這裡介紹 ggplot 函數的基本圖層式繪圖使用方式。
ggplot 系統在繪圖時是以一種圖層式的概念在建立圖形的,每一張圖層上的資料可以有不同的來源、美學對應,而簡單版的 qplot 只允許單一資料來源以及一組美學對應,若要完全發揮 ggplot 系統的功能,就必須使用它的 ggplot 函數配合各式的圖層函數,這樣才能畫出更有彈性的圖形。
建立圖形物件
在使用 qplot 繪圖時,它其實自動幫使用者做了很多工作,從建立基本圖形物件、增加圖層到顯示繪圖結果等流程,以及選用各種的預設繪圖選項等,雖然這樣使用者非常方便就可以快速產生一張可用的圖形,不過同時也讓繪圖的彈性降低、可用的選項減少,無法繪製出比較複雜的圖形。
在 ggplot 系統上若要以標準的繪圖流程來畫圖,首先要使用 ggplot 這個函數來建立基本繪圖物件,其第一個 data 參數是指定資料來源的 data frame,而第二個 mapping 參數則是指定美學對應(aesthetic mapping),這兩個參數是設定繪圖的物件的預設值,若在這裡沒有設定的話,也可以在後續加入的圖層中再設定。
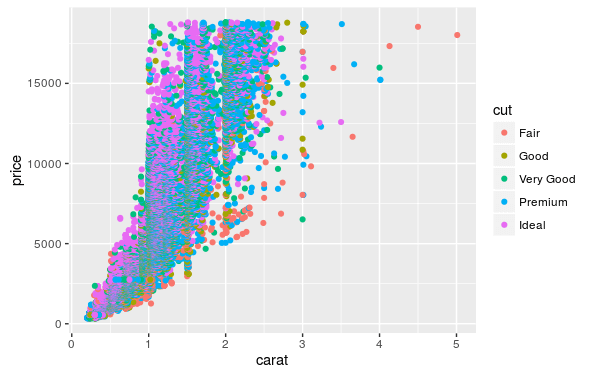
mapping 參數所指定的美學對應跟 qplot 中所使用的相同,只不過在這裡必須將對應的參數用 aes 函數包裝起來。下面這個範例是將 carat 變數對應到 x 軸、price 變數對應到 y 軸,而以顏色區隔 cut 變數。
my.plot <- ggplot(diamonds, aes(carat, price, colour = cut))
這裡建立的 my.plot 只是一個基本的繪圖物件,尚未包含任何圖層,所以還無法顯示任何圖形。
圖層
一個只包含 geom 參數的圖層是一個最簡單的圖層,其指定了繪製資料時所使用的幾何圖形。若在前面建立的繪圖物件上再加入一個 geom 指定為 point 的圖層,即可產生一張散佈圖:
my.plot <- my.plot + layer(
geom = "point",
stat = "identity",
position = "identity",
params = list(na.rm = FALSE)
)
這裡我們以加號(+)將圖層疊加至既有的繪圖物件上,被加入的新圖層會直接使用該繪圖物件上的資料來源以及美學對應參數。除了指定 geom 參數之外,另外還有兩個 stat 與 position 參數也要自行指定,這兩個參數可用來指定統計轉換與細部的幾何圖形位置調整,若不需要特別的轉換與調整的話,就指定為 "identity"。params 則是用來指定 geom 與 stat 所需要的參數。
若要顯示圖形則將此繪圖物件輸出即可:
my.plot
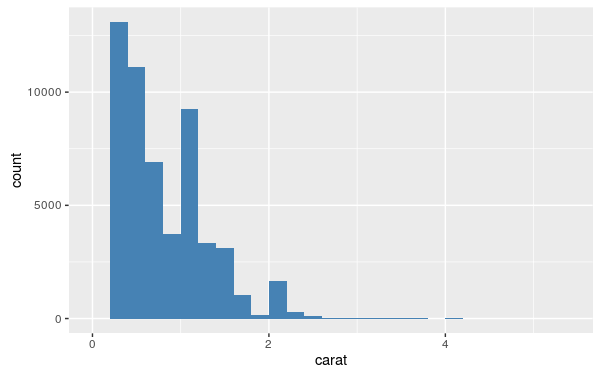
若要繪製直方圖的話,要指定的參數就會稍微複雜一些:
my.plot2 <- ggplot(diamonds, aes(x = carat))
my.plot2 <- my.plot2 + layer(
geom = "bar",
stat = "bin",
position = "identity",
params = list(
fill = "steelblue",
binwidth = 0.2,
na.rm = FALSE
)
)
my.plot2
在產生直方圖時,我們需要使用 bin 這個統計轉換來計算直方圖每個 bin 的數值,然後再使用 bar 這個 geom 呈現圖形,標準的圖層建立程序可以讓使用者有很大的彈性,但相對上需要的操作也相當繁瑣。
為了簡化繪圖的工作,ggplot 系統上提供了非常多建立圖層用的簡化圖層函數,在使用者取用 geom 的同時也自動加上預設的 stat 與 position,同樣的在取用 stat 時也會伴隨預設的 geom,使用者只需要很直覺地指定少量的參數即可。
ggplot 中的簡化圖層函數都是以 geom_* 與 stat_* 的方式命名的,通常從函數的名稱就可以看出其作用為何。改用簡化圖層函數之後,建立 ggplot 圖層的動作就會變得很簡單,以上面繪製直方圖的範例來說,若以 geom_histogram 這個繪製直方圖的簡化圖層函數改寫後,就會變成這樣:
my.plot3 <- ggplot(diamonds, aes(x = carat))
my.plot3 <- my.plot3 +
geom_histogram(binwidth = 0.2, fill = "steelblue")
my.plot3
產生的圖形相同,但是操作卻簡單很多。
大部分的 ggplot 的簡化圖層函數都有一些共通的參數:
mapping:指定美學對應,指定時需要以aes函數包裝,若沒有指定則會使用繪圖物件的預設值。data:指定資料來源的 data frame,通常都會省略,並直接使用繪圖物件的預設值。...:geom與stat所使用的參數,例如直方圖的 bin 寬度等。geom與stat:自行指定要使用的geom與stat,改變預設的設定。position:指定細部的資料位置調整。
以上這些參數都可以省略,不指定的話就會使用內部的預設值。
在 ggplot 函數與圖層函數的參數順序有些小差異,在 ggplot 中第一個參數是 data、第二個是 mapping,但是在圖層函數中剛好相反,這樣的設計是因為一般在使用 ggplot 繪圖時,通常都會在 ggplot 中指定資料,而加入圖層時只會指定美學對應的參數。
ggplot 的圖層可以直接加在 ggplot 或 qplot 所產生的繪圖物件上,事實上 qplot 只是將建立繪圖物件與加入圖層的動作包裝成一個函數而已,其效果跟 ggplot 函數是相同的。
以下是幾種 ggplot 與 qplot 的寫法比較。
# 做法一
ggplot(msleep, aes(sleep_rem / sleep_total, awake)) +
geom_point()
# 做法二
qplot(sleep_rem / sleep_total, awake, data = msleep)
加入平滑曲線的範例:
# 做法一
qplot(sleep_rem / sleep_total, awake, data = msleep) +
geom_smooth()
# 做法二
qplot(sleep_rem / sleep_total, awake, data = msleep,
geom = c("point", "smooth"))
# 做法三
ggplot(msleep, aes(sleep_rem / sleep_total, awake)) +
geom_point() + geom_smooth()
儲存在變數當中的 ggplot 繪圖物件可以使用 summary 查看其內容,透過這種方式可以在不需要把圖形畫出來的情況下檢查圖形的細節:
my.plot4 <- ggplot(msleep, aes(sleep_rem / sleep_total, awake))
summary(my.plot4)
data: name, genus, vore, order, conservation, sleep_total, sleep_rem, sleep_cycle, awake, brainwt, bodywt [83x11] mapping: x = sleep_rem/sleep_total, y = awake faceting: facet_null()
my.plot4 <- my.plot4 + geom_point()
summary(my.plot4)
data: name, genus, vore, order, conservation, sleep_total, sleep_rem, sleep_cycle, awake, brainwt, bodywt [83x11] mapping: x = sleep_rem/sleep_total, y = awake faceting: facet_null() ----------------------------------- geom_point: na.rm = FALSE stat_identity: na.rm = FALSE position_identity
ggplot 的圖層本身就是一種 R 的物件,也可以儲存在變數當中,減少重複的程式碼,例如我們可以用不同的資料來源來建立多個繪圖物件,然後套用相同的圖層,若後來要更換圖層時,也僅需要更改一個地方。以下的範例中我們建立了一個圖層,套用在不同的繪圖物件上。
bestfit <- geom_smooth(method = "lm", se = F,
color = alpha("steelblue", 0.5), size = 2)
qplot(sleep_rem, sleep_total, data = msleep) + bestfit
qplot(awake, brainwt, data = msleep, log = "y") + bestfit
qplot(bodywt, brainwt, data = msleep, log = "xy") + bestfit
資料來源
ggplot 的資料來源一定要是 data frame,它不像 R 的其他繪圖系統一樣同時可以接受一般的向量,而這樣嚴格的設計也是有它的優點,除了讓程式碼的語法統一之外,也可以方便置換資料,直接以既有的圖層組合產生新的圖形。
若要改變一個 ggplot 繪圖物件的資料來源,可以使用 %+% 運算子:
my.plot5 <- ggplot(mtcars, aes(mpg, wt, colour = cyl)) + geom_point()
my.plot5
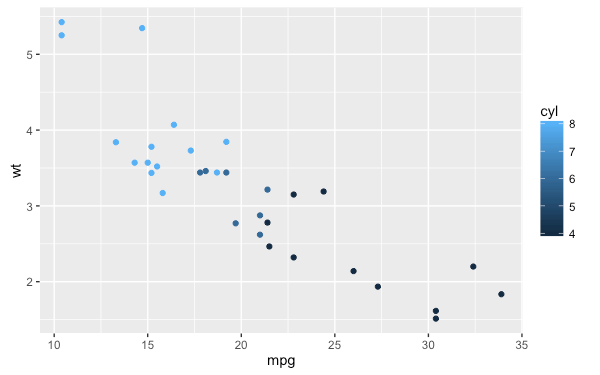
使用 %+% 運算子抽換資料來源的 data frame:
mtcars.trans <- transform(mtcars, mpg = mpg ^ 2)
my.plot5 %+% mtcars.trans
ggplot 在指定資料來源之後,會將資料複製一份並儲存在繪圖物件當中,後續若資料更動時,ggplot 的繪圖並不會受影響,另外由於這樣的特性,我們可以將 ggplot 繪圖物件儲存至硬碟中,之後重新載入與繪圖時也不需要載入其餘任何資料。
美學對應
美學對應中敘述了資料中的各個變數如何與圖形上的各種屬性對應,指定美學對應的各種參數時要使用 aes 函數包裝起來,例如:
aes(x = weight, y = height, color = age)
這個設定會將 x 軸指定為 weight 變數、y 軸指定為 height 變數,而顏色(color)則是指定為 age 變數。這些變數都會從資料來源的 data frame 中取得,不需要以錢字號的方式指定,這種設計可以讓使用者將所需要使用的變數都包裝在一個 data frame 中,方便統一管理。
在指定對應關係時,也可以運用各種數學函數:
aes(weight, height, colour = sqrt(age))
在 aes 中只能使用繪圖物件或圖層資料來源 data frame 中的變數,不可以指定為其他全域的變數,這個限制是要確保每一個 ggplot 物件本身都可以獨立運作,在經過儲存與重新載入之後也不會有問題。
繪圖與圖層
預設的美學對應可以在繪圖物件建立時就指定,這是比較常見的使用方式:
my.plot6 <- ggplot(mtcars, aes(x = mpg, y = wt))
my.plot6 <- my.plot6 + geom_point()
summary(my.plot6)
data: mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb [32x11] mapping: x = mpg, y = wt faceting: facet_null() ----------------------------------- geom_point: na.rm = FALSE stat_identity: na.rm = FALSE position_identity
除此之外,也可以在繪圖物件建立之後,再加上 aes 來指定:
my.plot7 <- ggplot(mtcars)
my.plot7 <- my.plot7 + aes(x = mpg, y = wt)
my.plot7 <- my.plot7 + geom_point()
summary(my.plot7)
data: mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb [32x11] mapping: x = mpg, y = wt faceting: facet_null() ----------------------------------- geom_point: na.rm = FALSE stat_identity: na.rm = FALSE position_identity
在繪圖物件中的美學對應設定可以在圖層中增加、修改或刪除,例如:
my.plot7 + geom_point(aes(colour = factor(cyl)))
my.plot7 + geom_point(aes(y = disp))
如果要刪除某一個美學對應參數,就把該參數設定為 NULL 即可,例如:
aes(y = NULL)
在圖層中更改美學對應的設定,其效果只會影響該圖層本身,對全域的設定沒有影響。
設定與對應
除了將美學對應以 aes 函數指定為資料的變數之外,也可以使用一般參數的方式指定為一個固定的值,例如將資料點的顏色指定為藍色:
my.plot8 <- ggplot(mtcars, aes(mpg, wt))
my.plot8 + geom_point(colour = "blue")
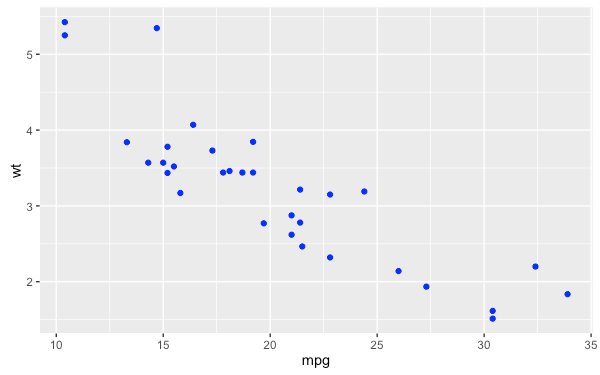
這裡在指定資料點的顏色時,並沒有加上 aes 函數,這種指定方式就是單純將資料點的顏色「設定」為藍色,這個做法跟加上 aes 函數的狀況完全不同。
my.plot8 + geom_point(aes(colour = "blue"))
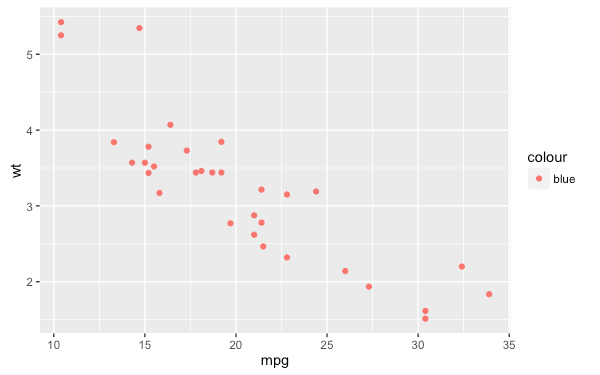
加上 aes 函數之後是代表一種「對應」關係,這樣會在內部產生一個值為 "blue" 的變數,然後將顏色屬性對應到該變數,由於這個變數是只有一個值的類別型變數,所以在上色時會從預設的色盤上取出第一種顏色來為資料點上色,而預設的第一種顏色就是這裡看到的粉紅色。
如果在 qplot 函數中要設定這種固定的參數時,要額外使用 I 函數將參數值包起來,也就是 color = I("blue")。
群組(Grouping)
在 ggplot 系統中的幾何圖形(geom)大致可分為個體型與集合型兩大類,個體型的幾何圖形在表現資料時,data frame 中的每一筆資料(亦即每一列)都會以一個幾何圖形呈現,例如 point 會以一個資料點表示一筆資料,而集合型的幾何圖形則會以一個幾何圖形表現多筆資料,通常這些資料都會先經過一些統計轉換,例如直方圖等。至於 line 與 path 則是介於兩者之間的幾何圖形,整條線雖然代表一組資料,但其中每一條線段都代表兩筆資料。
在 ggplot 系統上資料與幾何圖形之間的對應是由群組(group)這個美學對應所負責的,在預設的設定之下,ggplot 會以圖形上所有的類別型資料為基準來區分資料,大部分的狀況下這樣的設定都可以畫出使用者想要的結果,但若這樣的設定不符合使用者的需求,或是圖形上沒有類別型的資料時,就會需要自行指定群組的設定,也就是要自行指定一個可以用來區分組別的變數。
interaction 函數可以協助使用者將多個變數組合成一個,方便建立分組用的變數。
基本群組
這裡我們以 nlme 套件中的 Oxboys 資料集來做示範,在這個資料集中包含了許多個體的時間序列資料,如果只是單純將時間序列畫出來,圖形會有問題:
my.plot9 <- ggplot(Oxboys, aes(age, height)) +
geom_line()
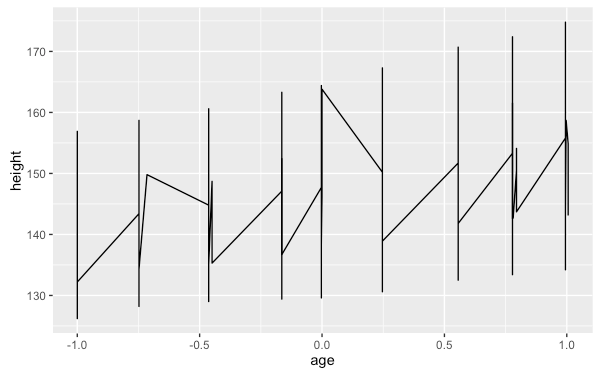
上面的圖形是將所有個體的資料都混合在一起繪製,但我們通常會希望依據個體區分,畫出多條時間序列的線條,這時候就可以加上 group 參數,並將其指定為個體的變數:
my.plot9 <- ggplot(Oxboys, aes(age, height, group = Subject)) +
geom_line()
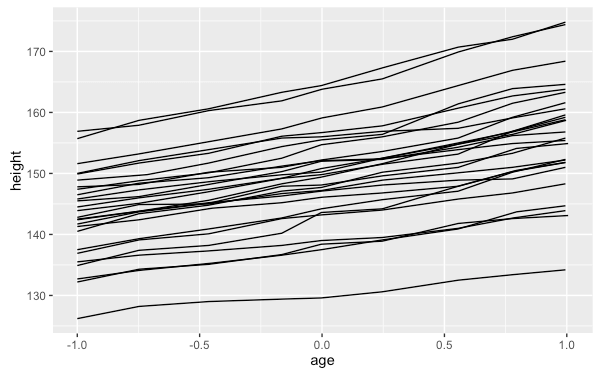
圖層與群組
有時候我們會希望在圖形上加上一些標示總體趨勢的幾何圖形,讓整個圖形除了有每個個體的細部資訊之外,也可以同時呈現整體的資料分佈走向。在上面這個例子中若要加上一條線性迴歸線,可以使用 geom_smooth 配合 method = "lm" 參數,不過若只是這樣加上去,結果可能不如預期:
my.plot9 + geom_smooth(method="lm", se = F)
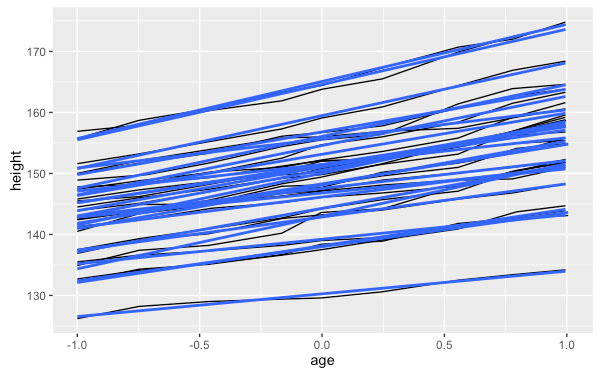
由於我們在繪圖物件中已經設定了 group 參數,所以再加上迴歸線的圖層時,也會套用該 group 的設定,也就是說它會對每一個個體畫出各自的迴歸線,但我們想要的是使用全部的資料畫出一條迴歸線,這時候就可以將 group 設定為一個固定的值,也就是取消群組的功能:
my.plot9 + geom_smooth(aes(group = 1), method="lm", size = 2, se = F)
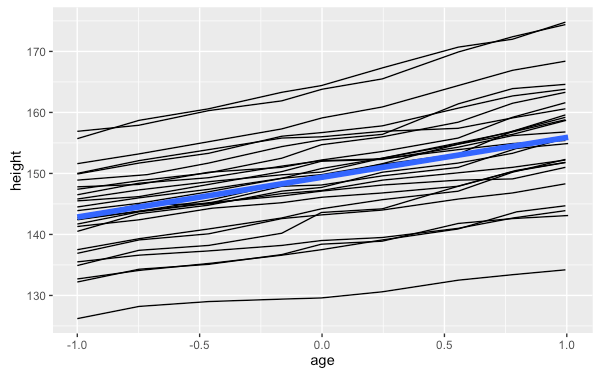
在加入圖層時透過指定新的群組設定,就可以做出很多的變化。
下面這個圖是將 height 依據 Occasion 畫出的箱形圖:
boysbox <- ggplot(Oxboys, aes(Occasion, height)) + geom_boxplot()
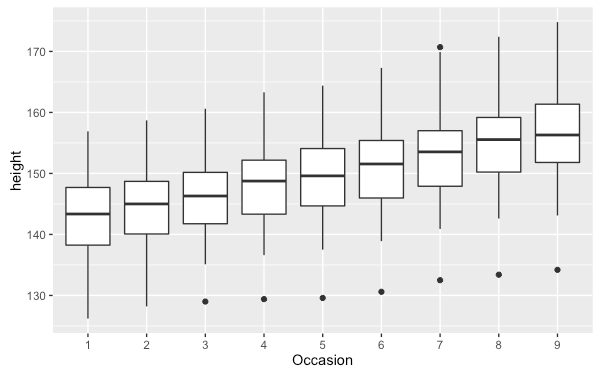
由於在繪製箱形圖時是使用 Occasion 這個離散型的變數,所以預設的狀況下就會以這個變數分組,所以不需要特別指定 group 參數。接著如果要將每個個體的資料標示出來,就會需要自行指定分組的方式:
boysbox + geom_line(aes(group = Subject), color = "blue")
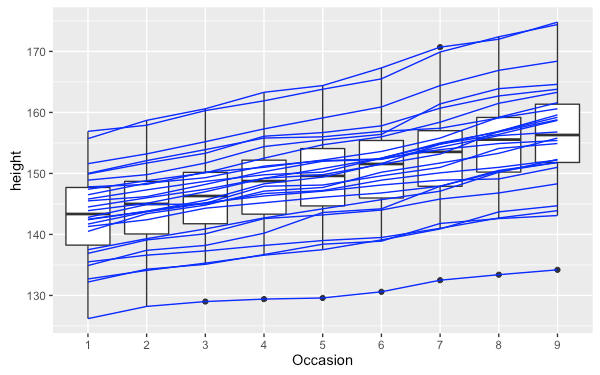
在這裡我們使用 geom_line 配合 group 參數,讓它依據 Subject 區分資料,畫出每個個體的資料,並且另外加上 color 參數設定線條顏色。
美學對應與幾何圖形
個體型的幾何圖形在美學對應上很單純,個別資料的美學對應性質都是以一對一的方式對應到幾何圖形上,但是對於集合型的幾何圖形而言,就會是一個問題。
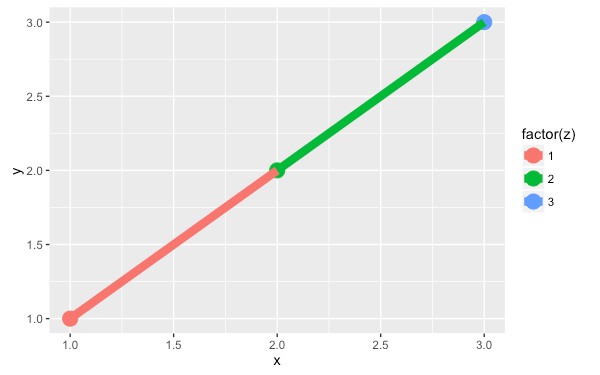
如果是在繪製 line 或是 path 的線段時,第一條線段會使用第一個點的顏色,而第二條線段會使用第二個點的顏色,以次類推,也就是說最後一個點的顏色並不會被使用到。
my.df <- data.frame(x = 1:3, y = 1:3, z = 1:3)
qplot(x, y, data = my.df, color = factor(z), size = I(5)) +
geom_line(size = 3, group = 1)
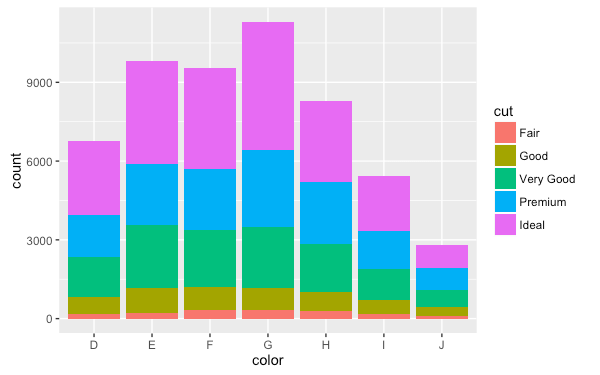
至於其他類型的集合型幾何圖形,只有在每一筆資料的屬性都相同時才會被使用,否則就會直接使用預設值,這個問題通常只會發生在連續型的變數上,因為如果是類別型的變數在使用時,ggplot 會自動將資料依據變數分組,所以每一組內部的變數值都會是一樣的,這個狀況在繪製直方圖時很常見。
qplot(color, data = diamonds, geom = "bar",
fill = cut)
幾何圖形(Geom)
幾何圖形是一個圖形中最主要的繪圖部分,它可以控制圖形的類型,例如 point 可以產生散佈圖、line 可以產生折線圖,下表是各種在 ggplot 系統中可用的幾何圖形。
| 幾何圖形 | 說明 |
|---|---|
abline | 以斜率與截距來指定的直線。 |
bar | 長條圖。 |
bin2d | heatmap。 |
blank | 空圖層。 |
boxplot | 箱形圖。 |
contour | 等高線圖。 |
count | 計算每個位置的數目。 |
crossbar | lines, crossbars and errorbars。 |
density | 密度函數圖。 |
density_2d | 二維密度函數圖。。 |
dotplot | dot plot。 |
errorbarh | Horizontal error bars。 |
freqpoly | 直方圖。 |
hex | Hexagon binning。 |
jitter | jitter 資料點。 |
label | 文字標示。 |
map | 地圖。 |
path | 路徑。 |
point | 資料點。 |
polygon | 多邊形。 |
quantile | Add quantile lines from a quantile regression。 |
raster | 方形區域。 |
ribbon | 區間。 |
rug | rug plot。 |
segment | 線段與曲線。 |
smooth | 平滑曲線。 |
violin | 小提琴圖。 |
最新的幾何圖形列表請參考 ggplot 的官方網站。
不同的幾何圖形可接受的美學對應參數都不同,而每一種幾何圖形都有預設的統計轉換,這些詳細的參數說明可以參考 ggplot 的官方網站。
統計轉換(Stat)
統計轉換是指將原始的資料經過某些計算,轉換為比較精簡、容易呈現的資料,例如平滑曲線就是一種很有用的統計轉換,它可以依據資料的分佈算出一條平滑曲線,呈現資料大致上的走向,最新的各種統計轉換可以從 ggplot 的官方網站查詢。
統計轉換會使用資料來源的 data frame 作為輸入,而計算完之後會輸出新的 data frame,所以我們甚至可以在美學對應上使用統計轉換中所產生的變數。例如 stat_bin 這個用於建立直方圖的統計轉換就會產生以下幾個變數:
count:每個 bin 的資料點數。density:每個 bin 的資料點數比例。ncount:將count標準化,最大值為1。ndensity:將density標準化,最大值為1。
這些由統計轉換所產生的變數,在某些圖形上可以用來替代原始的資料,例如直方圖預設會以資料的數量作為高度,如果想要改以密度為單位,就可以使用 density 這個變數:
ggplot(diamonds, aes(carat)) +
geom_histogram(aes(y = ..density..), binwidth = 0.1)
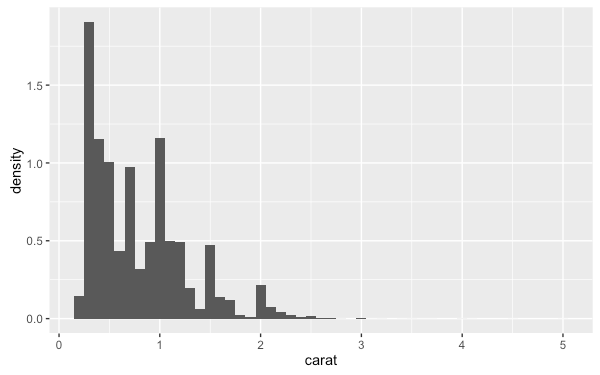
要取用統計轉換所產生的變數時,必須前後加上 ..(例如 ..density..),這是為了與原始資料的變數有所區隔,也可以讓程式碼在閱讀上更清晰。在 qplot 函數中也可以使用這樣的方式取用統計轉換所產生的變數:
qplot(carat, ..density.., data = diamonds,
geom="histogram", binwidth = 0.1)
位置調整(Position)
位置調整的功能主要是用於調整圖層中幾何圖形的比較細微的位置選項,處理繪圖時資料重疊的問題,通常用於類別型的資料。下表是 ggplot 系統中可用的位置調整選項。
| 位置調整選項 | 說明 |
|---|---|
dodge | 並列顯示。 |
fill | 標準化堆疊顯示。 |
identity | 不調整位置。 |
jitter | 使用 jitter 方式避免資料點重疊。 |
stack | 堆疊顯示。 |
要理解這些選項的差異,從直方圖上來看會比較明顯。
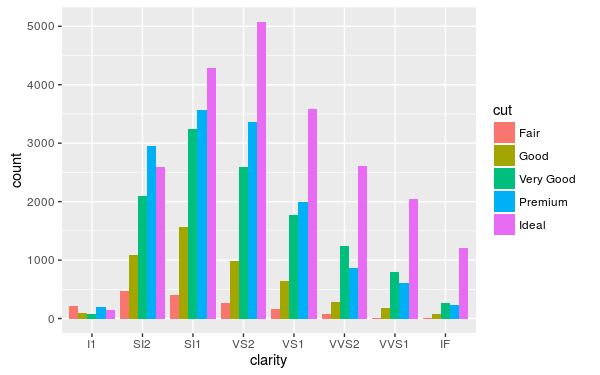
ggplot(diamonds, aes(clarity, fill=cut)) + geom_bar(position="dodge")
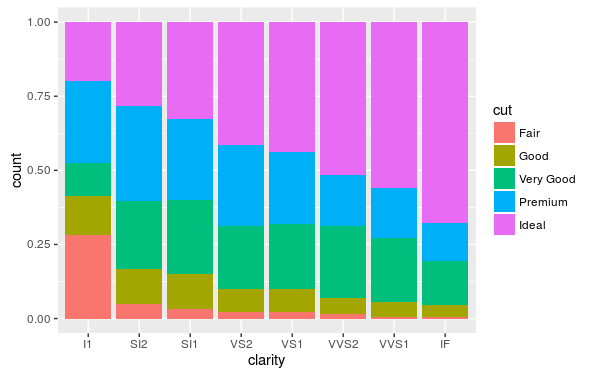
ggplot(diamonds, aes(clarity, fill=cut)) + geom_bar(position="fill")
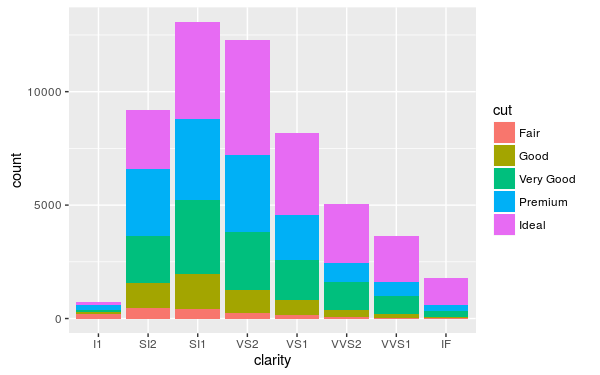
ggplot(diamonds, aes(clarity, fill=cut)) + geom_bar(position="stack")
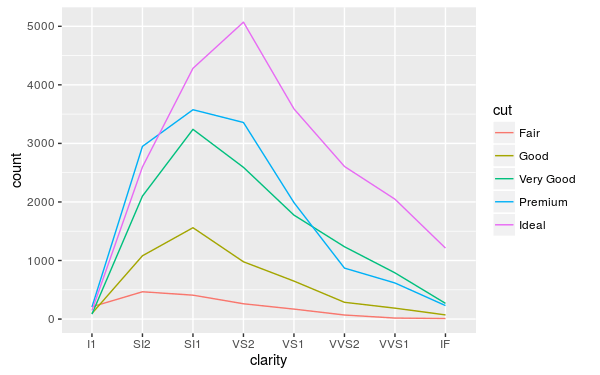
identity 適合用在一般的折線圖:
ggplot(diamonds, aes(clarity, group = cut)) +
geom_line(aes(color = cut), position="identity", stat = "count")
jitter 通常適用於以資料點繪製類別型資料的情況:
set.seed(5)
diamonds.subset <- diamonds[sample(nrow(diamonds), 500), ]
ggplot(diamonds.subset, aes(clarity, cut)) +
geom_point(aes(color = color), position="jitter")
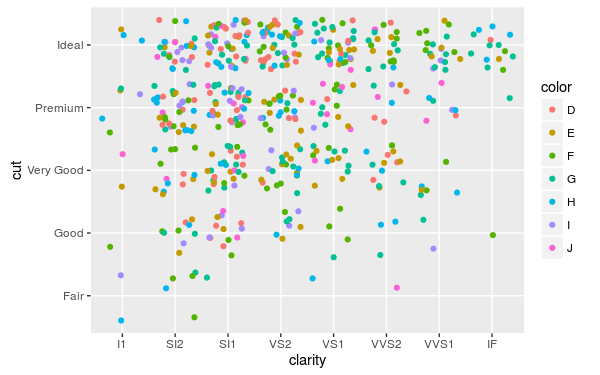
幾何圖形與統計轉換
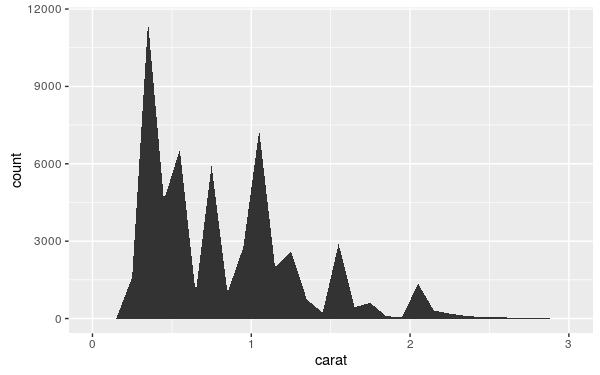
結合 ggplot 的幾何圖形與統計轉換可以讓使用者產生各種新穎的圖形,以下幾張圖是以 count 這個統計轉換後,配合不同的幾何圖形所得到的結果。
my.plot <- ggplot(diamonds, aes(carat)) + xlim(0, 3)
my.plot + stat_bin(aes(ymax = ..count..), binwidth = 0.1, geom = "area")
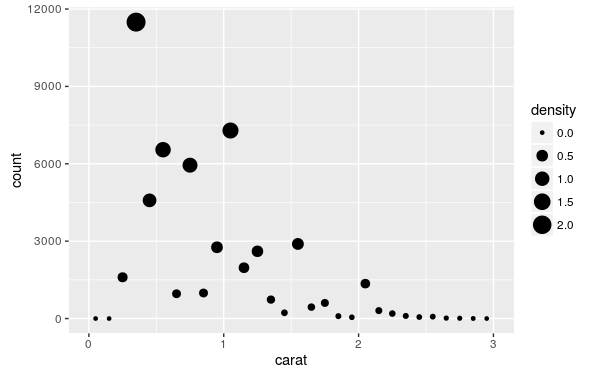
my.plot + stat_bin(
aes(size = ..density..), binwidth = 0.1,
geom = "point", position="identity"
)
轉換完的資料
如果您有一些已經經過統計轉換的資料,只是想要單純將資料畫出來,可以使用 stat_identity 這個統計轉換,它會依據原始資料的類型直接選擇適合幾何圖形來呈現。
不同的資料來源
ggplot 有一個比較特別的功能就是可以讓不同的圖層有不同的資料來源,可以將相關的幾個資料集畫在一起,例如在使用模型預測資料時,繪製預測值。
library(nlme)
model <- lme(height ~ age, data = Oxboys, random = ~ 1 + age | Subject)
age_grid <- seq(-1, 1, length = 10)
subjects <- unique(Oxboys$Subject)
preds <- expand.grid(age = age_grid, Subject = subjects)
preds$height <- predict(model, preds)
畫出模型的預測值:
my.plot <- ggplot(Oxboys, aes(age, height, group = Subject)) + geom_line()
my.plot + geom_line(data = preds, colour = "#3366FF", size= 0.4)
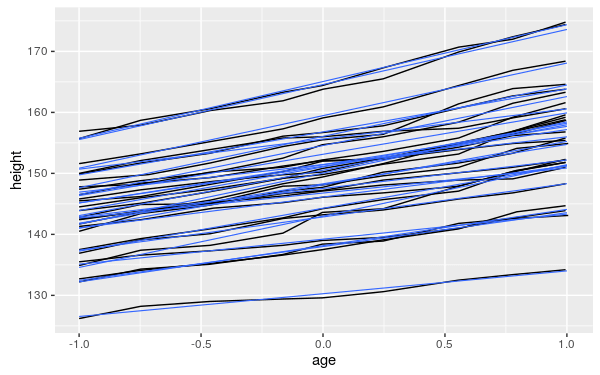
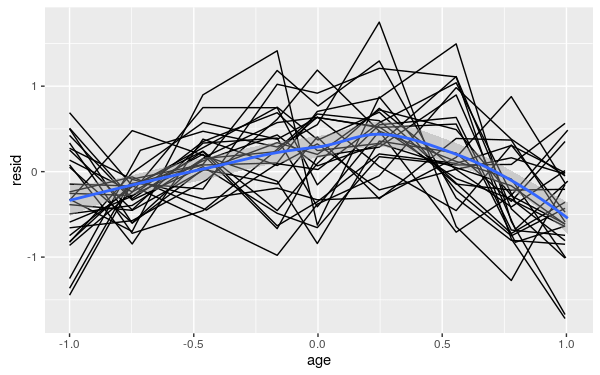
畫出模型的殘差值,並加入平滑曲線:
Oxboys$fitted <- predict(model)
Oxboys$resid <- with(Oxboys, fitted - height)
my.plot %+% Oxboys + aes(y = resid) + geom_smooth(aes(group=1))