目前為止我們看到的範例資料都是儲存在單一檔案中,但有些時候狀況可能沒有那麼單純,在實際的資料分析上,我們可能會遇到資料散佈在多個檔案中的狀況,而不同檔案中的資料有不同的欄位,靠著其中一個資料編號或 ID 的欄位互相連結,遇到這樣的資料時,我們就必須先把多張資料表合併,才能繼續後續的分析工作。
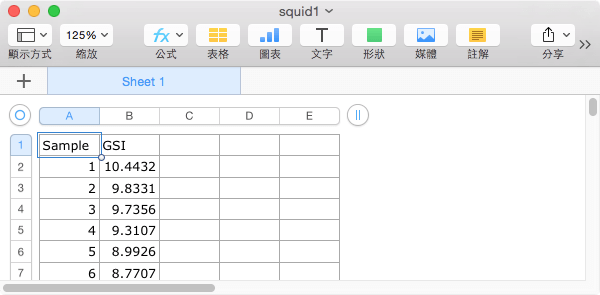
假設我們現在拿到兩個資料表,資料的欄位如下,第一個資料表有 Sample 與 GSI 兩個欄位。
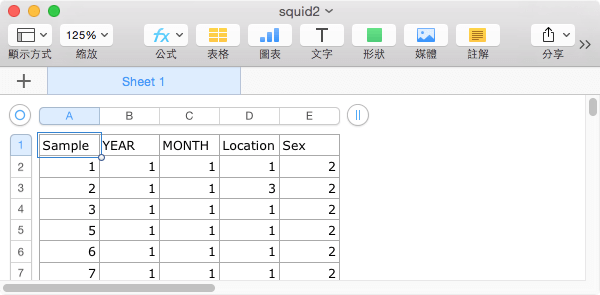
第二個資料表有 Sample、YEAR、MONTH、Location 與 Sex 這幾個欄位。
兩個資料表同時都有 Sample 這個欄位,我們要做的事情就是依照 Sample 的編號,將兩個資料表合併整的表格,以利後續的分析。
在實務上這樣兩個資料表的資料筆數不一定相同,最常發生的狀況就是有一些資料不小心搞丟了,或是因為某些原因無法取得,我們故意將 Squid2 這個資料表的第 4 筆資料刪掉,以模擬這樣的狀況。
R 裡面的 merge 函數就是特別為了處理這樣的問題而設計的,首先將兩個資料表讀進 R 中:
Sq1 <- read.table(file = "squid1.txt", header = TRUE) Sq2 <- read.table(file = "squid2.txt", header = TRUE)
接著使用 merge 合併:
SquidMerged <- merge(Sq1, Sq2, by = "Sample") SquidMerged
輸出為:
Sample GSI YEAR MONTH Location Sex 1 1 10.4432 1 1 1 2 2 2 9.8331 1 1 3 2 3 3 9.7356 1 1 1 2 4 5 8.9926 1 1 1 2 5 6 8.7707 1 1 1 2 6 7 8.2576 1 1 1 2 [略]
merge 函數的第一、二個參數是指定要合併的資料表,而 by 參數則是指定資料辨識的依據欄位。預設的狀況下,merge 會將有缺失值的資料忽略,所以上面這樣產生的資料並不會包含 Sample 為 4 的那一筆資料。我們可以將 all 參數設定為 TRUE(預設為 FALSE),讓含有缺失值的資料也一併被保留。
SquidMerged <- merge(Sq1, Sq2, by = "Sample", all = TRUE) SquidMerged
輸出為:
Sample GSI YEAR MONTH Location Sex 1 1 10.4432 1 1 1 2 2 2 9.8331 1 1 3 2 3 3 9.7356 1 1 1 2 4 4 9.3107 NA NA NA NA 5 5 8.9926 1 1 1 2 6 6 8.7707 1 1 1 2 7 7 8.2576 1 1 1 2 [略]
第 4 筆資料的缺失值會以 NA 來表示。
{kind=link}
{kind=link}