這裡介紹如何使用 sort 指令排序文字資料,並提供一些常用的範例指令稿。
在 Linux 中的 sort 指令可以用來處理各種文字資料的排序問題,例如根據數值大小、月份等資料排序,反向或亂數排序等。以下是 sort 指令的使用教學與實用範例。
假設我們有一個文字檔案 linux.txt,內容如下:
TrueOS,919 Mint,2830 Debian,1677 Solus,1303 Ubuntu,1644 Antergos,1129 elementary,1089 Manjaro,2405 openSUSE,813 Fedora,963
sort 指令預設會根據英文字母的順序排序每一行資料:
sort linux.txt
Antergos,1129 Debian,1677 elementary,1089 Fedora,963 Manjaro,2405 Mint,2830 openSUSE,813 Solus,1303 TrueOS,919 Ubuntu,1644
sort 也可以從標準輸入接收資料:
cat linux.txt | sort
如果資料的開頭有包含空白,可以加上 -b 參數忽略空白。
若想要將排序結果儲存至檔案,可以使用 -o 參數指定輸出檔名:
sort -o output.txt linux.txt
假設 cap.txt 資料如下:
Orange app apple App Apple
若想讓 sort 在比較文字時,不分大小寫,可以加上 -f 參數,通常這個參數會跟 -u 參數一起使用,將重複出現的資料刪除,只留下一筆:
sort -fu cap.txt
app apple Orange
如果想讓 sort 以反向的方式排序,可以加上 -r 參數:
sort -r linux.txt
Ubuntu,1644 TrueOS,919 Solus,1303 openSUSE,813 Mint,2830 Manjaro,2405 Fedora,963 elementary,1089 Debian,1677 Antergos,1129
sort 預設是使用整行的文字來進行排序,如果每一行文字資料中,還有包含許多欄位的話(例如逗點分隔的 CSV 檔),我們也可以使用特定的欄位來作為排序的依據。
在指定欄位之前,我們必須先使用 -t 參數指定欄位的分隔字元(預設為空白或 tab),將欄位正確切開,接著以 -k 參數指定欄位的編號。以下我們以逗號分隔欄位,並使用第二欄數字的資料作為排序的依據:
sort -t, -k2,2 linux.txt
elementary,1089 Antergos,1129 Solus,1303 Ubuntu,1644 Debian,1677 Manjaro,2405 Mint,2830 openSUSE,813 TrueOS,919 Fedora,963
-k 參數在指定欄位時輸入的兩個數字代表「起始位置」與「結束位置」,而如果將結束位置省略的話,預設的結束位置就是整行的結尾。由於這個例子只有兩個欄位,所以我們也可以把結束位置省略,寫成這樣:
sort -t, -k2 linux.txt
不過 sort 在排序時,預設都是把資料當作文字來排序,所以上面的排序結果中,數字 1 開頭的會排在最前面,而數字 9 開頭的則會被放在最後。
如果想讓資料根據實際數值的大小來排序,可以加上 -n 參數:
sort -t, -k2 -n linux.txt
openSUSE,813 TrueOS,919 Fedora,963 elementary,1089 Antergos,1129 Solus,1303 Ubuntu,1644 Debian,1677 Manjaro,2405 Mint,2830
除了簡單的數字之外,我們也時常會使用各種單位來表示數值。假設 unit.txt 的
內容如下:
12M 344 98K 1G 34213 45K
若想要對這種含有單位的數值做排序,可以使用 -h 參數:
sort -h unit.txt
344 34213 45K 98K 12M 1G
若想要將資料打亂,以隨機的方式重新排序,可以加上 -R 參數:
sort -R linux.txt
Fedora,963 Mint,2830 Ubuntu,1644 elementary,1089 TrueOS,919 Solus,1303 Manjaro,2405 Antergos,1129 Debian,1677 openSUSE,813
不過 sort 加上 -R 參數進行隨機排序時,會自動將具有相同排序欄位值的資料放在一起。舉例來說,假設 dup.txt 文字檔的內容如下:
orange apple orange mango apple
像這種有重複出現的資料,若以 sort 進行隨機重新排序:
sort -R dup.txt
結果就會像這樣,相同的資料會被自動放在一起,而不同資料之間的順序才是隨機的:
mango orange orange apple apple
如果想要讓所有的資料都隨機重排,可以改用 shuf 指令:
shuf dup.txt
假設我們有一個 mon.txt 檔案,其內容是月份的資料:
Feb Aug May Sep Jan
若想依照月份排序,可以加上 -M 參數:
sort -M mon.txt
Jan Feb May Aug Sep
在非英文語系的系統上(例如中文語系),處理這種月份資料時,要把語言設定為英文的,才能正常運作:
LC_ALL=C sort -M mon.txt
在比較複雜的資料中,我們可能會需要依據多個欄位進行排序,此時可以使用多組 -k 參數指定欄位,並加上每個欄位值的解析方式。
解析方式的指定,就是使用前面介紹的各種參數,例如 n 代表依照數值大小排序,M 則代表依照月份排序等,放在 -k 參數位置的這些解析方式只會對該欄位有影響,不會影響到其他的欄位。
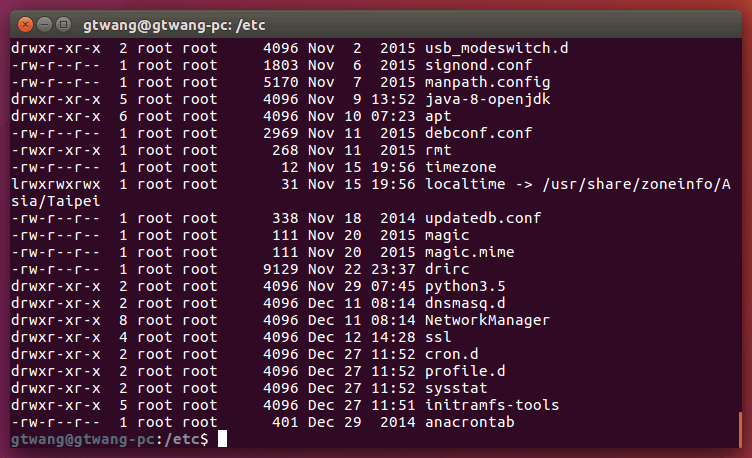
下面這個範例是將 ls -l 的輸出交給 sort,先使用月份進行排序,若月份相同,則依照日的數值:
export LC_ALL=C ls -l | sort -k6M,6 -k7n,7
結果會類似這樣:
這裡我們使用 LC_ALL 更改了語系的設定,若不想用 export 的方式,可以改成這樣(比較不會影響到其他的程式):
LC_ALL=C ls -l | LC_ALL=C sort -k6M,6 -k7n,7
這個例子只是用來示範 sort 多欄位的排序方法,如果真的要讓檔案依據時間排序,請使用:
ls -ltr
如果想要使用 sort 指令排序非常大量的資料,希望加速計算的速度的話,可以使用 --parallel 這個平行化運算功能,並指定行程數量:
# 平行排序巨量資料 sort --parallel=4 large.txt
這行指令可以列出目前系統上最耗 CPU 的 3 個行程:
# 列出目前最耗 CPU 的 3 個行程 ps aux | sort -nrk 3,3 | head -n 3 | nl
{kind=link}