本篇介紹如何在 R 環境中,管理與操作各種資料,在實際進行分析之前,做一些前置性的準備動作。
在統計分析的過程中,我們時常會需要對資料進行一些前置處理,例如刪除或萃取部分資料、以及資料的排序等,這些動作也可以在匯入 R 之前,使用 Excel 這類的軟體來先進行處理,不過使用 Excel 來處理的話,每次選擇資料時就需要將資料重新匯入 R,處理步驟比較繁雜,另外如果資料量太大,可能也會無法使用 Excel 來處理,因此學習如何在 R 環境中進行基本的資料處理是有必要的。
許多初學者可能會認為在 R 環境中處理資料是很困難的事情,但是一旦學會了這些技巧之後,許多在 Excel 中很惱人的資料處理動作,也都可以在 R 中完成,甚至更快速而且更輕鬆。
R 存取 Data Frame 的資料
首先將 squid.txt 這個檔案讀取進來:
setwd("C:/YOUR_PATH/")
Squid <- read.table(file = "squid.txt", header = TRUE)
由於大部份的 R 函數都是使用 data frame 來存取資料,所以一般建議是盡量使用 read.table 來讀取資料,而不要用 scan。
將資料讀取進來之後,我們可以使用 names 來查看資料的欄位:
names(Squid)
輸出會像這樣:
[1] "Sample" "Year" "Month" "Location" "Sex" "GSI"
str 函數
str 函數(structure)可以顯示 data frame 中所有欄位的資訊:
str(Squid)
輸出為:
'data.frame': 2644 obs. of 6 variables: $ Sample : int 1 2 3 4 5 6 7 8 9 10 ... $ Year : int 1 1 1 1 1 1 1 1 1 1 ... $ Month : int 1 1 1 1 1 1 1 1 1 2 ... $ Location: int 1 3 1 1 1 1 1 3 3 1 ... $ Sex : int 2 2 2 2 2 2 2 2 2 2 ... $ GSI : num 10.44 9.83 9.74 9.31 8.99 ...
我們可以從這個輸出中看出來,Sample、Year、Month、Location 與 Sex 都是整數(int),而 GSI 則是數值(num)。假設我們不小心輸入錯誤指令:
Squid2 <- read.table(file = "squid.txt", dec = ",", header = TRUE)
雖然資料還是可以正常讀取進來,而且沒有錯誤訊息,但是用 str 檢查資料時,就會發現問題:
str(Squid2)
輸出為
'data.frame': 2644 obs. of 6 variables: $ Sample : int 1 2 3 4 5 6 7 8 9 10 ... $ Year : int 1 1 1 1 1 1 1 1 1 1 ... $ Month : int 1 1 1 1 1 1 1 1 1 2 ... $ Location: int 1 3 1 1 1 1 1 3 3 1 ... $ Sex : int 2 2 2 2 2 2 2 2 2 2 ... $ GSI : Factor w/ 2472 levels "0.0064","0.007",..: 1533 2466 2462 2445 2428 2407 2379 2308 2288 2247 ...
這裡 GSI 變數現在被視為一個 factor,如果使用這樣的資料進行後續的分析時(例如畫 boxplot 或計算平均數),就會出現錯誤:
mean(Squid$GSI)
[1] 2.187034
mean(Squid2$GSI)
[1] NA Warning message: In mean.default(Squid2$GSI) : argument is not numeric or logical: returning NA
在使用 R 分析資料時,常常很容易發生類似的問題,所以建議在讀取資料之後,記得要使用 str 檢查一下資料是否正確。
這裡我們有興趣的變數是 GSI,接下來我們想要看看 GSI 與其他變數之間的關係,而在實際建立模型之前,通常會先畫一些簡單的圖(如 boxplot、dot plot、scatter plot 與 pair plot 等),大略看一下資料的狀況。
目前 GSI 是儲存在 Squid 這個 data frame 中,以下有幾種可以存取 data frame 資料的方式,請繼續閱讀下一頁。
R 函數的 data 參數
在 R 中有許多函數都可以透過 data 參數來指定 data frame,例如線性回歸的 lm:
M1 <- lm(GSI ~ factor(Location) + factor(Year), data = Squid)
第一個參數是指定線性回歸的模型,我們在這裡尚不討論這個部分,而第二個參數就是以 data 參數指定 data frame 為 Squid,告知 R 迴歸模型中的變數是存在於這個 data frame 中。這種方式可以讓所有的資料都放在一個 data frame 中,除了方便管理之外,在資料變數很多的時候,也可以避免變數名稱互相衝突。
不過不是每一個常見的函數都支援 data 參數,例如 mean 就不支援:
mean(GSI, data = Squid)
這樣執行之後,就會產生錯誤:
Error in mean(GSI, data = Squid) : 找不到物件 'GSI'
通常我們可以查詢函數的線上手冊(help),來確認該函數使否有支援 data 參數,有些函數甚至在某些用法有支援,有些則沒有,例如 boxplot 就是這樣:
boxplot(GSI ~ factor(Location), data = Squid)
上面這行指令可以正常執行,不過換另外一種寫法,就會有問題:
boxplot(GSI, data = Squid)
執行這行指令會出現這樣的錯誤訊息:
Error in boxplot(GSI, data = Squid) : 找不到物件 'GSI'
基本上在函數有支援 data 參數的狀況下,使用 data 參數是最好的選擇,這樣可以讓命名空間比較乾淨一些。
錢字號($)
對於沒有支援 data 參數的函數,可以改用錢字號($)的方式來取用 data frame 的變數:
Squid$GSI
輸出為
[1] 10.4432 9.8331 9.7356 9.3107 8.9926 [6] 8.7707 8.2576 7.4045 7.2156 6.8372 [11] 6.3882 6.3672 6.2998 6.0726 5.8395 [略]
在錢字號與變數名稱之間可以允許空白:
Squid $ GSI
但是習慣上不建議這樣寫,這樣看起來很奇怪。
另外也可以用指定欄位編號的方式來存取 data frame 中的變數,例如要取得 Squid 的第 6 欄:
Squid[, 6]
在實際使用時,不管哪一種方式都可以:
mean(Squid$GSI)
mean(Squid[, 6])
不過建議是使用 Squid$GSI,因為這種寫法比較清楚,經過一段時間之後若我們再回來看這個程式,Squid[, 6] 很容易讓人搞不清楚他到底是什麼,而 Squid$GSI 則是一看就知道他是什麼資料。
另外,還有另外一種寫法:
Squid[, "GSI"]
當 Squid$GSI 這種寫法無法使用時,就可以改用這種。
R 的 attach 函數
如果您不想要在每次使用變數時,都輸入 Squid$GSI 這樣累贅的名稱,我們可以使用 attach 函數將 Squid 納入 R 的搜尋路徑,這樣我們就可以直接使用 Squid 裡面的所有變數:
attach(Squid)
GSI
這時候任何函數也都可以直接取用這些變數:
boxplot(GSI)
mean(GSI)
雖然 attach 看起來很方便,但是如果要 attach 的變數名稱已經事先存在於全域變數中的話,就會產生問題,或是同時 attach 兩個有同樣變數名稱的 data frame 的話也會出問題,另外 attach 的變數名稱亦不可以跟既有的 R 關鍵字或是函數名稱相同(例如變數名稱如果取為 time,就會與 time 函數衝突),如果發生名稱衝突的問題時,您會發現 R 可能不會如您預期的那樣存取指定的變數資料。
如果要將特定的 data frame 從搜尋路徑中移除,可以使用 detach:
detach(Squid)
如果您一次只需要使用一個 data frame,並且小心運用 attach 與 detach,它會是一個很方便的功能,不過只限於研究與測試的情況,若要撰寫指令稿、發展正式的程式專案時,建議還是盡量避免這樣使用,以免未來城市結構變複雜時,發生變數名稱衝突的問題。
以下是 attach 使用上需要注意的重點整理:
- 不要重複執行
attach(Squid),以免變數名稱重複。 - 確保變數名稱都有一定的獨特性,盡量避免太過於一般性的名稱,例如
Month或Location。 - 如果需要
attach多個 data frame,但是一次只使用到一個 data frame,那麼建議將沒有用到的 data frame 先行detach。
Exercise 1
bird-flu.csv 這個檔案中記錄了數個國家 H5N1 禽流感的年度確診病例,這些資料是由各個國家回報給世界衛生組織(WHO)後所統計出來的,請依下列步驟分析這些資料:
- 將這些資料以
read.table讀進 R 中。 - 使用
names與str檢查資料。 - 列出 2003 年各國的確診病例數目。
- 計算 2003 年與 2005 年確診病例總數。
- 計算 China 與 Turkey 的確診病例總數。
R 資料的子集合(Subsets)
接下來我們要介紹如何從 Squid 這個 data frame 中萃取部分的資料出來,這個資料篩選的方式可以適用於任何的 data frame。
假設我們想要篩選出所有性別欄位(Sex)是男性或女性的資料,首先我們先看一下 Sex 裡面的資料:
Squid$Sex
資料大概是這個樣子:
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 [20] 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 [39] 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 [略]
由於資料筆數很多,很難看出到底有哪一些值,我們可以用 unique 來將重複的數值去掉:
unique(Squid$Sex)
輸出為
[1] 2 1
這裡的 1 代表男性,而 2 代表女性,若要篩選出男性的資料,可以執行:
Sel <- Squid$Sex == 1
SquidM <- Squid[Sel, ]
SquidM
輸出為
Sample Year Month Location Sex GSI 24 24 1 5 1 1 5.2970 48 48 1 5 3 1 4.2968 58 58 1 6 1 1 3.5008 60 60 1 6 1 1 3.2487 61 61 1 6 1 1 3.2304 [略]
這裡的第一行 Squid$Sex == 1 會檢查 Sex 的每一個值是否為 1,產生一個跟 Sex 一樣長度的向量,若 Sex 對應的值為 1,則產生 TRUE,若 Sex 的值不是 1,則產生 FALSE,而這樣的向量稱為布林向量(boolean vector),在篩選資料時通常都會透過這樣的方式來指定子集合,因此我們將這個向量名為 Sel。
第二行的 Squid[Sel, ] 是選擇所有 Sel 的值為 TRUE 的資料,並將這些資料儲存在 SquidM 中。
我們也可以將第一行與第二行合併,寫成:
SquidM <- Squid[Squid$Sex == 1, ]
SquidM
若要篩選出女性的資料,可以執行:
SquidF <- Squid[Squid$Sex == 2, ]
SquidF
這種透過布林向量篩選資料的方法可以用在非常多的地方,我們接下來想要根據 Location 這個欄位來篩選資料,首先看一下 unique 的結果:
unique(Squid$Location)
輸出為
[1] 1 3 4 2
如果我們想要篩選出 Location 是 1、2 或 3 的資料,可以有以下幾種方式:
Squid123 <- Squid[Squid$Location == 1 | Squid$Location == 2 | Squid$Location == 3, ]
Squid123 <- Squid[Squid$Location != 4, ]
Squid123 <- Squid[Squid$Location < 4, ]
Squid123 <- Squid[Squid$Location <= 3, ]
Squid123 <- Squid[Squid$Location >= 1 & Squid$Location <= 3, ]
第一行是利用 OR 運算子(|),將三個 == 的判斷結果結合起來,而第二行是直接判斷 Location 是否不等於(!=)4,第三行與第四行則是使用「小於」(<)以及「小於或等於」(<=)來判斷,最後一行則是將兩個判斷結果用 AND 運算子(&)結合,在這個例子中不管用哪一種寫法都可以獲得同樣的結果。
我們也可以同時使用多個欄位來產生布林向量,例如選擇 Sex 為 1 而且 Location 為 1 的資料:
SquidM.1 <- Squid[Squid$Sex == 1 & Squid$Location == 1,]
選擇 Sex 為 1 而且 Location 為 1 或 2 的資料:
SquidM.12 <- Squid[Squid$Sex == 1 & (Squid$Location == 1 | Squid$Location == 2), ]
有些初學者在產生布林向量時,很容易犯下這樣的錯誤:
SquidM <- Squid[Squid$Sex == 1, ]
SquidM1 <- SquidM[Squid$Location == 1, ]
SquidM1
輸出會像這樣:
Sample Year Month Location Sex 24 24 1 5 1 1 58 58 1 6 1 1 [略] NA NA NA NA NA NA NA.1 NA NA NA NA NA NA.2 NA NA NA NA NA [略]
這裡的第一行篩選出所有男性的資料,並儲存至 SquidM,因此 SquidM 的資料筆數會小於原來 Squid 的資料筆數(假設 Squid 中有女性的資料),因此在第二行中 Squid$Location==1 的長度會比 SquidM 的資料筆數還要多,多出來的部分就會以 NA 遞補,因此產生這樣奇怪的結果。若要修正這個錯誤,應該要改成這樣:
SquidM <- Squid[Squid$Sex == 1, ]
SquidM1 <- SquidM[SquidM$Location == 1, ]
SquidM1
另外如果沒有任何資料符合篩選的條件,狀況會類似這樣:
Squid[Squid$Location == 1 & Squid$Year == 4 & Squid$Month == 1, ]
輸出為
[1] Sample Year Month Location [5] Sex GSI (or 0-length row.names)
R 資料的排序(Sorting)
除了資料的篩選之外,排序也是一個很常會使用到的功能,以 Squid 的資料為例,我若我們希望資料可以依據 Month 的數值大小由小到大排序,可以執行:
Ord1 <- order(Squid$Month)
Squid[Ord1, ]
這樣整個資料就會依照月份來排序:
Sample Year Month Location Sex GSI 1 1 1 1 1 2 10.4432 2 2 1 1 3 2 9.8331 3 3 1 1 1 2 9.7356 [略]
在重新排序資料列(rows)時,記得要將 Ord1 放在逗號的前面。除此之外,我們也可以只針對特定的資料欄位排序,例如:
Squid$GSI[Ord1]
輸出為:
[1] 10.4432 9.8331 9.7356 9.3107 [5] 8.9926 8.7707 8.2576 7.4045 [9] 7.2156 6.3882 6.0726 5.7757 [13] 1.2610 1.1997 0.8373 0.6716 [略]
Exercise 2
ISIT.txt 檔案中儲存一些關於生物發光(bioluminescent)的資料,請依下列步驟分析這些資料:
- 將
ISIT.txt的資料讀進 R 中。 - 將
Station為1的資料篩選出來,計算Station為1的資料筆數。 - 使用
Station為1的資料計算SampleDepth的最小值、中位數、平均數與最大值。 - 分別計算
Station為2與3的SampleDepth的最小值、中位數、平均數與最大值。 - 找出資料筆數相對比較少的
Station,將這些Station的資料拿掉後,建立一個新的 data frame。 - 篩選出 2002 年所有的資料。
- 篩選出所有四月份的資料。
- 篩選出所有
SampleDepth大於2000的資料。 - 篩選出所有四月份且
SampleDepth大於2000的資料。 - 將資料依照
SampleDepth排序(由小到大)。
R 結合兩個資料表
目前為止我們看到的範例資料都是儲存在單一檔案中,但有些時候狀況可能沒有那麼單純,在實際的資料分析上,我們可能會遇到資料散佈在多個檔案中的狀況,而不同檔案中的資料有不同的欄位,靠著其中一個資料編號或 ID 的欄位互相連結,遇到這樣的資料時,我們就必須先把多張資料表合併,才能繼續後續的分析工作。
假設我們現在拿到兩個資料表,資料的欄位如下,第一個資料表有 Sample 與 GSI 兩個欄位。
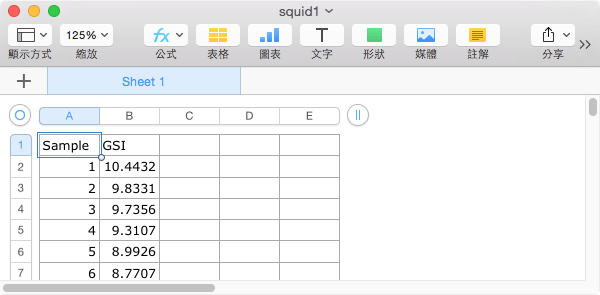
第二個資料表有 Sample、YEAR、MONTH、Location 與 Sex 這幾個欄位。
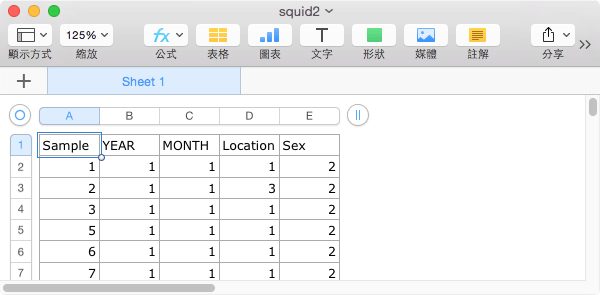
兩個資料表同時都有 Sample 這個欄位,我們要做的事情就是依照 Sample 的編號,將兩個資料表合併整的表格,以利後續的分析。
在實務上這樣兩個資料表的資料筆數不一定相同,最常發生的狀況就是有一些資料不小心搞丟了,或是因為某些原因無法取得,我們故意將 Squid2 這個資料表的第 4 筆資料刪掉,以模擬這樣的狀況。
R 裡面的 merge 函數就是特別為了處理這樣的問題而設計的,首先將兩個資料表讀進 R 中:
Sq1 <- read.table(file = "squid1.txt", header = TRUE)
Sq2 <- read.table(file = "squid2.txt", header = TRUE)
接著使用 merge 合併:
SquidMerged <- merge(Sq1, Sq2, by = "Sample")
SquidMerged
輸出為:
Sample GSI YEAR MONTH Location Sex 1 1 10.4432 1 1 1 2 2 2 9.8331 1 1 3 2 3 3 9.7356 1 1 1 2 4 5 8.9926 1 1 1 2 5 6 8.7707 1 1 1 2 6 7 8.2576 1 1 1 2 [略]
merge 函數的第一、二個參數是指定要合併的資料表,而 by 參數則是指定資料辨識的依據欄位。預設的狀況下,merge 會將有缺失值的資料忽略,所以上面這樣產生的資料並不會包含 Sample 為 4 的那一筆資料。我們可以將 all 參數設定為 TRUE(預設為 FALSE),讓含有缺失值的資料也一併被保留。
SquidMerged <- merge(Sq1, Sq2, by = "Sample", all = TRUE)
SquidMerged
輸出為:
Sample GSI YEAR MONTH Location Sex 1 1 10.4432 1 1 1 2 2 2 9.8331 1 1 3 2 3 3 9.7356 1 1 1 2 4 4 9.3107 NA NA NA NA 5 5 8.9926 1 1 1 2 6 6 8.7707 1 1 1 2 7 7 8.2576 1 1 1 2 [略]
第 4 筆資料的缺失值會以 NA 來表示。
R 匯出資料
R 所提供的 write.table 函數可以將 R 中的資料匯出至檔案,以 ASCII 的格式儲存,以利資料的交換或傳送。假設我們要將 Squid 的男性資料篩選出來,儲存成檔案,可以執行:
SquidM <- Squid[Squid$Sex == 1, ]
write.table(SquidM, file = "MaleSquid.txt", sep = " ", quote = FALSE, append = FALSE, na = "NA")
write.table 的第一個參數是指定要匯出的資料變數,file 參數是檔案名稱,sep 是指定欄位分隔字元(這裡是使用空白),quote = FALSE 是設定不要加入引號,na 則是指定缺失值的表示方法。如果要匯出的檔案已經存在時,加入 append = FALSE 可以把就的檔案內容直接覆蓋掉,如果將 append 指定為 TRUE,則會將資料附加在既有的檔案內容之後。
上面的指令執行之後,輸出的檔案內容為:
Sample Year Month Location Sex GSI 24 24 1 5 1 1 5.297 48 48 1 5 3 1 4.2968 58 58 1 6 1 1 3.5008 60 60 1 6 1 1 3.2487 61 61 1 6 1 1 3.2304 62 62 1 5 3 1 3.2263 63 63 1 6 1 1 3.1848 [略]
如果要讓資料可以直接給 Excel 讀取,可以使用逗號作為分隔字元來產生 CSV 檔:
write.table(SquidM, file = "MaleSquid.csv", sep = ",", quote = FALSE, append = FALSE, na = "NA")
quote 設定為 TRUE 可以讓欄位名稱與類別資料加上引號,有時候這樣可以避免特殊字元造成的解析錯誤。
write.table(SquidM, file = "MaleSquid.csv", sep = ",", quote = TRUE, append = FALSE, na = "NA")
加上 sep = "," 與 quote = TRUE 的檔案輸出內容會像這樣:
"Sample","Year","Month","Location","Sex","GSI" "24",24,1,5,1,1,5.297 "48",48,1,5,3,1,4.2968 "58",58,1,6,1,1,3.5008 "60",60,1,6,1,1,3.2487 "61",61,1,6,1,1,3.2304 "62",62,1,5,3,1,3.2263 "63",63,1,6,1,1,3.1848 [略]
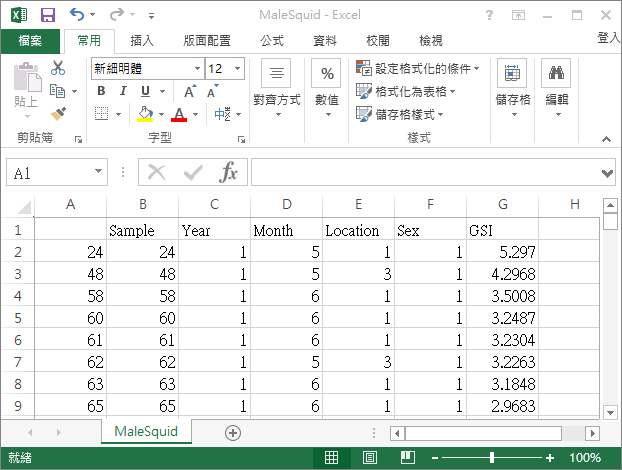
使用 write.table 所產生的 CSV 雖然可以用 Excel 直接開啟,不過在用 Excel 打開之後,第一列會少掉第一欄的名稱:
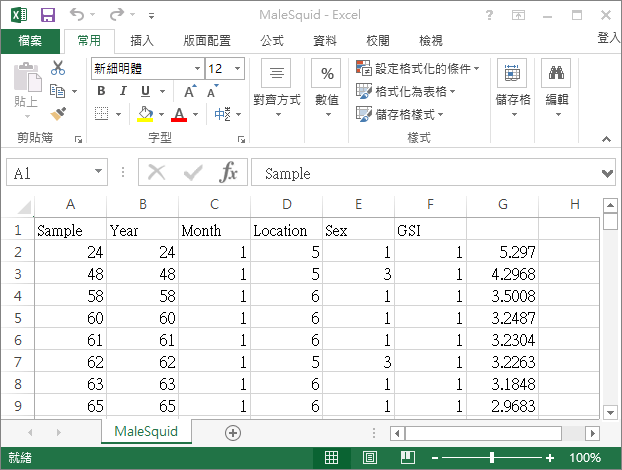
這裡我們需要自己手動將第一列的名稱往右移動一格,修正欄位名稱的對應,才會得到正確的表格。
Exercise 3
在 Exercise 2 中,我們已經將所有四月份且 SampleDepth 大於 2000 的資料篩選出來了,請繼續使用 write.table 函數,將這些檔案匯出至檔案中。
R 的類別資料
前面我們曾經使用 str 函數查看 Squid 的資料欄位資訊:
str(Squid)
'data.frame': 2644 obs. of 6 variables: $ Sample : int 1 2 3 4 5 6 7 8 9 10 ... $ Year : int 1 1 1 1 1 1 1 1 1 1 ... $ Month : int 1 1 1 1 1 1 1 1 1 2 ... $ Location: int 1 3 1 1 1 1 1 3 3 1 ... $ Sex : int 2 2 2 2 2 2 2 2 2 2 ... $ GSI : num 10.44 9.83 9.74 9.31 8.99 ...
其中 Location 是以 1、2、3 或 4 來表示,而 Sex 則是使用 1 與 2 來表示,這樣的資料都是屬於典型的類別資料,若是在 Excel 中,我們可以很容易地將 Sex 寫成 male 與 female,這樣可以更容易辨識資料所代表的意義,在 R 中也可以做類似的處理,將類些資料轉為類別性資料:
Squid$fLocation <- factor(Squid$Location)
Squid$fSex <- factor(Squid$Sex)
R 的 factor 是專門用來儲存類別性資料的一種變數型態,我們利用 factor 函數來將 Location 與 Sex 轉為 factor,儲存在新的資料表欄位中,我們可以看一下 fSex 這個 factor 的資料:
Squid$fSex
輸出為
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 [19] 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 [37] 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 [略] [2611] 1 2 1 1 2 1 1 2 1 2 2 1 1 1 1 1 1 1 [2629] 1 1 2 1 1 1 2 1 2 1 2 1 2 1 1 1 Levels: 1 2
最後一行的 Levels: 1 2 表示 fSex 有兩種類別,分別為 1 與 2,而 factor 內部的類別名稱是可以修改的:
Squid$fSex <- factor(Squid$Sex, levels = c(1, 2), labels = c("M", "F"))
Squid$fSex
輸出為:
[1] F F F F F F F F F F F F F F F F F F [19] F F F F F M F F F F F F F F F F F F [37] F F F F F F F F F F F M F F F F F F [略] [2611] M F M M F M M F M F F M M M M M M M [2629] M M F M M M F M F M F M F M M M Levels: M F
如此一來,所有的 1 就會以 M 表示,而 2 就會以 F 表示。
前面我們介紹過用簡單的判斷式篩選資料的方法:
SquidM <- Squid[Squid$Sex == 1, ]
而如果要使用 factor 的欄位進行篩選,輸入類別名稱時,記得要加上引號:
SquidM <- Squid[Squid$fSex == "M", ]
在 R 中的許多函數都可以直接讀取 factor 的資料,例如畫 box plot:
boxplot(GSI ~ fSex, data = Squid)
回歸分析也可以使用 factor 的變數:
M1 <- lm(GSI ~ fSex + fLocation, data = Squid)
summary(M1)
輸出為:
Call:
lm(formula = GSI ~ fSex + fLocation, data = Squid)
Residuals:
Min 1Q Median 3Q Max
-3.4137 -1.3195 -0.1593 1.2039 11.2159
Coefficients:
Estimate Std. Error t value
(Intercept) 1.35926 0.07068 19.230
fSexF 2.02481 0.09427 21.479
fLocation2 -1.85525 0.20027 -9.264
fLocation3 -0.14248 0.12657 -1.126
fLocation4 0.58756 0.34934 1.682
Pr(>|t|)
(Intercept) <2e-16 ***
fSexF <2e-16 ***
fLocation2 <2e-16 ***
fLocation3 0.2604
fLocation4 0.0927 .
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05
‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.415 on 2639 degrees of freedom
Multiple R-squared: 0.1759, Adjusted R-squared: 0.1746
F-statistic: 140.8 on 4 and 2639 DF, p-value: < 2.2e-16M2 <- lm(GSI ~ factor(Sex) + factor(Location), data = Squid)
summary(M2)
輸出為:
Call:
lm(formula = GSI ~ factor(Sex) + factor(Location), data = Squid)
Residuals:
Min 1Q Median 3Q Max
-3.4137 -1.3195 -0.1593 1.2039 11.2159
Coefficients:
Estimate Std. Error
(Intercept) 1.35926 0.07068
factor(Sex)2 2.02481 0.09427
factor(Location)2 -1.85525 0.20027
factor(Location)3 -0.14248 0.12657
factor(Location)4 0.58756 0.34934
t value Pr(>|t|)
(Intercept) 19.230 <2e-16 ***
factor(Sex)2 21.479 <2e-16 ***
factor(Location)2 -9.264 <2e-16 ***
factor(Location)3 -1.126 0.2604
factor(Location)4 1.682 0.0927 .
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05
‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.415 on 2639 degrees of freedom
Multiple R-squared: 0.1759, Adjusted R-squared: 0.1746
F-statistic: 140.8 on 4 and 2639 DF, p-value: < 2.2e-16除了 factor 函數之外,我們也可以使用 as.factor 這個函數將資料轉為 factor,而如果要將 factor 轉為數值,可以使用 as.numeric 函數,這個在畫圖的時候,要將不同類別的資料以不同顏色表示時,會很好用。
fLocation 的內容也是類似:
Squid$fLocation
輸出為
[1] 1 3 1 1 1 1 1 3 3 1 1 1 1 1 1 1 3 1 [19] 3 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 [37] 1 1 1 3 1 1 1 1 3 1 1 3 1 1 1 1 1 1 [略] [2611] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 [2629] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Levels: 1 2 3 4
fLocation 有四個 levels,順序是由小到大,許多繪圖函數在使用 factor 時,會受到這個順序的影響,例如 boxplot 畫出來的圖形就是依照這個順序來排列的,必要的時候我們可以自行指定這個順序:
Squid$fLocation <- factor(Squid$Location, levels = c(2, 3, 1, 4))
Squid$fLocation
輸出為:
[1] 1 3 1 1 1 1 1 3 3 1 1 1 1 1 1 1 3 1 [19] 3 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 [37] 1 1 1 3 1 1 1 1 3 1 1 3 1 1 1 1 1 1 [略] [2611] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 [2629] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Levels: 2 3 1 4
改變 levels 的順序並不會影響實際的資料,不過對於 boxplot 這類的繪圖函數就會有一些差別:
boxplot(GSI ~ fLocation, data = Squid)
這樣畫出來的圖就會依照我們指定的順序來排列。
Exercise 4
接續使用 Exercise 2 的資料,進行下列步驟:
- 將
Month與Year轉為 factor 後建立兩個新的欄位fMonth與fYear。 - 使用新的
fYear欄位篩選出 2002 年所有的資料。
總覽
下面這張表是本篇所介紹過的 R 函數總覽。
| 函數 | 說明 | 範例 |
|---|---|---|
write.table | 將資料匯出至 ASCII 檔案。 | write.table(MyTable, file = "output.txt") |
order | 計算資料的排序向量。 | order(x) |
merge | 合併兩個資料表。 | merge(x, y, by = "ID") |
attach | 將資料表內的變數加入搜尋路徑。 | attach(MyData) |
str | 顯示資料的內部結構。 | str(MyData) |
factor | 建立 factor 變數。 | factor(x) |