tf.train API在建立好模型之後,接著就是要使用既有的資料對模型進行訓練,TensorFlow 所提供的 optimizers 可以對模型的 variable 進行微調,讓 loss function 達到最小,而最簡單的 optimizer 就是 gradient descent,他會依照 loss function 對個變數的 gradient 方向調整變數,TensorFlow 的 tf.gradients 可以幫助我們計算函數的微分,而 optimizers 也會自動幫我們處理這部分的問題。
首先建立一個 gradient descent optimizer,並指定 loss function:
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
將原本的變數設定為預設的錯誤組合,然後使用使用迴圈訓練模型,找出最佳的變數組合:
sess.run(init) # 將變數重設為錯誤的組合 for i in range(1000): sess.run(train, {x:[1,2,3,4], y:[0,-1,-2,-3]})
輸出結果:
print(sess.run([W, b]))
[array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]
前面我們完成了一個簡單的線性迴歸模型程式,其完整的程式碼如下:
import tensorflow as tf # 模型參數 W = tf.Variable([.3], dtype=tf.float32) b = tf.Variable([-.3], dtype=tf.float32) # 輸入與輸出的資料 x = tf.placeholder(tf.float32) linear_model = W * x + b y = tf.placeholder(tf.float32) # loss function loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares # optimizer optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss) # training data x_train = [1, 2, 3, 4] y_train = [0, -1, -2, -3] # 初始化、重設模型參數 init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) # 最佳化迴圈 for i in range(1000): sess.run(train, {x:x_train, y:y_train}) # 輸出結果 curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train}) print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11
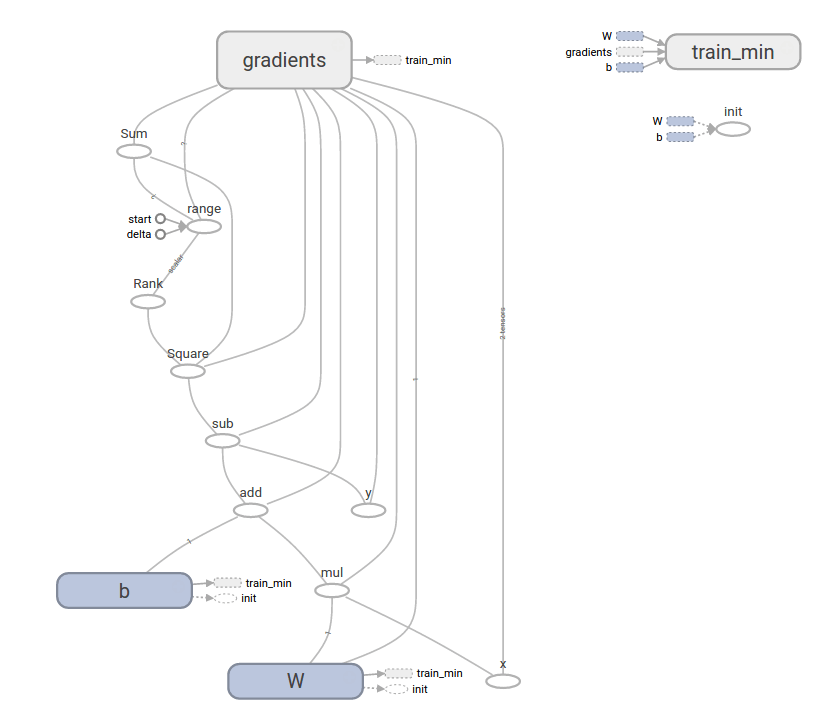
整個模型以 TensorBoard 畫出來會像這樣:
這樣就完成一個基本的機器學習程式了,接下來我們要介紹一些比較高階的 TensorFlow API,使用這些高階 API 可以讓使用者在處理典型的問題上更快速、更簡單。
tf.contrib.learntf.contrib.learn 是一個高階的 TensorFlow API,可以處理模型的訓練與評估等各種常用的機器學習工作。
以下是使用 tf.contrib.learn 來實作線性迴歸模型的程式碼:
import tensorflow as tf # NumPy 時常用於載入與整理資料 import numpy as np # 宣告特徵(fetures),此例中只有一個實數的特徵 features = [tf.contrib.layers.real_valued_column("x", dimension=1)] # 定義模型,此例使用線性迴歸模型 estimator = tf.contrib.learn.LinearRegressor(feature_columns=features) # 定義資料,並指定 batch 與 epochs 的大小 x_train = np.array([1., 2., 3., 4.]) y_train = np.array([0., -1., -2., -3.]) x_eval = np.array([2., 5., 8., 1.]) y_eval = np.array([-1.01, -4.1, -7, 0.]) input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x_train}, y_train, batch_size = 4, num_epochs = 1000) eval_input_fn = tf.contrib.learn.io.numpy_input_fn( {"x":x_eval}, y_eval, batch_size = 4, num_epochs = 1000) # 進行模型的訓練 estimator.fit(input_fn = input_fn, steps = 1000) # 驗證模型 train_loss = estimator.evaluate(input_fn=input_fn) eval_loss = estimator.evaluate(input_fn=eval_input_fn) print("train loss: %r"% train_loss) print("eval loss: %r"% eval_loss)
train loss: {'loss': 2.0923761e-07, 'global_step': 1000}
eval loss: {'loss': 0.0025518893, 'global_step': 1000}
tf.contrib.learn 也允許使用者自訂模型,以下是自訂模型的範例:
import numpy as np import tensorflow as tf # 自訂模型 def model(features, labels, mode): # 建立線性迴歸模型 W = tf.get_variable("W", [1], dtype=tf.float64) b = tf.get_variable("b", [1], dtype=tf.float64) y = W * features['x'] + b # loss function 的 sub-graph loss = tf.reduce_sum(tf.square(y - labels)) # 訓練的 sub-graph global_step = tf.train.get_global_step() optimizer = tf.train.GradientDescentOptimizer(0.01) train = tf.group(optimizer.minimize(loss), tf.assign_add(global_step, 1)) # 使用 ModelFnOps 將我們建立的 subgraphs 包裝好 return tf.contrib.learn.ModelFnOps( mode=mode, predictions=y, loss=loss, train_op=train) # 定義模型 estimator = tf.contrib.learn.Estimator(model_fn=model) # 定義資料,並指定 batch 與 epochs 的大小 x_train = np.array([1., 2., 3., 4.]) y_train = np.array([0., -1., -2., -3.]) x_eval = np.array([2., 5., 8., 1.]) y_eval = np.array([-1.01, -4.1, -7, 0.]) input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x_train}, y_train, 4, num_epochs=1000) # 進行模型的訓練 estimator.fit(input_fn=input_fn, steps=1000) # 驗證模型 train_loss = estimator.evaluate(input_fn=input_fn) eval_loss = estimator.evaluate(input_fn=eval_input_fn) print("train loss: %r"% train_loss) print("eval loss: %r"% eval_loss)
train loss: {'loss': 2.0923761e-07, 'global_step': 1000}
eval loss: {'loss': 0.0025518893, 'global_step': 1000}
參考資料:TensorFlow
Page: 1 2
{kind=link}