本篇為史丹佛大學機器學習(Machine Learning)課程 Lecture 3 的前半段筆記,接續 Lecture 2 的內容。
Lecture 3 的線上課程錄影可以從 YouTube 網站上觀看。
在前面的線性迴歸問題當中,那個最小平方的 cost function \(J\) 是怎麼來的?為什麼可以這樣定義?在這裡我們將在一些機率的假設下,解釋他是怎麼來的。
這裡我們設目標變數(target variable)與輸入變數(input variable)之間的關係符合
\[y^{(i)}=\theta^Tx^{(i)}+\epsilon^{(i)}\]
其中 \(\epsilon^{(i)}\) 是一個誤差項(error term),而這個誤差除了包含一些隨機的誤差之外,也可能包含一些沒有被納入迴歸模型的變數(例如可能有一些對於房價影響很大的變數沒有被我們發現)。接著我們假設 \(\epsilon^{(i)}\) 的分配是 IID(independently and identically distributed,獨立且同分配)的高斯分佈(Gaussian distribution),或稱為常態分佈(Normal distribution),平均數(mean)為零,變異數(variance)為 \(\sigma^2\),這樣的假設可以寫成「\(\epsilon^{(i)} \sim \mathcal{N}(0,\sigma^2)\)」,所以 \(\epsilon^{(i)}\) 的機率密度函數為
\[p(\epsilon^{(i)})=\frac{1}{\sqrt{2\pi}\sigma}\exp\Big(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\Big)\]
所以我們可以直接得到
\[p(y^{(i)}\mid x^{(i)};\theta)=\frac{1}{\sqrt{2\pi}\sigma}\exp\Big(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\Big)\]
這裡的 \(p(y^{(i)}\mid x^{(i)};\theta)\) 是 \(y^{(i)}\) 在給定 \(x^{(i)}\) 的情況下的機率密度函數,而 \(\theta\) 則是這個機率密度函數的一個參數,我們不可以將這個式子寫成 \(p(y^{(i)}\mid x^{(i)},\theta)\),因為這裡的 \(\theta\) 並不是一個隨機變數。另外我們可以這樣描述 \(y^{(i)}\) 的分佈:
\[y^{(i)}\mid x^{(i)};\theta\sim\mathcal{N}(\theta^Tx^{(i)},\sigma^2)\]
這裡的 \(\epsilon^{(i)}\) 之所以假設為常態分佈主要有兩個原因,一個是在數學上推導時比較方便,另外一個則是根據中央極限定理(Central Limit Theorem)的概念,因為中央極限定裡告訴我們,當很多獨立且同分配的隨機變數加總之後,會是一個常態分佈,因為誤差「應該」是由許多變異的因子加總而成,再加上許多實務上的經驗顯示:在一般的線性迴歸分析中,這些誤差的分佈很接近常態分佈,所以我們就假設它是常態分佈了,不過說到底這也只是假設而已,很難保證所有的狀況都一定適用。
另外補充一點,在 Bayesian inference 上所使用的 \(p(y^{(i)}\mid x^{(i)},\theta)\) 是代表 \(\theta\) 是一個超參數(hyperparameter),在這種狀況下 \(\theta\) 也是一個隨機變數,但跟這裡討論的 frequentist inference 的狀況完全不同,如果有興趣的話可以去查閱貝氏統計(Bayesian statistics)的資料。
接著如果以矩陣的的表示方式,給定一個設計矩陣(design matrix)\(X\) 與 \(\theta\),那 \(\vec{y}\) 的機率密度函數就會是 \(p(\vec{y}\mid X;\theta)\),而這個函數一般都看成是一個 \(\vec{y}\) 的函數(或是 \(X\) 的函數),而 \(\theta\) 則視為一個固定的數值,而當我們將這個函數視為 \(\theta\) 的函數時,這個函數就稱為概似函數(likelihood function):
\[L(\theta)=L(\theta;X,\vec{y})=p(\vec{y}\mid X;\theta)\]
由於 \(\epsilon^{(i)}\) 都是獨立的(independent),所以 \(y^{(i)}\) 在給定 \(x^{(i)}\) 之下也是獨立的,因此
\begin{aligned}
L(\theta)=&\prod^m_{i=1}p(y^{(i)}\mid x^{(i)},\theta)\\
=&\prod^m_{i=1}\frac{1}{\sqrt{2\pi}\sigma}\exp\Big(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\Big)
\end{aligned}
接著在這個 \(y^{(i)}\) 與 \(x^{(i)}\) 的機率模型之下,該如何估計 \(\theta\) 才是最恰當的呢?最大概似法(Method of Maximum Likelihood)告訴我們應該要找一個可以讓資料出現的機率值最大的 \(\theta\),也就是讓 \(L(\theta)\) 產生最大值的 \(\theta\)。
為了找尋 \(L(\theta)\) 的做大值,我們先對它做一個對數轉換(這樣會比較好計算),轉換後得到一個 log likelihood function:
\begin{aligned}
l(\theta)=&\log L(\theta)\\
=&\log\prod^m_{i=1}\frac{1}{\sqrt{2\pi}\sigma}\exp\Big(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\Big)\\
=&\sum^m_{i=1}\log\frac{1}{\sqrt{2\pi}\sigma}\exp\Big(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\Big)\\
=&m\log\frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{\sigma^2}\cdot\frac{1}{2}\sum^m_{i=1}(y^{(i)}-\theta^Tx^{(i)})^2
\end{aligned}
因為 log 是一個嚴格遞增函數(strictly increasing funtion),所以 \(l(\theta)\) 與 \(L(\theta)\) 的最大值發生的地方是一樣的,而要找 \(\mathcal{l}(\theta)\) 的最大值,其實就是找
\[\frac{1}{2}\sum^m_{i=1}(y^{(i)}-\theta^Tx^{(i)})^2\]
的極小值,而這個式子就是我們之前所定義的 \(J(\theta)\),所以接下去要做的事情就跟前面所講述的一模一樣。
在這裡的一些機率假設之下,最小平方迴歸(least-squares regression)分析事實上就是找 \(\theta\) 的最大概似估計量(maximum likelihood estimator),在這個假設之下一切都很合理,但是問題在於這個假設不一定每次都適用,有時候可能使用其他的假設會更好,這裡使用的只是其中一種而已。
另外在最後估計 \(\theta\) 的時候,其實跟 \(\sigma^2\) 沒有關係,所以縱使 \(\sigma^2\) 是未知的,我們還是可以得到同樣的結果,這個性質在之後討論 exponential family 與 generalized linear models 時還會用到。
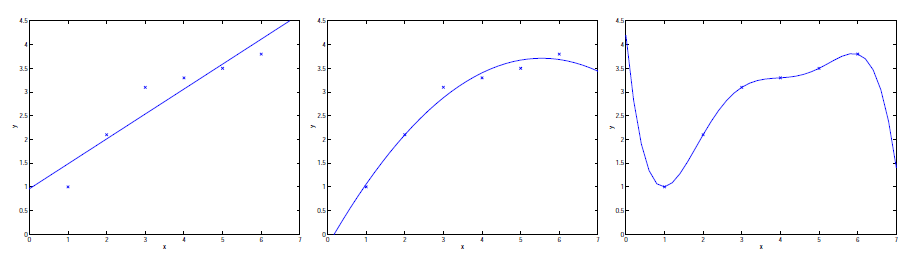
這裡我們考慮一個最簡單的回歸問題,輸入變數 \(x\in\mathbb{R}\),輸出變數為 \(y\),最左邊的圖形是 \(y=\theta_0+\theta_1x\) 這個模型所配適的結果,從圖形上可以看出來因為我們的資料沒有在一條直線上,所以並沒有配適的很好。
接著我們加入另外一個變數 \(x^2\),整個模型變成 \(y=\theta_0+\theta_1x+\theta_2x^2\),配適的結果是中間這張圖,很明顯的這個結果比左邊的好很多。看起來好像加了越多變數,結果就會越好,但是其實不盡然,如果變數加的太多時反而會適得其反,右邊那張圖就是使用五階的多項式 \(y=\sum^5_{j=1}\theta_jx^j\) 來配適的結果,我們可以看出來那一條配適出來的曲線完美的通過每一個點,但是我們不會認為這樣的配適結果有多好(至少就房價的資料來說,這樣的結果根本不合理)。
大致上來說,像左邊這張圖的配適情況,模型跟資料的差距甚遠,配釋出來的模型沒有辦法解釋我們的資料,這樣的狀況我們稱為 underfitting,而相反的,在右邊這張圖的配適狀況則是 overfitting。(在之後的課程中,我們會正式定義這些相關的名詞,這裡只是先建立概念)
由上面的討論中,我們可以發現特徵變數的選取對於學習演算法的表現好壞有直接的關係(之後講到 model selection 時,將會討論到自動選取特徵變數的演算法),在這裡我們介紹區域加權線性迴歸(Locally Weighted Linear Regression,LWR),這種演算法適用於有足夠的 training data 的情況,它可以讓整個模型比較不會受到特徵變數選擇的影響。
在一般線性迴歸模型之下,要得到 \(x\) 這一點的預測值(也就是 \(h(x)\)),我們的步驟是:
而在區域加權線性迴歸下,步驟為:
其中 \(\omega^{(i)}\) 是每筆資料的權重,它是一個大於或等於零的數值,直觀的來看,當 \(\omega^{(i)}\) 比較大的時候,就表示該資料比較重要,我們要想辦法讓其對應的 \((y^{(i)}-\theta^Tx^{(i)})^2\) 盡量小一點,反之如果當 \(\omega^{(i)}\) 比較小的時候,就表示該資料比較不重要,其對應的 \((y^{(i)}-\theta^Tx^{(i)})^2\) 在配適模型時也影響不大。
我們選擇一種很常用的權重:
\[\omega^{(i)}=\exp\Big(-\frac{(x^{(i)}-x)^2}{2\tau^2}\Big)\]
這個權重在估計 \(x\) 時,會跟要估計的 \(x\) 點相關。當 \(\mid x^{(i)}-x\mid\) 比較小的時候,\(\omega^{(i)}\) 會比較接近 1,而當 \(\mid x^{(i)}-x\mid\) 比較大的時候,\(\omega^{(i)}\) 就會比較小,因此在估計 \(\theta\) 時,那些比較靠近 \(x\)(也就是要估計的那個點)的 training examples 就會有比較大的權重。(這裡的 \(\omega^{(i)}\) 雖然很類似常態分佈的機率密度函數,但是他跟常態分佈一點關係也沒有,而且它也不是隨機變數,所以不要把它們搞混了)
在另外一個參數 \(\tau\) 是控制 training examples 的權重遞減的速度,這個 \(\tau\) 稱為 bandwidth,如果這個值越大,則當 \(x^{(i)}\) 跟 \(x\) 的距離變大時,其權重就遞減的越慢。
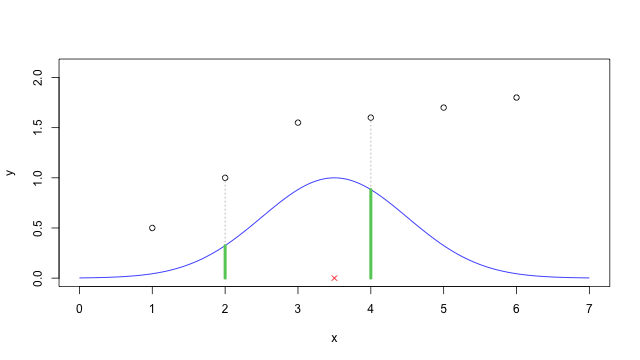
舉的例子:假設我們要估計的 \(x\) 為 3.5(紅色叉叉),而 bandwidth 參數 \(\tau\) 設為 1 的時候,將 \(\omega^{(i)}\) 的函數圖形畫出來就是藍色那條曲線,而每一點 \(x^{(i)}\) 的權重就是該點對應到這條曲線上的值(綠色的部分)。
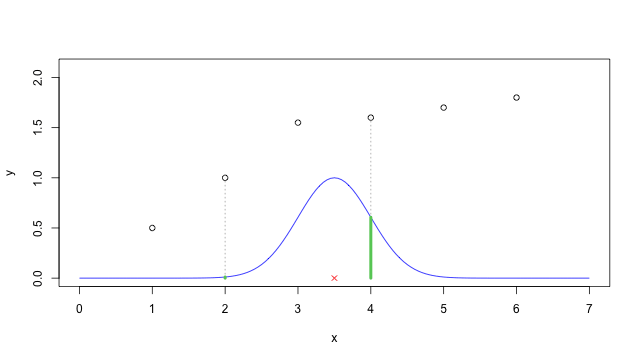
如果將 \(\tau\) 設為 0.5,則圖形就會變成這樣,很明顯的 \(\omega^{(i)}\) 的函數圖形寬度就變窄了,這就是 bandwidth 參數的作用。
這裡的圖形我是用 R 畫的,下面這個是 R 的指令稿,有時候自己畫一次會比較了解這些概念:
train.x <- c(1, 2, 3, 4, 5, 6) train.y <- c(0.5, 1, 1.55, 1.6, 1.7, 1.8) plot(train.x, train.y, ylim = c(0, 2.1), xlim = c(0, 7), xlab = "x", ylab = "y") x <- 3.5 tau <- 0.5 # weight function omega <- function(xi, t) { exp(-(xi-x)^2/(2*t^2)) } s<-seq(0, 7, by = 0.05) lines(s, omega(s, tau), col = "blue") segments(train.x[4], 0, train.x[4], train.y[4], lty="dotted", col="#AAAAAA") segments(train.x[4], 0, train.x[4], omega(train.x[4], tau), lty="solid", lwd=4, col="#66CC66") segments(train.x[2], 0, train.x[2], train.y[2], lty="dotted", col="#AAAAAA") segments(train.x[2], 0, train.x[2], omega(train.x[2], tau), lty="solid", lwd=4, col="#66CC66") points(x, 0, pch = 4, col = "red")
前面所談到的線性迴歸算是一種有母數(parametric)的演算法,因為它已經預先設定 \(\theta\) 參數的個數,然後才去配適資料,當我們將 \(\theta\) 配適完成之後,就可以把 training set 放在一邊,然後使用我們估計出來的 \(\theta\) 來進行預測,所以在預測時其實就不需要任何 training set 的資料了。
區域加權線性迴歸是我們討論到的第一個無母數(non-parametric)演算法,它跟以往有母數的線性回歸有一個很大的差異,就是在進行預測時,還是會需要使用到 training set 的資料,而所謂無母數的意思粗略的來說,就是指我們要保留所有的資料讓 hypothesis \(h\) 可以隨著 training set 的大小增加而增加。
{kind=link}
{kind=link}
{kind=link}