這裡解釋為什麼 Node.js 架構在同時性資料處理應用程式上的效能會比傳統 Java 架構好的原因所在。
在討論 Node.js 與 Java 架構的差異之前,我們要先了解資料處理應用程式是什麼。
資料處理應用程式(data processing application)就是指那些專門用來處理大量資料的應用程式,並且涉及到大量的 I/O 動作。
在資料處理應用程式中的每個處理行程(process)都會透過網路 I/O 存取資料庫,在存取資料庫時也會確認資料庫的回應訊息,檢查是否成功或是進行下一步的處理動作等。
因此整個資料處理應用程式在執行時,會包含大量的處理行程,每個行程都會同時呼叫 API 透過網路 I/O 存取資料庫。
Node.js 與 Java 之間最主要的差異就在於 concurrency 與 I/O 架構,Java 所使用的是 multithreaded synchronous I/O,而 Node.js 則是使用 single threaded asynchronous I/O。
| Java EE | Node.js | |
| Concurrency Model | Multi-threaded | Single-threaded |
| I/O Model | Synchronous I/O | Asynchronous I/O |
接下來我們會解釋這樣的差異對於同時性資料處理應用程式會有什麼影響。
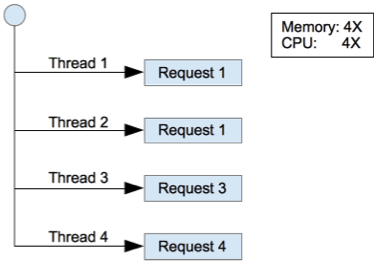
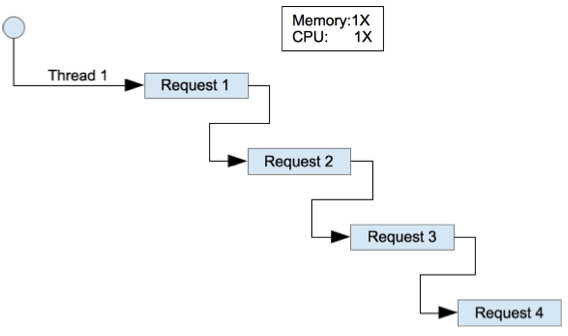
下面這兩張圖描述了 Java 與 Node.js 在同時處理多個請求(request)時的差異。
Java 所使用的 multi-threaded concurrency 架構可以同時處理多個請求,而 Node.js 所使用的 single threaded concurrency 則是一次處理一個請求。
很顯然的 Java 使用多個執行序來同時處理多個請求,所以它在處理請求的速度上會比 Node.js 快,尤其是在計算量較高的情況下更是明顯。另外由於 Java 要同時產生多個執行序,所以其所使用的系統資源也會比 Node.js 多。
然而在同時性資料處理應用程式上,包含大量的網路與資料庫的 I/O 動作,這類的動作通常都會伴隨著很長的等待時間(因為網路或外部程式的反應比較慢),這段等待時間裡面就會浪費那些已經配置給該行程的 CPU 或記憶體資源。
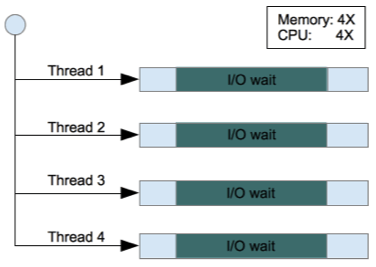
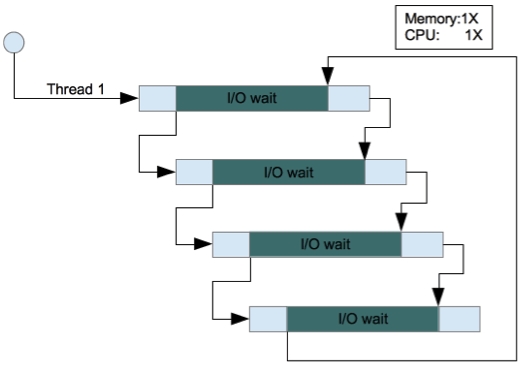
從上面的 Concurrency Model 比較中,Node.js 看不出有明顯的優勢,但是在處理包含 I/O 動作的請求時,就不一樣了,下面這兩張圖是有包含 I/O 動作的狀況。
從這兩張圖就可以很清楚看出來 Node.js 在處理四個含有 I/O 動作的請求時雖然整體所耗費的時間稍微長一些,但是它花費在等待 I/O 的時間卻大幅減少很多(甚至沒有任何等待時間),最重要的是在系統資源的使用上,比起 Java 架構來說,Node.js 所需要的系統資源非常的低(因為它只使用單一執行序),也因為這樣的特性,Node.js 非常擅長處理大量且同時性的資料處理請求。
雖然 Node.js 只使用一顆 CPU 就可以運作的很好,但是現在的伺服器硬體都是多 CPU 的架構,如何讓 Node.js 善用多顆 CPU 以發揮伺服器完整的效能也是很重要的。
Node Cluster 這個模組可以在一台伺服器上建立多個 worker,透過 IPC 與 父行程溝通,將工作分散至不同的 CPU 中處理。
Node Cluster 是針對一台伺服器的狀況,將工作分散給不同的 CPU,如果想要將工作分散給多台伺服器的話,可以在每一台伺服器中安裝 Node.js,然後使用 zeroMQ 或 Socket.IO 這類的網路 IPC 方式來串接,這樣的方式彈性會比較大,日後要再進行伺服器的擴充也會很方便。
{kind=link}
{kind=link}
{kind=link}
{kind=link}