
本篇敘述如何使用 RHadoop 的 MapReduce 實作 k-means 分群演算法。
在架設好 RHadoop 計算環境之後,接著就可以使用 MapReduce 撰寫各種分析程式,以下是用 MapReduce 實作 k-means 的 R 程式碼。
這個 k-means 範例只是用來示範 MapReduce 的實作方法,程式碼比較簡單,不適合在實際的應用上使用。
# 載入 rmr2 套件
library(rmr2)
# 使用 MapReduce 實作 k-means 分群演算法
kmeans.mr <- function(
P, # 點座標矩陣,每一列代表一個點
num.clusters, # 群集的數量
num.iter, # 迭代次數
combine,
in.memory.combine) {
# 計算每個中心點座標 C 與每一點 P 的距離
dist.fun <- function(C, P) {
apply(
C,
1,
function(x) colSums((t(P) - x)^2))
}
# Map 函數,分散計算各點與所有中心點的距離
kmeans.map <- function(., P) {
nearest = {
if(is.null(C)) {
# 若沒有初始化中心點,則隨機產生
sample(
1:num.clusters,
nrow(P),
replace = TRUE)
} else {
# 計算部分點與所有中心點的距離
D = dist.fun(C, P)
# 挑出最近的中心點編號
nearest = max.col(-D)
}
}
if(!(combine || in.memory.combine))
keyval(nearest, P)
else
# 加入一個都是常數 1 的一行,記錄資料筆數,方便之後計算平均
keyval(nearest, cbind(1, P))
}
# Reduce 函數,分散計算各點與所有中心點的距離
kmeans.reduce = {
if (!(combine || in.memory.combine) ) {
# 計算每一行的平均,得到新的中心點位置
function(., P) t(as.matrix(apply(P, 2, mean)))
} else {
# 計算每一行的總和,用於 reduce 與 combine
function(k, P)
keyval(
k,
t(as.matrix(apply(P, 2, sum))))
}
}
# 使用 MapReduce 迭代計算中心點 C
C <- NULL
for (i in 1:num.iter) {
C <- values(from.dfs(mapreduce(
P,
map = kmeans.map,
reduce = kmeans.reduce)))
# 若有使用 combine,則在此用總和計算平均
if(combine || in.memory.combine)
C = C[, -1]/C[, 1]
# 處理中心點消失問題
if(nrow(C) < num.clusters) {
C <- rbind(
C,
matrix(
rnorm(
(num.clusters -
nrow(C)) * nrow(C)),
ncol = nrow(C)) %*% C)
}
}
# 傳回結果
C
}
產生測試用的資料:
# 設定亂數種子
set.seed(0)
# 產生測試座標點資料
P <- do.call(rbind, rep(
list(matrix(rnorm(10, sd = 10), ncol = 2)), 20)) +
matrix(rnorm(200), ncol = 2)
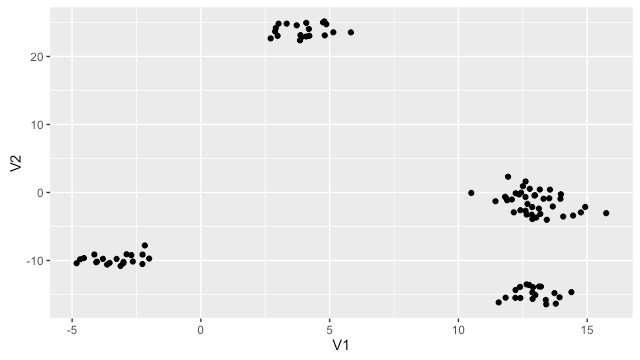
若要查看資料,可以用 ggplot2 將資料點畫出來看:
# 查看測試資料
library(ggplot2)
qplot(V1, V2, data = as.data.frame(P))
執行 MapReduce 版本的 k-means:
kmeans.mr(
to.dfs(P),
num.clusters = 4,
num.iter = 10,
combine = FALSE,
in.memory.combine = FALSE)
[,1] [,2] [1,] 12.931487 -14.925114 [2,] -3.331972 -9.848412 [3,] 12.946355 -1.409949 [4,] 3.997781 23.809110
若需要測試程式的正確性,可以使用單機版的 MapReduce 來測試:
rmr.options(backend = "local")
kmeans.mr(
to.dfs(P),
num.clusters = 4,
num.iter = 10,
combine = FALSE,
in.memory.combine = FALSE)