實作 CNN 的部分由於內容與理論牽涉相當廣,我實在沒時間詳細寫,只記錄關鍵重點,閱讀時請同時參考 TensorFlow 的官方文件以及 API 手冊。
實作 CNN(Convolutional Neural Network)之前,請先熟悉 CNN 的理論。
由於使用 ReLU neurons,所以在初始化權重時,最好再加上一點正的偏差值(bias),避免產生 dead neurons。
我們定義兩個初始化權重與偏差值用的函數:
def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)
在 TensorFlow 中提供了許多的 convolution 與 pooling 運算,這裡我們使用 stride 為 1 的 convolution,邊界使用補零(zero padded)的方式處理,所以輸入與輸出的資料大小是相同的。而 pooling 則是普通的 2×2 max pooling。
def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
關於 convolution 與 pooling 的詳細說明,請參考 TensorFlow 的 API 文件,另外也要參考 conv2d 與 max_pool 的文件。
第一層包含了一個 5×5 的 convolution,輸出 32 個特徵值(features),後面接著一個 max pooling,首先初始化權重與偏差值:
W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32])
接著將 x 轉為四維的 tensor,第二維與第三維分別對應影像的寬度與高度,第四維則是影像的顏色 channel。
x_image = tf.reshape(x, [-1, 28, 28, 1])
將 x_image 拿來與 conv1 做 convolution,再加上一個偏差值後,經過 ReLU 函數轉換,最後經過 max pooling 將影像轉為 14×14 的輸出。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1)
第一層的結構與第一層類似,不過我們在這一層會輸出 64 個特徵值。
W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2)
這一層我們放了 1024 個 neurons,連接 7 * 7 * 64 的特徵值,在運算時我們將之前 max pooling 的輸出轉為向量,乘以權重矩陣,加上偏差值,再套用 ReLU 函數。
W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
為了避免 overfitting,我們再加上一個 dropout 函數。
keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
最後一叢就是輸出數字用的一層,將 1024 個特徵轉為 10 個輸出。
W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
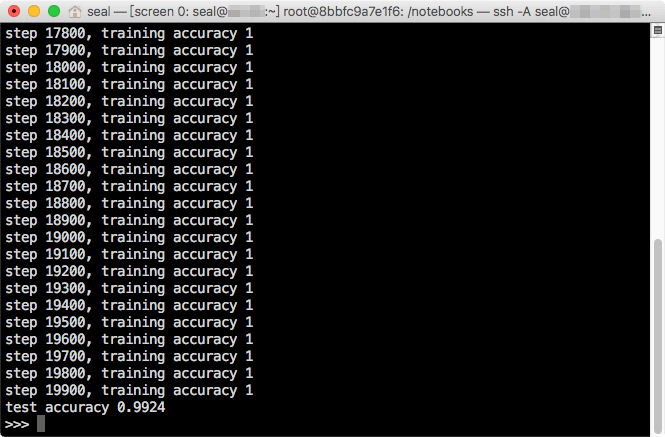
訓練模型的過程跟之前差不多,只是這裡我們使用 ADAM optimizer,並且在輸入的參數上多加了一個 dropout 用的 keep_prob,以及在每 100 次的迭代時輸出一些模型的狀態資訊。
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
模型經過訓練之後,準確率大約可以達到 99.24% 左右。
參考資料:TensorFlow
Page: 1 2
{kind=link}