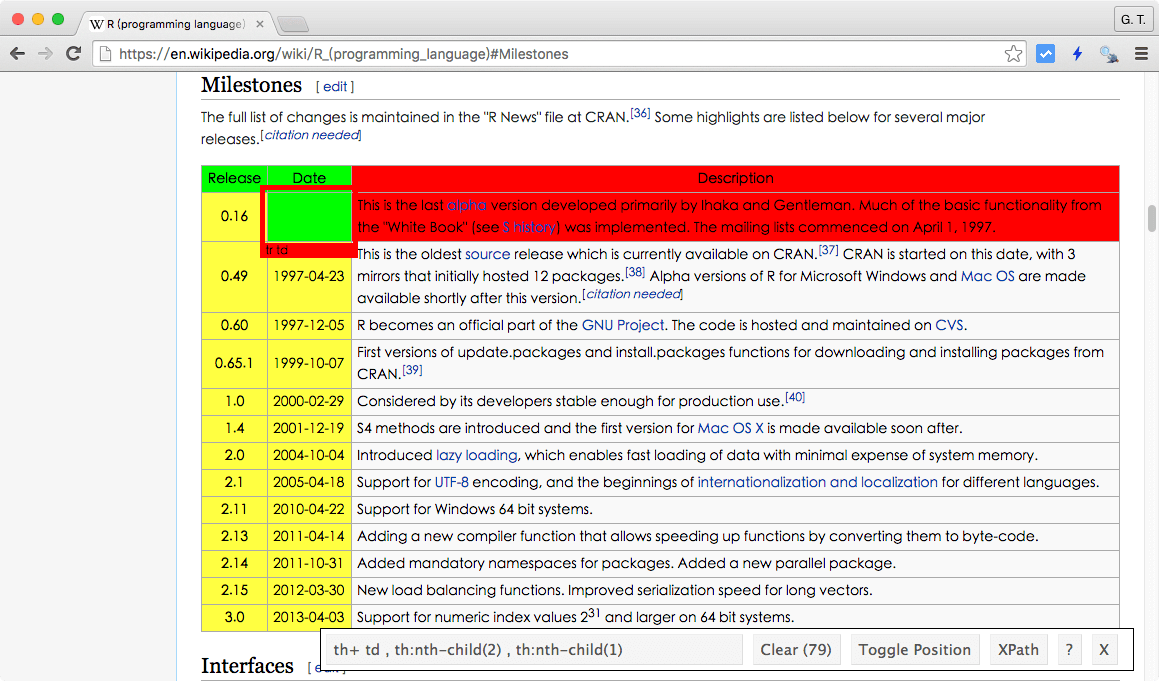
有了這組精確的 CSS 選擇器之後,就可以利用 R 的 rvest 套件來將資料直接截取至 R 中處理了。
R 的 rvest 套件
rvest 是一個專門用來擷取網頁資料的 R 套件,可以跟 magrittr 套件配合使用,建立複雜的資料流管線操作。
基本用法
首先從 CRAN 安裝 rvest 套件:
install.packages("rvest")
library(rvest)
使用 read_html 函數先將整個網頁的原始 HTML 程式碼抓下來:
page.source <- read_html("https://en.wikipedia.org/wiki/R_(programming_language)")
再使用 html_nodes 函數,配合 CSS 選擇器將指定的資料取出來:
version.block <- html_nodes(page.source, ".wikitable th+ td , th:nth-child(2) , .wikitable th:nth-child(1)")
head(version.block)
{xml_nodeset (6)}
[1] Release
[2] Date
[3] 0.16
[4]
[5] 0.49
[6] 1997-04-23 使用 html_text 將 HTML 程式碼中的文字資料取出來:
content <- html_text(version.block)
head(content)
[1] "Release" "Date" "0.16" "" "0.49" "1997-04-23"
其他用法
html_nodes 函數也支援 xpath 的指定方式:
version.block2 <- html_nodes(page.source, xpath = '//table[@class="wikitable"]//tr//th')
content2 <- html_text(version.block2)
head(content2)
[1] "Release" "Date" "Description" "0.16" "0.49" "0.60"
html_name 可以列出所有的 HTML 元素標籤:
html_name(version.block)
[1] "th" "th" "th" "td" "th" "td" "th" "td" "th" "td" "th" "td" "th" "td" "th" "td" "th" [18] "td" "th" "td" "th" "td" "th" "td" "th" "td" "th" "td"
html_attrs 可以列出每個 HTML 元素的所有屬性:
el.attrs <- html_attrs(version.block)
head(el.attrs)
[[1]]
named character(0)
[[2]]
named character(0)
[[3]]
named character(0)
[[4]]
named character(0)
[[5]]
named character(0)
[[6]]
style
"white-space:nowrap;"html_attr 則是可以列出每個 HTML 元素的特定屬性:
el.attr <- html_attr(version.block, "style")
head(el.attr)
[1] NA NA NA [4] NA NA "white-space:nowrap;"
實際範例
Yahoo 首頁
以下是從 Yahoo 首頁擷取熱門關鍵字以及頭條新聞標題的範例:
library(rvest)
# 下載 Yahoo 首頁
page.source <- read_html("https://tw.yahoo.com/")
# 篩選出熱門關鍵字
hot.keywords <- html_nodes(page.source, ".keywords .Whs-nw")
html_text(hot.keywords)
# 篩選出頭條新聞標題
news.title <- html_nodes(page.source, ".Va-tt")
html_text(news.title)
StackOverflow
以下是從 StackOverflow 首頁擷取問題標題與瀏覽量的範例:
library(rvest)
# 下載 StackOverflow 首頁資料
page.source <- read_html("https://stackoverflow.com/")
# 篩選出問題的標題與瀏覽量
q.summary <- html_nodes(page.source, ".question-summary")
for ( s in q.summary ) {
q.link <- html_nodes(s, ".question-hyperlink")
cat("Title:", html_text(q.link), "n")
q.views <- html_nodes(s, ".views .mini-counts")
cat("Views:", html_text(q.views), "n")
}