這裡介紹如何使用 R 的基本資料探索函數與繪圖功能,檢視首次拿到的資料。
當我們將資料整理好並匯入 R 環境中之後,下一步就是要仔細檢視資料本身所含有的資訊,而最常被用來檢視原始資料的方法就是一些基本的統計量與各種圖形,R 本身就有內建計算各種統計量與繪圖的函數,以下我們將介紹比較常用的一些基本函數及其使用方式。
敘述統計
在前面的教學內容中,我們已經有提到好幾種計算基本統計量的函數,其中有許多函數只要看到函數名稱就可以了解它的作用,例如計算平均數的 mean 與計算中位數的 median 等,我們以 iris 這個 R 內建的鳶尾花資料集來做示範:
mean(iris$Sepal.Length)
[1] 5.843333
median(iris$Sepal.Length)
[1] 5.8
鳶尾花資料集(
iris)是一組非常著名的生物資訊資料集,資料筆數總共有 150 筆,每筆資料有 5 個欄位,各欄位的意義如下:
Sepal.Length:花萼長度,計算單位是公分。Sepal.Width:花萼寬度,計算單位是公分。Petal.Length:花瓣長度,計算單位為公分。Petal.Width:花瓣寬度,計算單位為公分。Species:品種,可分為Setosa、Versicolor與Virginica三種。關於鳶尾花資料集的詳細描述,可以參考維基百科的資料。
min 與 max 分別可計算資料的最小值與最大值:
min(iris$Sepal.Length)
[1] 4.3
max(iris$Sepal.Length)
[1] 7.9
range 則可計算資料的分佈範圍,也就是最小值與最大值:
range(iris$Sepal.Length)
[1] 4.3 7.9
table 函數可以計算類別型資料的列聯表(contingency table):
table(iris$Species)
setosa versicolor virginica
50 50 50對於連續型的變數,可以使用 cut 將資料分成多個區間,再用 table 計算每個區間的資料數目:
table(cut(iris$Sepal.Length, seq(4,8)))
(4,5] (5,6] (6,7] (7,8] 32 57 49 12
var 與 sd 兩個函數可以計算資料的變異數與標準差:
var(iris$Sepal.Length)
[1] 0.6856935
sd(iris$Sepal.Length)
[1] 0.8280661
mad 函數則可計算平均絕對偏差(median absolute deviation):
mad(iris$Sepal.Length)
[1] 1.03782
quantile 可以計算資料的各個分位數:
quantile(iris$Sepal.Length)
0% 25% 50% 75% 100% 4.3 5.1 5.8 6.4 7.9
可以自行指定分位數的機率值:
quantile(iris$Sepal.Length, c(0.9, 0.95, 0.99))
90% 95% 99% 6.900 7.255 7.700
fivenum 也是一個可以計算各個分位數的函數,不過它的計算速度比 quantile 快一些:
fivenum(iris$Sepal.Length)
[1] 4.3 5.1 5.8 6.4 7.9
summary 可以計算向量或 data frame 的一些基本統計量:
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50 Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50 Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
cor 函數可以計算兩個向量之間的相關係數:
cor(iris$Petal.Length, iris$Petal.Width)
[1] 0.9628654
cancor 函數則可計算更詳細的相關係數資料:
cancor(iris$Petal.Length, iris$Petal.Width)
$cor
[1] 0.9628654
$xcoef
[,1]
[1,] 0.04640756
$ycoef
[,1]
[1,] 0.1074772
$xcenter
[1] 3.758
$ycenter
[1] 1.199333而 cov 則可計算共變異數:
cov(iris$Petal.Length, iris$Petal.Width)
[1] 1.295609
R 繪圖系統
R 具備了相當完整的繪圖功能,而其繪圖系統大致可分為三大類:
base 與 grid 系統
base 是最早期的 R 繪圖系統,功能比較簡單、上手也很容易,但擴充性較差,若要繪製較複雜的圖形會有一些困難。而由於 base 繪圖系統在使用上有些限制,所以後來又發展出一套 grid 繪圖系統,它可以讓使用者以較低階的方式繪圖,例如繪製點、線或是方塊等,雖然 grid 的彈性很大,但是對於資料量比較大的圖形,要用這麼低階的方式畫圖還是會有困難。
lattice 系統
lattice 是根據 grid 為基礎所發展出來的一套繪圖系統,對於各種常見的圖形提供了比較高階的繪圖函數,跟傳統的 base 系統相較之下,lattice 主要有兩個特點:
- 所有的繪圖結果都可以儲存在變數當中(不像
base是直接畫在螢幕上的),也就是說在lattice系統之下,使用者可以對畫出來的圖形做進一步的修改,然後再重新畫出新的結果,對於一系列相類似的圖組也可以使用這樣的技巧加速繪圖的速度,另外也可以把繪圖結果儲存下來,供日後使用。 lattice的第二個特色則是一張圖形中可以包含多個子繪圖區域,亦即使用者可以將多張子圖形直接放在同一張圖中一起比較,省去了自己手動合併多張圖形的困擾。
ggplot2 系統
ggplot2 也是一個以 grid 所發展出來的繪圖系統,承襲了 lattice 的兩大特色,並加入了繪圖文法的概念,其名稱中的 gg 所代表的是 grammar of graphics,意指將圖形拆解成許多組件的繪圖系統,語法與傳統式的單一函數呼叫繪圖有些不同,而其所產生的圖形也比前兩種繪圖系統美觀。
很不幸地這三種 R 繪圖系統在大部分的狀況下都不相容,雖然最新的 ggplot2 繪圖系統的功能相當完整,而且畫出的圖形也比較漂亮,多數的圖形都可以使用 ggplot2 來完成,但是由於舊的兩個繪圖系統已經在 R 中存在相當長一段時間,有非常大量的 R 套件在繪圖的功能上都是使用這兩個舊系統,所以在使用 R 時難免都會接觸到,所以還是對它們需要有基本的認識。
以下我們介紹各種常見的基本圖型在三種系統的繪圖方式。
散佈圖(Scatter Plots)
散佈圖應該是最簡單也最常用的圖形,主要可以用來檢視不同資料之間的關係。
base 系統
在 base 系統可以使用 plot 函數來畫出資料的散佈圖。
plot(iris$Petal.Length, iris$Petal.Width)
plot 函數有許多可調整的參數,col 參數可以調整資料點的顏色,顏色可以使用名稱或是類似 HTML 的十六進位碼來指定,而 pch 可以更換資料點的樣式:
plot(iris$Petal.Length, iris$Petal.Width,
col = "red", pch = 8)
若要以 base 繪圖系統將多張圖畫在一起,需要先以 layout 先設定排版方式,雖然可行,但是會比較麻煩一點:
par(mar = c(3, 3, 0.5, 0.5), oma = rep.int(, 4), mgp = c(2, 1, ))
species <- levels(iris$Species)
plot_numbers <- seq_along(species)
layout(matrix(plot_numbers, ncol = 3, byrow = TRUE))
for(s in species) {
data.by.species <- subset(iris, Species == s)
with(data.by.species, plot(Sepal.Length, Sepal.Width))
}
關於 plot 函數的詳細使用方式,可以參考 R plot 繪圖函數。
lattice 系統
在 lattice 繪圖系統中,若要繪製散佈圖則可使用 xyplot,這個函數是以公式(formula)的方式來指定 x 與 y 軸的資料(關於公式的寫法,可以參考 R 機率分佈與線性模型):
library(lattice)
xyplot(Petal.Width ~ Petal.Length, iris)
大部分 xyplot 的參數使用方式跟 base 系統的 plot 相同:
xyplot(Petal.Width ~ Petal.Length, iris, col = "red", pch = 8)
由於 xyplot 是使用公式的方式指定繪圖用的資料,如果要將資料先分組後再畫出每一組的圖形,使用公式的做法非常簡潔:
xyplot(Petal.Width ~ Petal.Length | Species, iris)
layout 參數可以整圖形的排版:
xyplot(Petal.Width ~ Petal.Length | Species,
iris, layout = c(3, 1))
使用 lattice 繪圖系統所繪製的圖形可以儲存在變數中,在圖形畫出來之後,還可以陸續更新:
my.plot <- xyplot(Petal.Width ~ Petal.Length | Species,
iris, layout = c(3, 1))
my.plot2 <- update(my.plot, col = "red", pch = 8)
my.plot2
ggplot2 系統
ggplot2 的繪圖方式與以往的繪圖系統有一個根本上的差異,每一張圖都會以 ggplot 函數來建立基本的 ggplot 繪圖物件,並指定資料來源以及資料與圖形之間的對應關係,接著再用加號(+)連接後續的繪圖類型與細部參數:
library(ggplot2)
ggplot(iris, aes(x = Petal.Length, y = Petal.Width)) +
geom_point()
ggplot 的第一個參數是指定資料來源的 data frame,而第二個參數則是指定資料與圖形的對應關係,其中 aes 是 ggplot 系統中專門用來指定資料與圖形對應關係的函數,在建立基本的繪圖物件之後,我們再加上一個 geom_point 指定以資料點的方式繪製散佈圖。
若要改變資料點的顏色與樣式,可以在 geom_point 函數中加上一修調整的參數:
ggplot(iris, aes(x = Petal.Length, y = Petal.Width)) +
geom_point(color = "red", shape = 8)
若要將資料分組繪圖,可以在繪圖指令的最後加上一個 facet_wrap,其用法與 lattice 系統類似,也是以公式的方式指定資料:
ggplot(iris, aes(x = Petal.Length, y = Petal.Width)) +
geom_point() +
facet_wrap(~ Species, ncol = 3)
這裡所使用的公式 ~ Species 代表以 Species 變數分組,若要以多個變數分組,則可以使用類似 ~ var1 + var2 + var3 這樣的寫法。如果要對兩個變數來分組,也可以使用 facet_grid 函數,他可以讓圖形以矩陣的形式呈現。
ggplot 跟 lattice 一樣可以將繪製出來的圖形儲存於變數之中,進行逐步修改:
my.ggplot <- ggplot(iris, aes(x = Petal.Length, y = Petal.Width)) +
geom_point()
my.ggplot <- my.ggplot + geom_abline(intercept = -0.3631, slope = 0.4158)
折線圖(Line Plots)
對於時間序列類型的資料,折線圖是一個最常被使用的圖形,以下是以 R 的三種繪圖系統繪製折線圖的方式。
base 系統
這裡我們產生一些隨機性的測試資料來示範折線圖的畫法。
set.seed(1)
y1 <- cumsum(rnorm(100))
x <- seq_along(y1)
在 base 系統中的折線圖也是使用 plot 函數來繪製,只是加上一個 type 參數:
plot(x, y1, type = "l", ylim = c(-5, 20))
這裡我在 plot 中多加上了一個 ylim 參數來指定 y 軸的繪圖範圍,如果不指定的話 R 也會自動判斷最佳的範圍。由於我隨後還要再加上另一條線,所以在一開始就要先將繪圖範圍設定成可以容納所有資料的大小,這樣後來再加上新的資料時才不會讓新的資料超出可繪圖的範圍。
若要在同一張圖上畫上多條折線圖,則第二條以後的折線圖可以使用 lines 加上去:
y2 <- y1 + abs(rnorm(100, 3))
lines(x, y2, col = "blue")
lattice 系統
lattice 系統的折線圖畫法也跟 base 系統類似,一樣是加上一個 type 參數:
my.df <- data.frame(x, y1, y2)
xyplot(y1 ~ x, my.df, type = "l")
若要同時畫上多條線,則可以將所有的資料以公式表示:
xyplot(y1 + y2 ~ x, my.df, type = "l")
ggplot2 系統
在 ggplot2 系統中繪製折線圖的方式跟散佈圖差不多,只是將 geom_plot 換成 geom_line 而已:
ggplot(my.df, aes(x = x, y = y1)) +
geom_line()
如果要在 ggplot 系統上同時畫出兩條線的話,情況會稍微複雜一些,由於在 ggplot 函數中使用 aes 所設定的資料與圖形對應關係會適用於整個圖形中所有的指令,相當於一個全域(global)的對應關係,而在這裡我們需要的是兩條線分別有不同的資料對應,所以我們將 y 軸的資料對應寫在個別的 geom_line 中,而 x 軸的對應則維持不變:
ggplot(my.df, aes(x = x)) +
geom_line(aes(y = y1)) +
geom_line(aes(y = y2))
另一種做法是將資料用 melt 重新整理過,然後使用 group 的方式繪圖:
library(reshape2)
my.df.melt <- melt(
my.df,
id.vars = "x",
measure.vars = c("y1", "y2")
)
ggplot(my.df.melt, aes(x = x, y = value, group = variable)) +
geom_line()
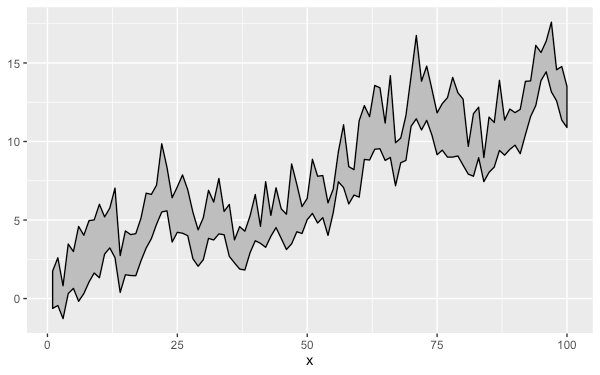
對於這種有兩條線的資料,ggplot 還提供一種 geom_ribbon 函數可以將兩條線中間的區域標示出來:
ggplot(my.df, aes(x = x, ymin = y1, ymax = y2)) +
geom_ribbon()
區域的顏色也可以自訂:
ggplot(my.df, aes(x = x, ymin = y1, ymax = y2)) +
geom_ribbon(color = "black", fill = "gray")
直方圖(Histograms)
直方圖也是一種很常見的圖形,它可以讓我們看出整個資料大致上的分佈狀況。
base 系統
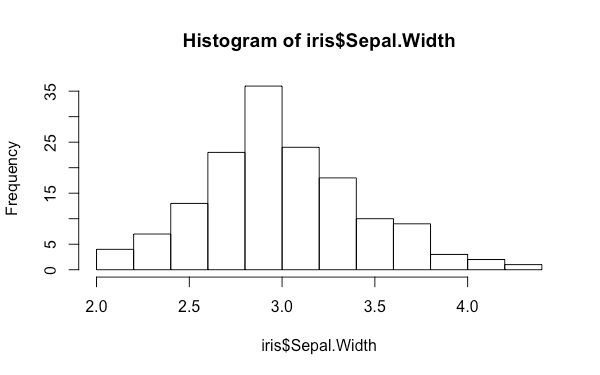
在 base 系統上的直方圖可以使用 hist 函數來繪製:
hist(iris$Sepal.Width)
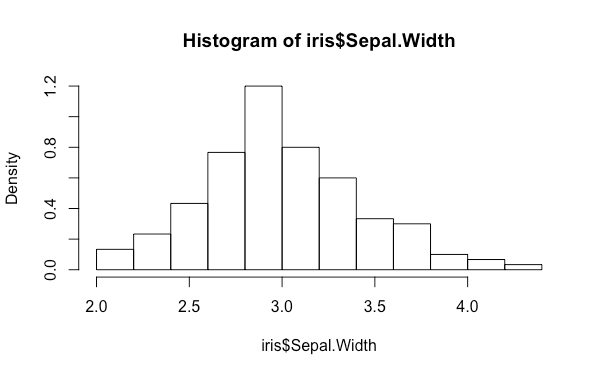
預設的狀況下 hist 繪圖時會以資料的頻率作為 y 軸的單位,若要以機率值為單位(總面積和為 1),可以將 freq 參數指定為 FALSE:
hist(iris$Sepal.Width, freq = FALSE)
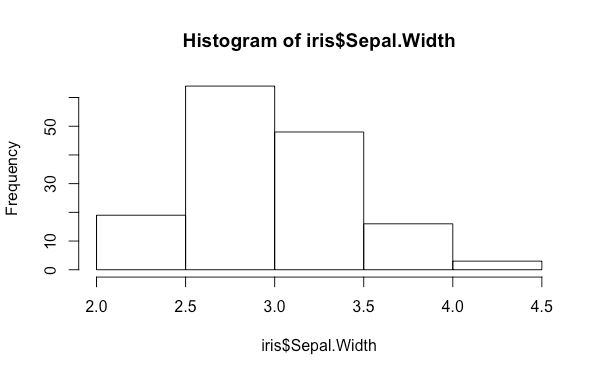
hist 預設會使用 Sturges 的方式自動計算 bin 的數目,我們也可以用 breaks 參數自行指定:
hist(iris$Sepal.Width, breaks = 5)
甚至也可以指定不等寬的 bins:
hist(iris$Sepal.Width, breaks = c(2, 2.7, 3, 3.5, 4.5))
lattice 系統
lattice 系統的直方圖可以使用 histogram 繪製,用法與 base 系統類似,只是改以公式的方式指定資料而已:
histogram(~ Sepal.Width, iris)
histogram 的 y 軸單位有三種方式選擇,分別為:percent、count 與 density:
histogram(~ Sepal.Width, iris, type = "count")
breaks 的用法也跟 hist 相同:
histogram(~ Sepal.Width, iris, breaks = 5)
ggplot2 系統
在 ggplot2 系統中直方圖可以使用 geom_histogram 繪製:
ggplot(iris, aes(Sepal.Width)) +
geom_histogram()
bins 可以指定 bin 的數量:
ggplot(iris, aes(Sepal.Width)) +
geom_histogram(bins = 5)
若要改變 y 軸的單位,可以從 aes 的對應關係來指定,可用的參數有 ..count.. 與 ..density..,分別代表次數與密度:
ggplot(iris, aes(x = Sepal.Width, y = ..density..)) +
geom_histogram(bins = 5)
箱形圖(Box Plots)
箱形圖的作用也是用來呈現資料的大致分佈情形,常用於比較不同資料之間的分布差異。
base 系統
在 base 系統中可用 boxplot 繪製箱形圖:
boxplot(InsectSprays$count)
若要依據變數來分組繪製箱形圖,可以使用公式的方式表示:
boxplot(count ~ spray, data = InsectSprays)
這樣就會以 spray 為依據,將 count 的值分組繪製箱形圖:
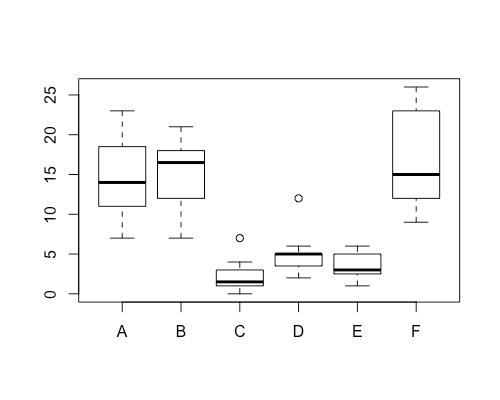
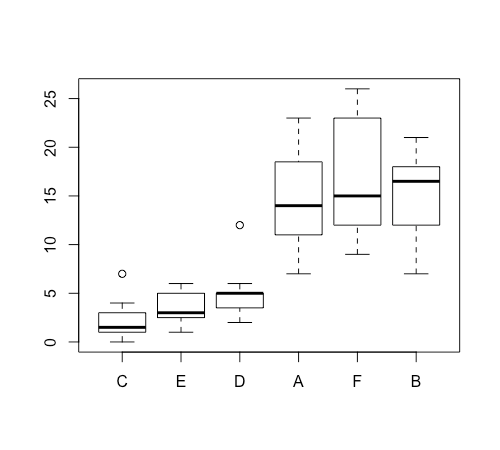
若要依照資料的中位數來排序畫出來的箱形圖,可以先將資料整理成一個排序好的 data frame,再呼叫 boxplot 繪圖:
my.InsectSprays <- within(
InsectSprays,
spray <- reorder(spray, count, median)
)
boxplot(count ~ spray, data = my.InsectSprays)
lattice 系統
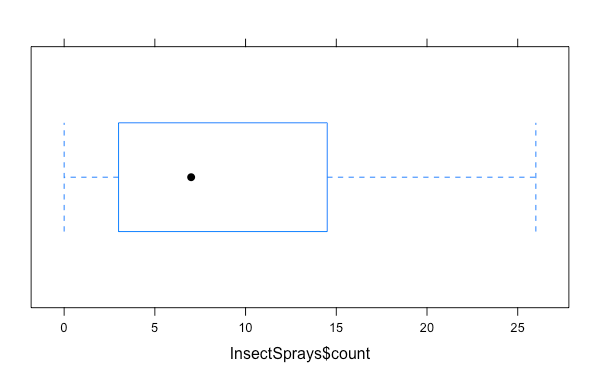
lattice 系統中可用 bwplot 繪製箱形圖,其用法跟 boxplot 幾乎一樣:
bwplot(InsectSprays$count)
依據變數分組的用法也相同:
bwplot(count ~ spray, data = InsectSprays)
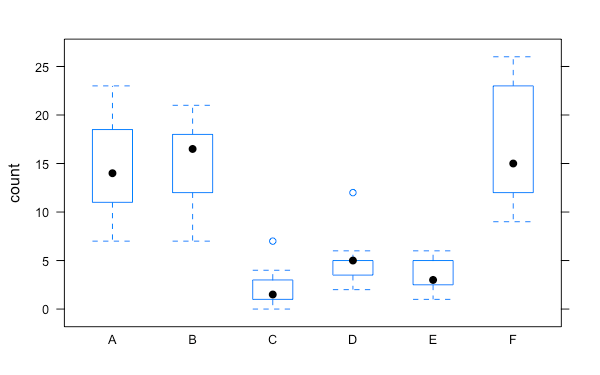
排序後的箱形圖:
bwplot(count ~ spray, data = my.InsectSprays)
ggplot2 系統
在 ggplot2 系統若要繪製箱形圖,可以使用 geom_boxplot:
ggplot(InsectSprays, aes(x = spray, y = count)) +
geom_boxplot()
排序後的箱形圖:
ggplot(my.InsectSprays, aes(x = spray, y = count)) +
geom_boxplot()
如果使要繪製單一變數的話,可以用這樣的方式:
ggplot(InsectSprays, aes(x = 1, y = count)) +
geom_boxplot()
將 x 軸與 y 軸互換:
ggplot(InsectSprays, aes(x = 1, y = count)) +
geom_boxplot() +
coord_flip()
長條圖(Bar Plots)
長條圖通常用來呈現各種不同資料的數量。
base 系統
在 base 系統中可以使用 barplot 來繪製長條圖,其第一個傳入的參數是一個向量,指定每一條 bar 的長度,如果該向量是一個具名向量,則每一個元素的名稱就會被用來當作每個 bar 的名稱:
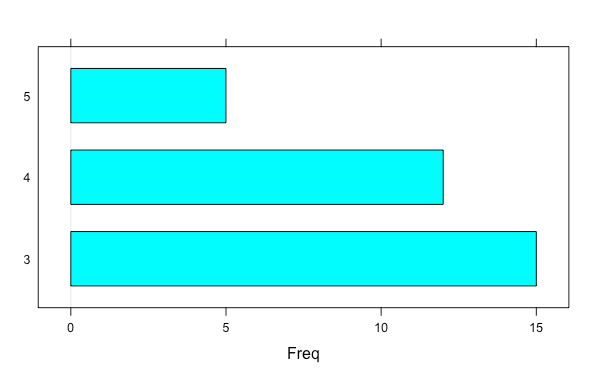
gear.table <- table(mtcars$gear)
gear.table
3 4 5 15 12 5
barplot(gear.table)
若要改變每個 bar 的名稱,可以使用 names.arg 參數來指定:
barplot(gear.table, names.arg = c("Three", "Four", "Five"))
有時候在資料比較多或是每個 bar 的名稱比較長的時候,將長條圖以水平的方式來畫會比較適合,barplot 本身有一個 horiz 參數可以調整繪圖方向,不過他只會更改圖形的方向,文字的方向需要另外使用 par 配合 las 來修改:
par(las = 1, mar = c(3, 5, 1, 1))
barplot(gear.table, names.arg = c("Three", "Four", "Five"),
horiz = TRUE)
這裡的 las 設定為 1 則代表座標軸上名稱以水平方式顯示,而 mar 則是用來調整圖形的下方、左方、上方與右方的邊界大小,關於這些參數的詳細說明,請參考 par 的線上手冊。
二維的列連表也可以直接使用 barplot 畫出兩種資料合併的長條圖:
gear.table2 <- table(mtcars$vs, mtcars$gear)
gear.table2
3 4 5 0 12 2 4 1 3 10 1
barplot(gear.table2)
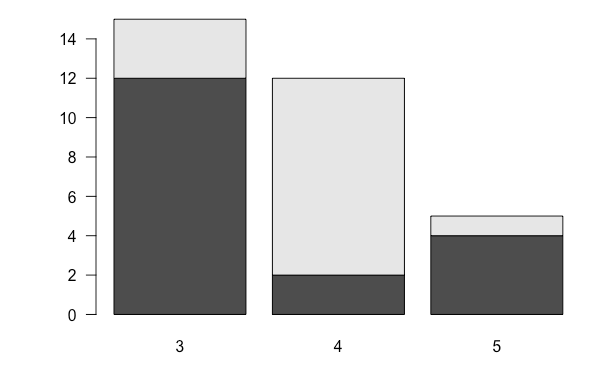
將兩種資料拆開來畫成兩個並列的長條圖:
barplot(gear.table2, beside = TRUE)
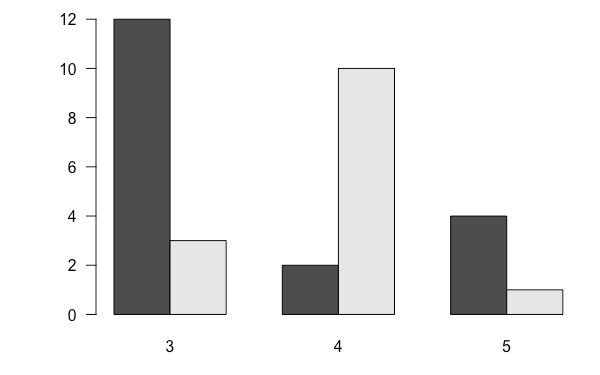
lattice 系統
在 lattice 系統中可以用 barchart 來繪製長條圖:
barchart(gear.table)
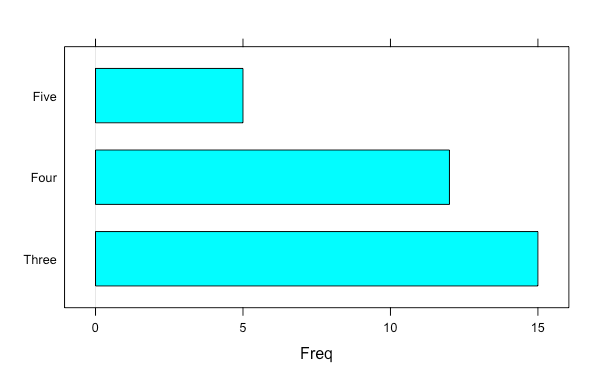
names(gear.table) <- c("Three", "Four", "Five")
barchart(gear.table)
以二維的列連表繪製長條圖:
barchart(gear.table2)
barchart 預設的資料方向跟 barplot 不同,我們可以使用 t 將資料轉向:
barchart(t(gear.table2))
將兩種資料拆開來畫成兩個並列的長條圖:
barchart(t(gear.table2), stack = FALSE)
ggplot2 系統
在 ggplot2 系統中可以使用 geom_bar 來繪製長條圖:
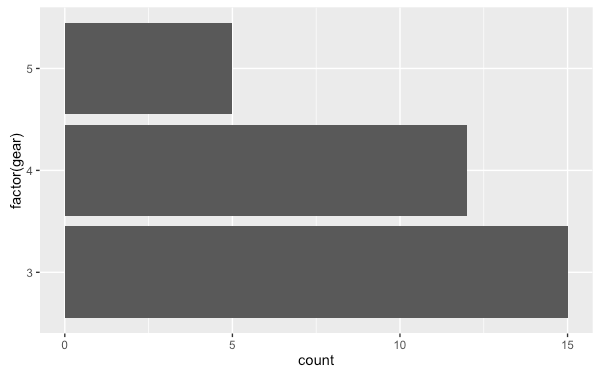
ggplot(mtcars, aes(factor(gear))) +
geom_bar()
繪製水平的長條圖:
ggplot(mtcars, aes(factor(gear))) +
geom_bar() +
coord_flip()
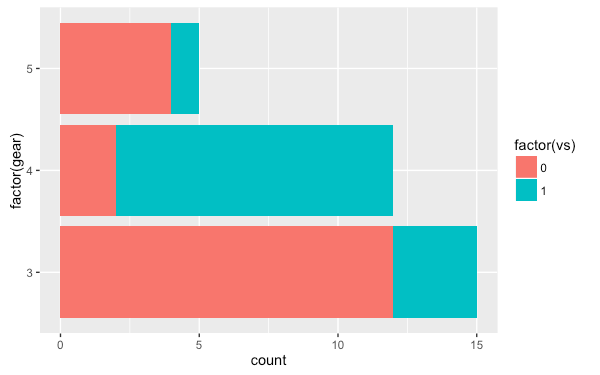
使用 aes 的 fill 參數可以讓不同的資料以不同的顏色表示:
ggplot(mtcars, aes(factor(gear), fill = factor(vs))) +
geom_bar() +
coord_flip()
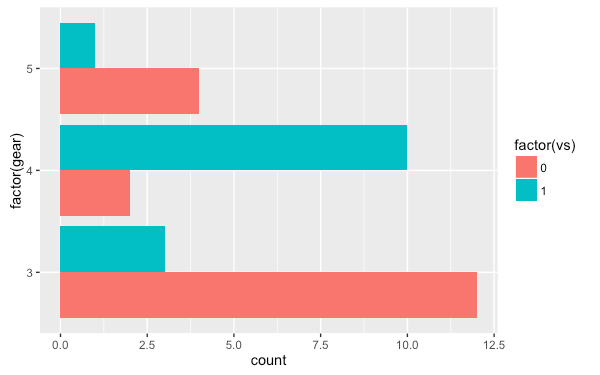
將 geom_bar 的 position 參數設定為 dodge 可以讓長條圖並列顯示:
ggplot(mtcars, aes(factor(gear), fill = factor(vs))) +
geom_bar(position="dodge") +
coord_flip()
圓餅圖(Pie Charts)
圓餅圖的功能類似長條圖,可以呈現各類別所佔的比例。
base 系統
base 系統中可用 pie 繪製圓餅圖,而通常預設的邊界會過大,可用 par 調整:
par(mar = c(1 ,1 ,1 ,1))
pie(gear.table)
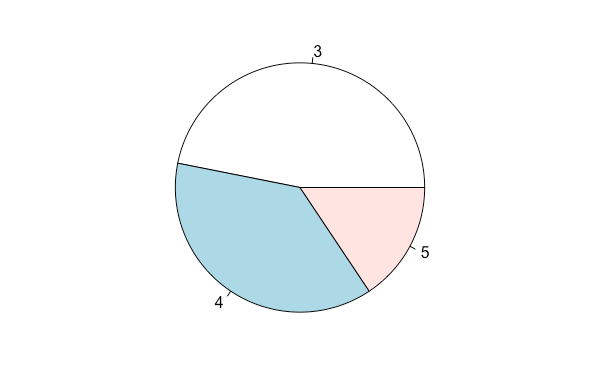
自訂每個類別的名稱:
pie(gear.table, labels = c("Three", "Four", "Five"))
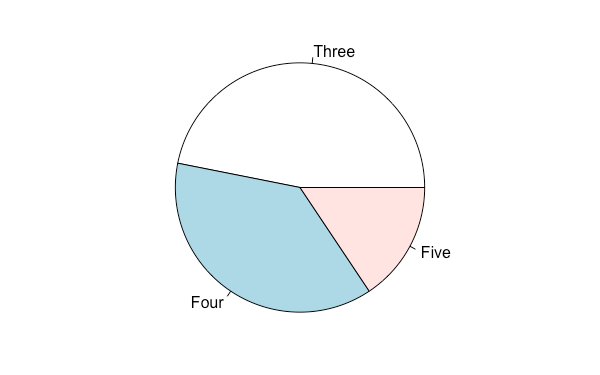
雖然圓餅圖是一個常用的圖形,不過
lattice系統上並沒有提供可以直接繪製圓餅圖的函數。
ggplot2 系統
若要在 ggplot2 系統繪製圓餅圖,可以使用堆疊的長條圖,並以 coord_polar 來轉換,首先產生一個長條圖:
pie <- ggplot(mtcars,
aes(x = factor(1), fill = factor(gear))) +
geom_bar(width = 1)
pie

使用 coord_polar 將圖型轉為極坐標:
pie <- pie + coord_polar(theta = "y")
pie
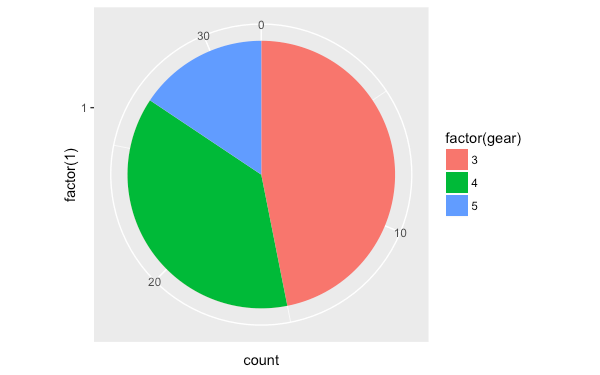
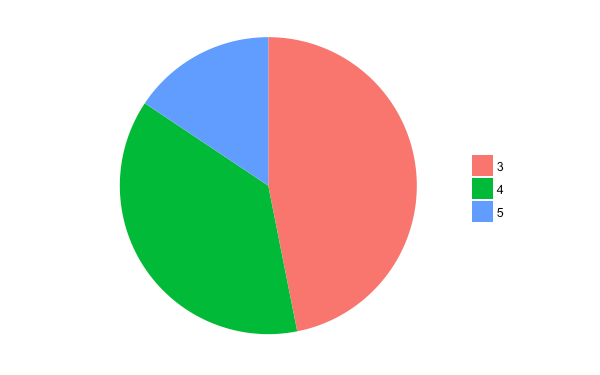
如果不想要顯示多餘的座標軸,可以加上 theme_void 把座標軸資訊都隱藏起來:
pie <- pie + theme_void()
pie
其他繪圖套件
除了以上介紹的三大繪圖系統之外,在 R 中還有很多各式各樣的繪圖套件,例如:
vcd:類別型資料的繪圖。plotrix:繪製特殊圖形。hexbin:繪製六角形的 binning 圖形。scatterplot3d:繪製各種 3D 圖形。misc3d:繪製各種 3D 圖形。rgl:使用 OpenGL 繪製 3D 圖形。rggobi:在 R 中使用 GGobi 顯示資料。igraph:繪製圖論與網路的相關圖形。
最新的繪圖套件整理可以參考 R 官方網站的 CRAN Task View。
Plotly for R 是一個開放原始碼的繪圖工具,可以讓使用者在瀏覽器中呈現互動式的圖形。