這裡介紹大資料(big data)如何應用在教育上,幫助老師的教學與學生的學習。
在許多的線上服務網站(如 Amazon 或 Netflix)都會針對不同的使用者特性,提供客制化的服務,而現在網路上也有很多線上學習網站,隨著這些網站與使用者數量的增加,就會產生很多的資料,藉著這些資料就可以分析出學習者的學習狀況,以及該如何針對每個學習者提供個別的客制化教材,並改善學習的成效。

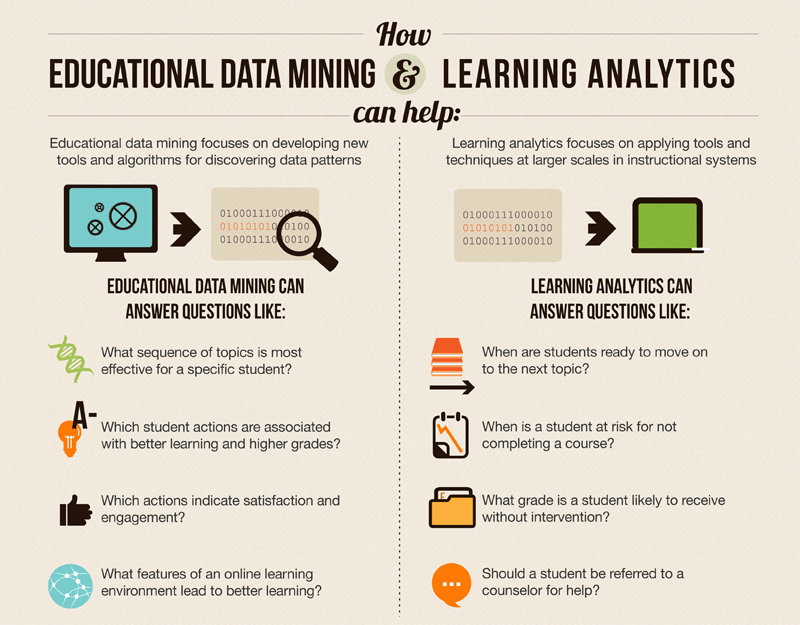
基本上我們可以利用資料採礦(data mining)的方法,從我們搜集的資料中找出我們有興趣的資訊,例如針對特定的學生,各個學習主題的先後順序應該如何安排?學生的哪些反應跟學習成效有關?或是有沒有哪些線上學習網站的特徵可以對學習者有所幫助等等。
找出資料內的一些資訊之後,在經過一些分析(analytics),我們就可以推論出一些有用的結果,例如判斷某個學生該在何時進入下一個學習主題?某個學生在不進行進一步輔導的情況下,他最後的成績如何?或是某個學生是否需要個別的輔導或幫助等。
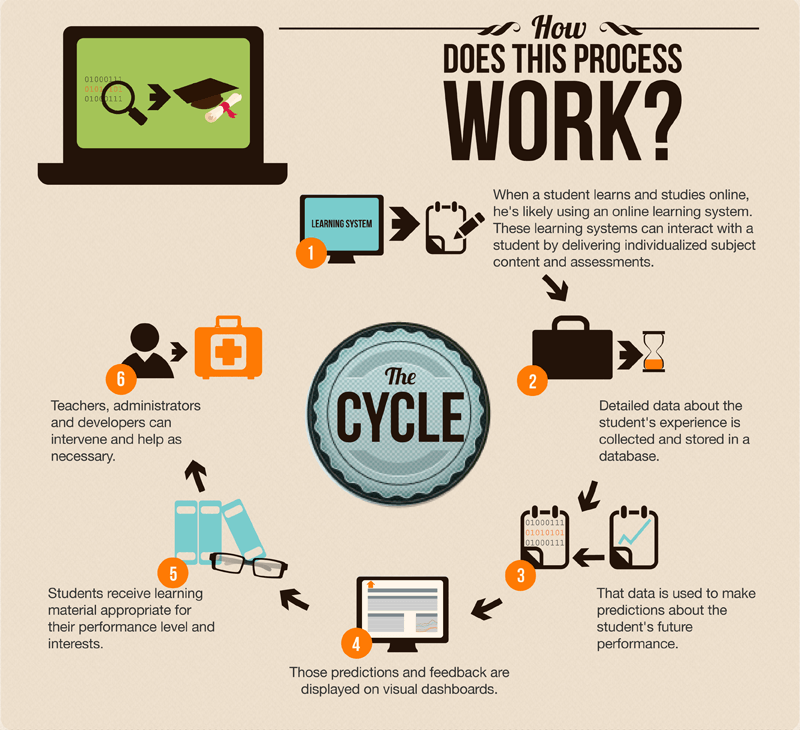
而這整個學習系統大概可以分為六大步驟,而這六個步驟則構成一個循環:
- 學生進入學習系統,獲得客制化的教材,並透過線上的互動,蒐集資料。
- 將搜集到的詳細資料(包含各種使用者經驗等)存入資料庫。
- 使用搜集到的使用者資料預測該學生未來的表現。
- 整理出預測報表,並整合一些使用者回饋。
- 針對該學生的程度與興趣,提供適合的教材。
- 老師或管理員在需要的時候進行個別輔導。
使用這些新的技術當然也會伴隨著一些成本與困難,例如要儲存大量資料就需要一筆經費維持硬體設備與技術人員,不同的系統間的整和不是一件容易的事,要從大資料中分析出簡要的資訊也很困難,有時候連要拿哪些資料來分析都是很難決定的事情,另外隱私與道德問題也是需要妥善處理的。

最後這張圖給了一些建議,到底該怎麼做,首先要先有一套這樣的想法,然後找資訊背景的人處理大資料的儲存與使用問題,然後在購買學習軟體之前,要先了解這些軟體,最後找一個特定的領域,開始施行,最後看看學生的反應如何。
這裡看起來規劃的很理想,但是其實這裡面有很多很難處理的問題,牽涉到各種軟體、硬體、統計分析、甚至是行為科學等等,真的要做恐怕沒有想像中容易,應該無法在短時間內就做出來,不過對於這些相關領域的研究者而言,倒是個好消息,因為這裡面就會產生許多可以進一步研究的主題。
參考資料:Big Data Startups