
Presto 是 Facebook 所使用的互動式資料查詢系統,支援 petabyte 等級的資料量,目前以開放原始碼的方式釋出。
Facebook 是一家資料導向的公司,資料的處理與分析是建立這家公司與其超過十億個使用者的核心技術,而其擁有的資料量高達 300 PB(petabyte),這些資料可用於各種的應用領域,其所使用的處理方式從傳統的批次處理、graph analytics、機器學習(machine learning)到即時的互動式分析都有。
Facebook 的資料科學家與工程師常常都要分析這些資料,研究如何改看他們的產品,對於他們而言,如何在這麼大量的資料中快速撈出他們想要的資料會是一個大問題,因為 Facebook 的資料量實在太大了,若以一般的資料庫來處理,根本無法負荷。
一開始 Facebook 的資料中心是使用幾台大型的 Hadoop/HDFS 的叢集電腦來處理這些資料,Hadoop 的 MapReduce 與 Hive 都是特別為大量資料處理而設計的,但是當資料量成長到 petabyte 等級的時候,又加上更多的新的使用需求,這樣的系統漸漸不敷使用,Facebook 需要一個互動式的資料系統,而且查詢的反應速度更要夠快才行。
在 2012 年秋天,Facebook 成立了 Data Infrastructure 這個團隊,其目的在於解決這些資料處理上的問題,他們審視過市面上各種的解決方案,不是過於新穎就是不太符合它們現形的需求,所以他們決定自行發展一個快速互動式的資料查詢系統,並命名為 Presto。
這裡我們將簡單介紹 Presto 的基本架構,並說明它目前發展的狀況以及未來的規劃方向。
架構(Architecture)
Presto 是一個專門為互動式的即時分析操作所設計的 SQL 查詢引擎,它支援標準的 ANSI SQL 指令,包含複雜的 query、aggregations、joins 與 window 函數。
下面這張圖是 Presto 簡略的系統架構,client 傳送 SQL 指令給 Presto 的 coordinator,而 coordinator 負責解析(parse)、分析(analyze)與規劃查詢動作的執行,執行管線(pipeline)中的 scheduler 負責將查詢的工作分派給最接近資料的節點,並監控執行的情況。隨後 client 會從階層式架構的 worker 中取得資料。
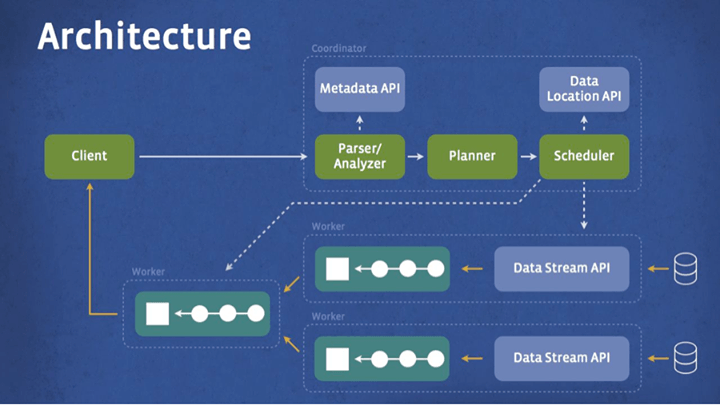
Presto 的執行模式跟 Hive 與 MapReduce 的不同,Hive 是將查詢轉換為多個層次的 MapRecuce tasks,然後一個接著一個執行,每個 task 從硬碟讀取資料然後又馬上將輸出寫回硬碟,而 Presto 則沒有使用 MapReduce,它是使用自己設計的 SQL 查詢引擎,除了改善排程機制,所有的處理流程都是在記憶體中進行,並且透過管線(pipeline)與網路串接不同的處理步驟,這種方式可以避免不必要的 I/O 與延遲(latency),而藉由管線串接的執行流程可以讓所有的步驟一起執行,透過資料流的方式,讓資料處理起來就像工廠的生產線一樣順暢,減少等待資料的時間。
Presto 系統是使用 Java 來實作的,原因在於使用 Java 語言來開發軟體的速度很快,而且也很容易跟 Facebook 中其他以 Java 開發的元件結合。Presto 會將查詢動作的某一部份動態編譯為位元碼(byte code),這樣可以讓 JVM 做一些最佳化的動作。另外透過精心設計的記憶體與資料的儲存結構,Presto 可以避免一般 Java 程式會碰到的記憶體配置與回收問題。(隨後我們會介紹一些以 Java 撰寫高效能程式的技巧,以及一些 Presto 值得我們學習的地方)
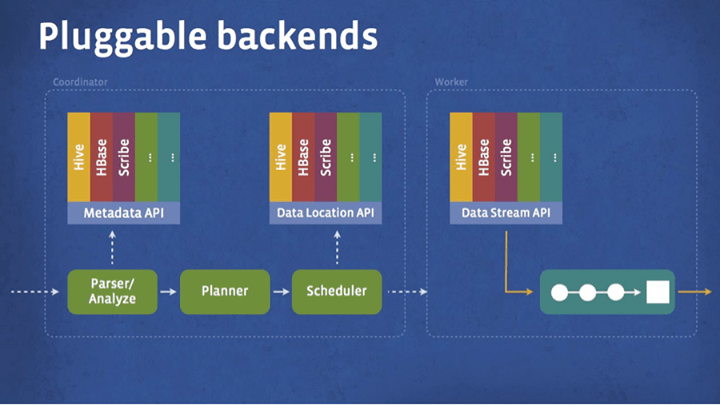
可擴充性是 Presto 另一個重點,在這個專案發展初期他們考慮到未來的資料可能除了 HDFS 之外,也可能會被儲存在其他各式各樣的系統中,例如 HBase 或是 Facebook News Feed 等,所以在設計上 Presto 也針對了這樣的需求,將儲存系統抽象化與模組化,使用儲存插件(storage plugin)的方式來處理,這些插件在 Presto 架構中稱為 connector,每種儲存系統會實作對應的 connector,提供基本的操作介面,包含取得資料的資訊(metadata)、位置與資料的內容,而 Presto 也提供了許多常見儲存系統的 connectors,例如 Hive/HDFS、HBase、Scribe等,讓使用者可以直接使用。
目前發展狀況
上面有提到 Presto 專案是在 2012 年秋季才開始建立的,而在 2013 年年初開始第一次的運行使用,隨後馬上拓展到整個 Facebook,現在 Presto 已經佈署至全球各地上千個節點,成為 Facebook 公司最主要的互動式資料系統,供數千位工程師來使用,每天處理超過三萬個查詢工作,而一天內所處理的資料量高達 1 PB。
據 Facebook 的測試,Presto 在 CPU 的效率(efficiency)與延遲(latency)上的表現比起 Hive/MapReduce 要好上 10 倍,而目前它也支援大部分的 ANSI SQL 指令,剩下一些小問題待解決(例如 join tables 的大小限制等)。另外這個系統目前也無法將查詢結果寫回 table,只能直接傳送給 client。
未來規劃
Facebook 目前也正在積極開發 Presto 的各種功能與改善其效能,在未來幾個月中會處理 SQL 查詢上尚未解決的問題,另外也會開發查詢加速器,以新的資料格式讓進行查詢工作時免除不必要的資料轉換動作,另外也會開發高效能的 HBase connector。
開放原始碼
2013 年六月的 Analytics @ WebScale 研討會,Facebook 第一次發表 Presto,獲得廣大的回響,在過去幾個月中,Facebook 釋出其原始碼與二進位版本給一些商業公司進行測試(如 AirBnB 與 Dropbox),都獲得不錯的回應。
而現在 Facebook 將 Presto 的原始碼完全開放,任何人都可以從 Presto 的網站下載其原始程式碼與說明文件,Facebook 開放其原始碼的目的主要試想藉著全世界開發者的力量來一起開發 Presto,如果你有興趣,也可以去研究看看。
參考資料:Facebook