這裡討論在 Linux 系統上標準串流(standard streams)的緩衝區(buffering)時常容易會產生的一些問題。
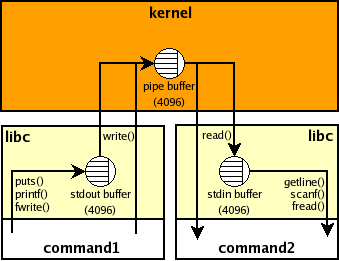
首先請看下面這個使用 pipeline 的指令:
command1 | command2
在這裡 shell 會 fork 兩個 processes,然後利用 pipe 連起來,整個架構中包含了三個緩衝區(buffer),就像這樣:
其中的 kernel buffer 會由 shell 所呼叫的 pipe system call 來建立,這個 buffer 的大小我們並沒有辦法直接控制,但基本上也不用擔心,因為 kernel 會在接到資料之後,立刻將資料送出去,通常效率都不是問題。(參考資料:circular pipes)
我們可以利用下面這個程式來測試預設的緩衝區,看看他們是如何運作的:
/* Output info about the default buffering parameters * applied by libc to stdin, stdout and stderr. * Note the info is sent to stderr, as redirecting it * makes no difference to its buffering parameters. */ #include <stdio_ext.h> #include <unistd.h> #include <stdlib.h> FILE* fileno2FILE(int fileno) { switch(fileno) { case 0: return stdin; case 1: return stdout; case 2: return stderr; default: return NULL; } } const char* fileno2name(int fileno) { switch(fileno) { case 0: return "stdin"; case 1: return "stdout"; case 2: return "stderr"; default: return NULL; } } int main(void) { if (isatty(0)) { fprintf(stderr,"Hit Ctrl-d to initialise stdin\n"); } else { fprintf(stderr,"Initialising stdin\n"); } char data[4096]; fread(data,sizeof(data),1,stdin); if (isatty(1)) { fprintf(stdout,"Initialising stdout\n"); } else { fprintf(stdout,"Initialising stdout\n"); fprintf(stderr,"Initialising stdout\n"); } fprintf(stderr,"Initialising stderr\n"); //redundant int i; for (i=0; i<3; i++) { fprintf(stderr,"%6s: tty=%d, lb=%d, size=%d\n", fileno2name(i), isatty(i), __flbf(fileno2FILE(i))?1:0, __fbufsize(fileno2FILE(i))); } return EXIT_SUCCESS; }
執行之後,輸出會類似這樣:
Hit Ctrl-d to initialise stdin
Initialising stdout
Initialising stderr
stdin: tty=1, lb=1, size=1024
stdout: tty=1, lb=1, size=1024
stderr: tty=1, lb=0, size=1
藉由測試的結果,在緩衝區模式的部分,我們可以得知:
而在緩衝區大小的部分:
以上這些數值只是一個測試出來的結果,並不是一個標準值,每個系統有可能不同,甚至同一種系統版本不同也會有差異,這裡只是提供一個概念性的介紹,讓大家了解系統上有這些緩衝區存在。
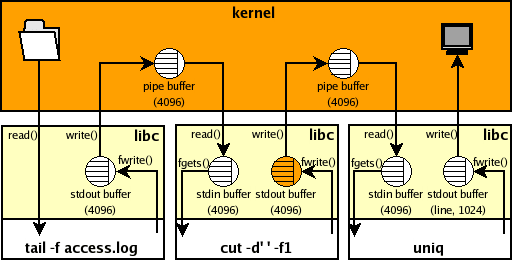
如果你想要查看 Apache 網頁伺服器及時的瀏覽記錄,看看有哪些訪客的 IP 位址,我們可以使用這樣的指令:
tail -f access.log | cut -d' ' -f1 | uniq
像這樣使用 tail -f 或 tcpdump -l 這類的指令,同時要持續等待新的資料,又要進行後續的資料處理時,就會發生輸出斷斷續續的問題。(某些會將所有資料都納入緩衝區的指令無法這樣使用,例如 sort)
在這個例子中,如果有新的訪客連線進來的時候,雖然其瀏覽記錄會被馬上寫入 access.log,但是由於 stdio 的緩衝區問題,他不會馬上顯示在這個指令的輸出中(被暫時儲存在緩衝區中),整個狀況會像這樣:
其中橘色的緩衝區就是出問題的地方,因為他所連接的另一端是一個 pipe,所以他的緩衝區大小會是 4096 bytes,他會等到緩衝區滿了之後,才會把資料送給 uniq。
另外 tail -f 的 stdout 緩衝區其實也會有這個問題,但是由於 tail 本身會在有新資料時呼叫 fflush(),讓資料及時送出,所以這個問題不嚴重。(你可以嘗試看看 tcpdump -l、grep --line-buffered 與 sed --unbuffered 這幾個指令的狀況)
在最後 uniq 輸出部分,由於它的 stdout 是直接連接終端機,所以只要有資料時,就會逐行立即自動輸出,所以對這裡的需求而言也沒有問題。
stdin 跟 stdout 類似,為了增進效率所以也有緩衝區的設置,當然你也可以透過一次只讀取一個 byte 的方式來控制整個讀取流程,但是這種做法並不實際。我們來看下面這個例子:
printf "one\ntwo\nthree\n" | ( sed 1q ; sed 1q ; sed 1q )
輸出為:
one
從輸出的內容你可以看出來,第一個 sed 把所有的資料都接收進去,剩餘兩個 sed 完全沒有收到任何資料。
縱使這裡將 stdin 的緩衝區模式設定為 line buffered,也是無效的,因為這個只會在 stdout 被 flushed 的時候有用。而常見的 readline 也都是實作在 stdin 的緩衝區上,所以同樣會有這個問題。
一般來說,你只能控制是否要從 stdin 讀取資料,如果你只要讀取指定長度的資料,那麼就必須將 stdin 的緩衝區關閉才行。
下面這個是另外一個 ssh 的例子:
printf "one\ntwo\nthree\n" | ( ssh localhost printf 'zero\\n' ; cat )
輸出為:
zero
這裡經過 ssh 連線所執行的 printf 並不需要任何輸入資料,但是 ssh 指令本身並不知道這件事,所以 ssh 還是會把資料讀進來。如果要讓 ssh 不要讀取任何資料,可以加上 -n 參數:
printf "one\ntwo\nthree\n" | ( ssh -n localhost printf 'zero\\n' ; cat )
這樣的話,輸出就變為:
zero
one
two
three
程式設計者可以直接使用 read 或 write 避開緩衝區的問題,但是在大部份的狀況下,這樣會比較沒有效率。另外一個方式是使用 setvbuf 函數來控制緩衝區的模式與大小:
#include <malloc.h> #include <stdio.h> #include <stdio_ext.h> int main(int argc, char** argv) { int buf, chars, i; fprintf(stderr,"BUFSIZ = %d\n",BUFSIZ); fprintf(stderr,"uninitialised stdout buf_size = %d\n",__fbufsize(stdout)); setvbuf(stdout, (char*)NULL, _IOFBF, 0); fprintf(stderr,"default stdout buf_size = %d\n",__fbufsize(stdout)); if (argc == 3) { buf=atoi(argv[1]); //chars to allocate chars=atoi(argv[2]); //chars to write to test buffering char* new_buf=malloc(buf); //can't free until fclose(stdout) if (setvbuf(stdout, new_buf, _IOFBF, buf)) { fprintf(stderr,"setvbuf() failed\n"); } fprintf(stderr,"specified buf_size = %d\n",__fbufsize(stdout)); if (chars) { for (i=1; i<chars; i++) putchar('.'); putchar('$'); putchar('.'); sleep(5); //to see buffering of output } } } /* Note currently for glibc (2.3.5) the following call does not change the the buffer size, and more problematically does not give any indication that the new size request was ignored: setvbuf(stdout,(char*)NULL,_IOFBF,8192); The ISO C99 standard section 7.19.5.6 on the setvbuf function says: ... If buf is not a null pointer, the array it points to may be used instead of a buffer allocated by the setvbuf function and the argument size specifies the size of the array; otherwise, size may determine the size of a buffer allocated by the setvbuf function. ... Andreas Schwab at least takes the above to mean setvbuf(....,size) is only a hint from the application which I don't agree with. FreeBSD's libc seems more sensible in this regard. From the man page: The size argument may be given as zero to obtain deferred optimal-size buffer allocation as usual. If it is not zero, then except for unbuffered files, the buf argument should point to a buffer at least size bytes long; this buffer will be used instead of the current buffer. (If the size argument is not zero but buf is NULL, a buffer of the given size will be allocated immediately, and released on close. This is an extension to ANSI C; portable code should use a size of 0 with any NULL buffer.) */
在更改串流緩衝區設定時,可能會有無法預期的結果,這個要注意,另外這個程式是在 glibc 2.3.5 的情況下實作的,版本有點舊,但是還有參考價值,如果自己要實作,就要注意新的 glibc 有沒有變動。
目前來說,對於既有的程式使用者是沒有辦法更改其緩衝區設定的,有一個 unbuffer 工具可以解決部分的問題(但是也產生了其他的問題),有興趣的人可以自行參考他的說明文件。
在新的 coreutils 7.5 中,提供了一個新的 stdbuf 指令,它可以讓你更容易來控制串流的緩衝區:
tail -f access.log | stdbuf -oL cut -d ' ' -f1 | uniq
詳細的使用方式,可以查詢 stdbuf 的線上手冊。
man stdbuf
參考資料:pixelbeat.org
{kind=link}
{kind=link}