Beautiful Soup 本身只是一個 HTML 解析工具,它並不負責下載網頁,所以通常我們在開發爬蟲程式時,會搭配 requests 模組一同使用。
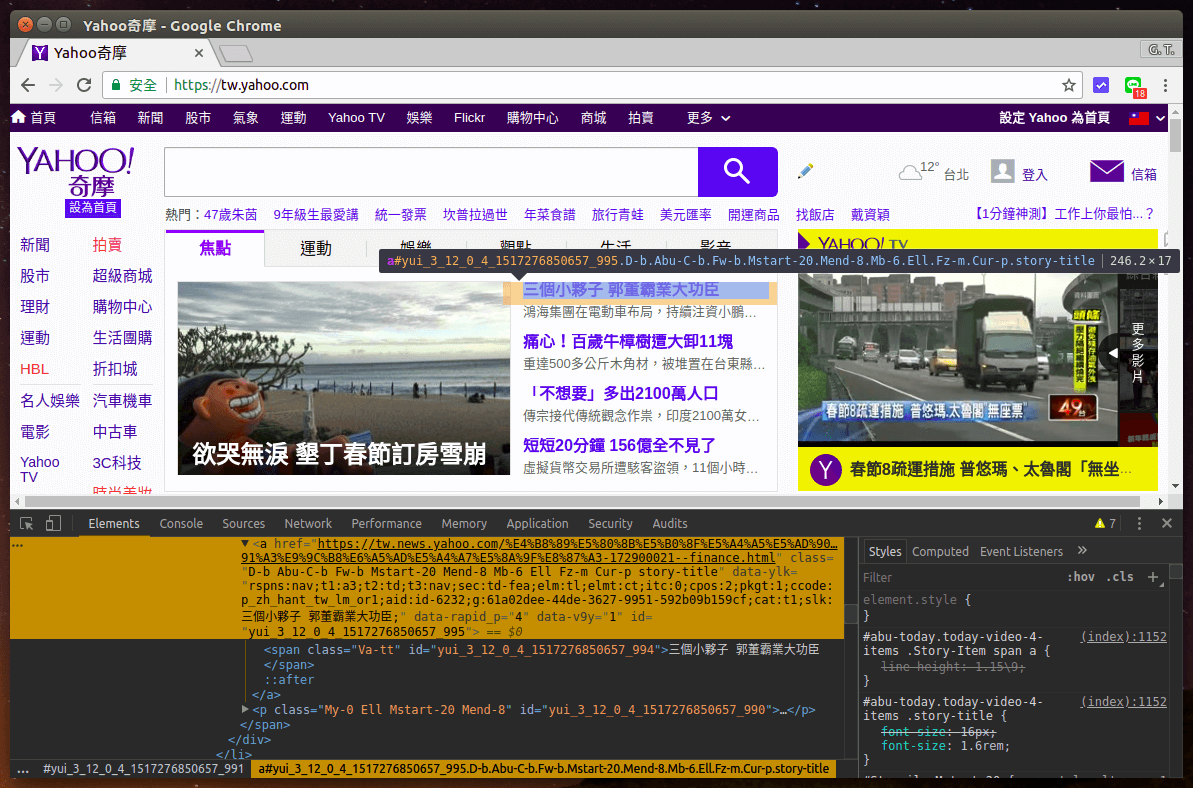
在這個範例中,我們打算開發一個爬蟲程式,可從 Yahoo 的首頁把頭條新聞的標題與網址抓下來,在開發程式之前,我們通常都會先用瀏覽器的開發人員工具,觀察一下目標網頁的 HTML 結構,找出我們有興趣的資料所在位置,並設計好萃取資料的規則。
以 Yahoo 頭條新聞來說,我們可以發現網頁中的頭條新聞超連結都有 story-title 這個 CSS 的 class,所以我們只要找出網頁中所有符合此條件的標籤,就可以把頭條新聞的資訊抓出來了。
以下是使用 requests 模組從 Yahoo 下載首頁的 HTML 資料後,以 Beautiful Soup 翠取出頭條新聞標題的指令稿:
import requests from bs4 import BeautifulSoup # 下載 Yahoo 首頁內容 r = requests.get('https://tw.yahoo.com/') # 確認是否下載成功 if r.status_code == requests.codes.ok: # 以 BeautifulSoup 解析 HTML 程式碼 soup = BeautifulSoup(r.text, 'html.parser') # 以 CSS 的 class 抓出各類頭條新聞 stories = soup.find_all('a', class_='story-title') for s in stories: # 新聞標題 print("標題:" + s.text) # 新聞網址 print("網址:" + s.get('href'))
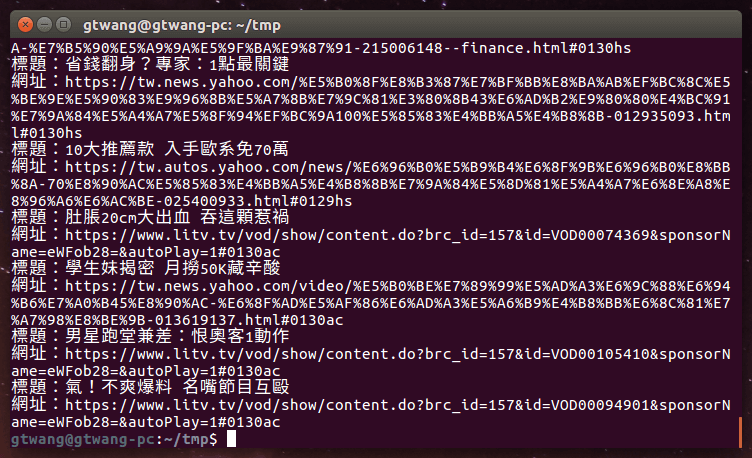
程式執行之後,就會輸出 Yahoo 首頁頭條新聞的標題與網址:
這個範例我們要開發一個可以自動送出關鍵字到 Google 進行搜尋,並將搜尋結果抓回來的爬蟲程式,基本的開發概念都相同,只不過 Google 的網頁會因為瀏覽器(User-Agent)不同而產生不同的結果,所以在觀察程式碼的時候,最好是使用 Beautiful Soup 的 prettify 把抓回來的 HTML 原始碼排版後印出來,這樣看會比較準確。
Google 搜尋引擎網址是 https://www.google.com.tw/search,而關鍵字則是透過 q 這個參數送給它,這個規則只要稍微觀察一下瀏覽器所顯示的網址即可推論出來,有了這個規則之後,就可以用 requests 與 BeautifulSoup 先把 Google 搜尋結果的 HTML 原始碼抓下來看看。
接著再設計一下萃取資料的規則,這裡我使用一個自己設計的 CSS 的選擇器:
div.g > h3.r > a[href^="/url"]
它可以抓出 class 為 g 的 <div>,底下緊接著 class 為 r 的 <h3>,底下又接著網址為 /url 開頭的超連結。
設計好資料萃取的規則後,就可以把整個程式來了,以下是完整的 Google 搜尋爬蟲程式:
import requests from bs4 import BeautifulSoup # Google 搜尋 URL google_url = 'https://www.google.com.tw/search' # 查詢參數 my_params = {'q': '寒流'} # 下載 Google 搜尋結果 r = requests.get(google_url, params = my_params) # 確認是否下載成功 if r.status_code == requests.codes.ok: # 以 BeautifulSoup 解析 HTML 原始碼 soup = BeautifulSoup(r.text, 'html.parser') # 觀察 HTML 原始碼 # print(soup.prettify()) # 以 CSS 的選擇器來抓取 Google 的搜尋結果 items = soup.select('div.g > h3.r > a[href^="/url"]') for i in items: # 標題 print("標題:" + i.text) # 網址 print("網址:" + i.get('href'))
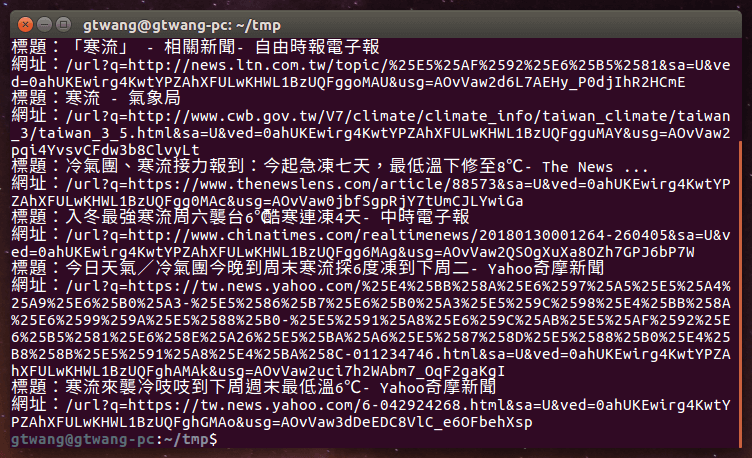
執行後,就可以自動透過 Google 搜尋關鍵字,然後馬上把結果抓回來。
{kind=link}
{kind=link}
{kind=link}